



6.2.3 实现方法
1.段落和句子划分
对于段落的划分采取与提取材料相同的划分方式,即将回车符作为段落切分的标记;句子的划分则按照句号、问号、感叹号、逗号和冒号将句子隔开。
2.分词和词性标注
分词对中文来说难度较大,长期影响着分词的科学性。中文的特点有两个,一是中文是一个字符串,它不像西文,词与词之间用空格分开,计算机很易识别;二是中文的字词不分,如“走”,它是字同时也是词,即动词,语义分析分词是关键,是前提,要研究语义就得从分词做起。这里,我们对中国科学院计算所汉语词法分析系统ICTCLAS8进行了二次开发。ICTCLAS采用了基于层叠隐马模型的方法,旨在将汉语分词、切分排歧、未登录词识别、词性标注等词法分析任务融合到一个相对统一的理论模型中。首先,在预处理的阶段,采取N-最短路径粗分方法,快速地得到能覆盖歧义的最佳N个粗切分结果;随后,在粗分结果集上,采用底层隐马模型识别出普通无嵌套的人名、地名,并依次采取高层隐马模型识别出嵌套了人名、地名的复杂地名和机构名;然后将识别出的未登录词以科学计算出来的概率加入到基于类的切分隐马模型中,未登录词与歧义均不作为特例,与普通词一起参与各种候选结果的竞争。最后在全局最优的分词结果上进行词性的隐马标注。
所谓层叠隐马尔可夫模型(Cascaded Hidden Markov Model,CHMM)[20],实际上是若干个层次的简单HMM的组合,各层隐马尔可夫模型之间通过以下几种方式互相关联,形成一种紧密的耦合关系:各层HMM之间共享一个切分词图作为公共数据结构;每一层隐马尔可夫模型都采用N-Best策略,将产生的最好的若干个结果送到词图中供更高层次的模型使用;低层的HMM在向高层的HMM提供数据的同时,也为这些数据的参数估计提供支持。整个系统的时间复杂度与HMM相同,仍然是O(NT)。
该模型包含原子切分、普通未登录词识别、嵌套的复杂未登录词识别、基于类的隐马切分、词类标注共五个层面的隐马模型。其中,N2最短路径粗切分可以快速产生N个最好的粗切分结果,粗切分结果集能覆盖尽可能多的歧义。在整个词法分析架构中,二元切分词图是个关键的中间数据结构,它将未登录词识别、排歧、分词等过程有机地进行了融合。
对句子:
[周恩来表示:逼蒋或联蒋抗日是有道理的,抗战如果争取不到蒋介石集团参加是一大损失,但蒋的方针是西太后的“宁予外人,不给家奴”,坚持内战,人民惨遭涂炭,积怨甚大,不过为了抗日大计,可以不咎既往,与其团结。但更要斗争,不斗争,就会认为软弱可欺,联合也不可能。]
分词后的结果如下所示:
“周/nr 恩来/nr 表示/v :/w 逼/v 蒋/nr 或/c 联/vg蒋/nr 抗日/v 是/v 有/v 道理/n 的/u ,/w 抗战/v如果/c 争取/v 不/d 到/v 蒋/nr 介石/nr 集团/n 参加/v是/v 一/m 大/a 损失/n ,/w 但/c 蒋/nr 的/u 方针/n是/v 西/j 太后/n 的/u “/w 宁/dg 予/vg 外人/n ,/w不/d 给/p 家奴/n ”/c ,/w坚持/v 内战/n ,/w 人民/n惨遭/v 涂/v 炭/n ,/w积怨/n 甚/dg 大/a ,/w 不过/c为了/p 抗日/vn 大计/n ,/w 可以/v 不咎既往/i ,/w与其/c 团结/an 。/w 但/c 更/d 要/v 斗争/vn ,/w 不/d斗争/v ,/w 就/d 会/v 认为/v 软弱/a 可欺/v ,/w 联合/vd 也/d 不/d 可能/v 。/w”
3.语义谓词的选择
语义谓词从句子的动词中获取,并进一步与用户定义的语义谓词列表进行比对,如果存在于语义谓词列表中,则进入下一步,即提取与该语义谓词相对应的语义实体。这里,语义谓词列表由用户选择。在本系统中,我们引入了语义指数(Semantic Index)来衡量语义谓词的重要性,语义指数的定义公式为:
![]()
其中,fj为第j个语义谓词出现的频度,fIi为和语义谓词共同出现的第i类语义实体的频度之和,WI2为第i类语义实体的权重,并且满足
![]()
通过对语义谓词的频度和SI指数设置阈值,可以筛选出对用户较为重要的语义谓词,表6-1显示了部分语义谓词及其在国共合作第四篇中出现的频度和语义指数。第一列动词频度和SI指数都高于阈值,被加入语义谓词列表;第二列动词频度低于阈值,被排除;第三列动词SI指数低于阈值,被排除。
表6-1 部分语义谓词出现的频度与SI指数表
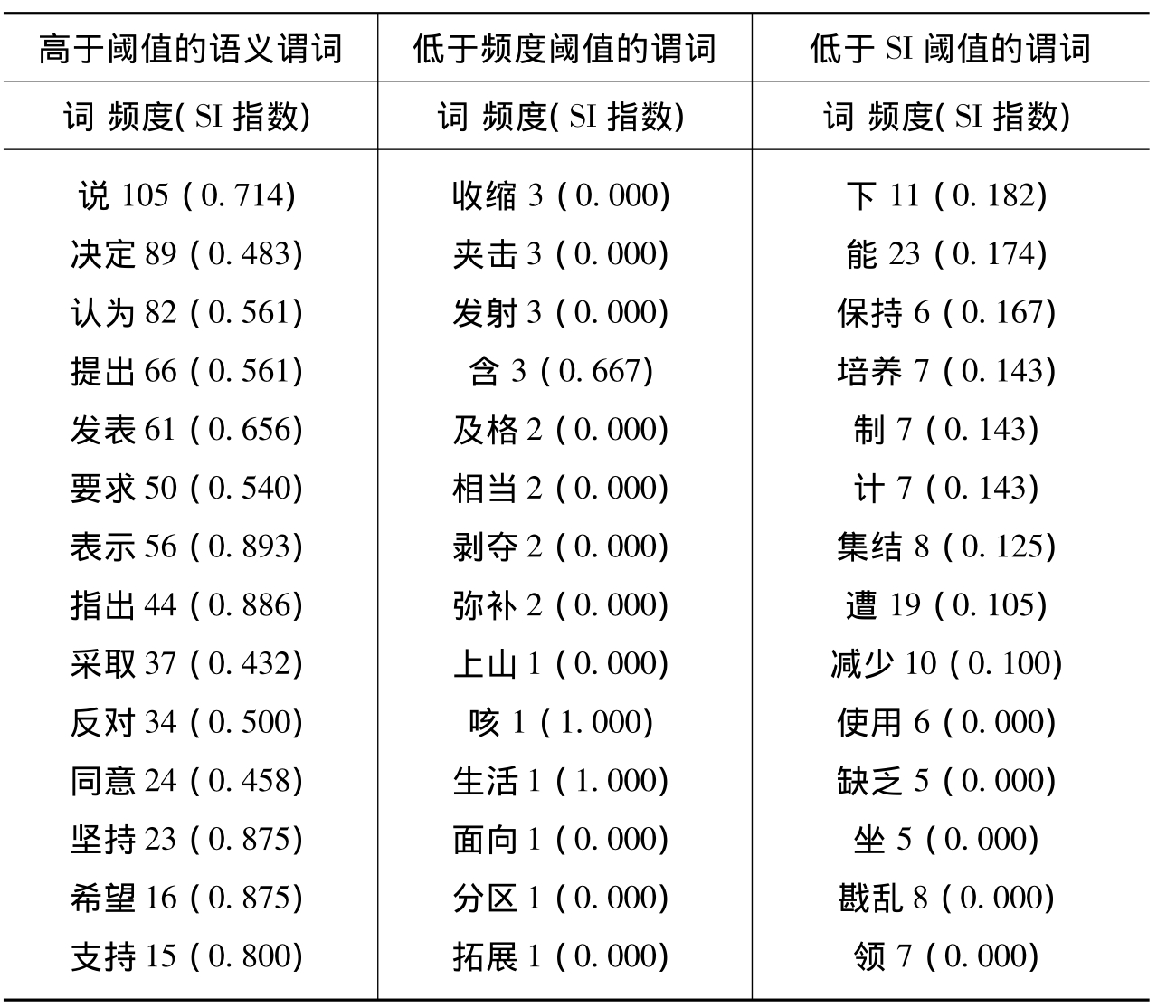
频度阈值取14,SI阈值取0.430
4.相关语义实体的提取
在语义谓词提取完毕之后,接下来提取与之相关的语义实体。我们将语义实体分为两类,即语义主体和语义客体,前者对应于三元组中的Subject,后者对应于三元组中的Object。语义主体可能包括有关名词和指示代词,将其统一化归到候选语义主体列表{can}中,给每一个候选语义主体打分,选择分值最高的候选词作为语义主体,分值的计算参照候选语义主体的特征进行统计,统计的特征值包括:
(1)pos表示候选语义主体在句子中的位置。
(2)sem表示候选语义主体所处的子句。
(3)sempos表示候选语义主体在子句中的位。
(4)av表示候选语义主体是否位于动词的后。
(5)ap表示候选语义主体是否位于介词的后。
(6)vpos表示语义谓词在句子中的位置。
(7)vsem表示语义谓词所处的子句。
(8)vsempos表示语义谓词在子句中的位置。
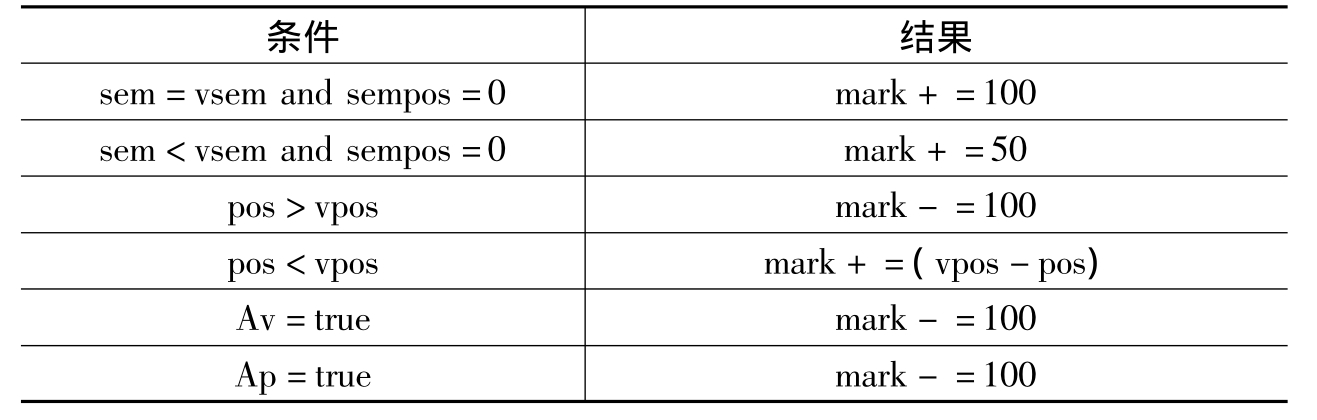
根据上述特征给候选语义主体进行评分,通过对反馈结果进行总结和评估,对评分算法进行了逐步调整,调整后的评分原则如表6-2所示。通过表6-2所示的规则,给每一个候选语义主体打分,选择分值最高的候选词作为语义主体,如果分数都小于零,则表示该语句缺省语义主体,将从上一句中继承语义主体,参照以下例句:
表6-2 语义主体提取规则列表
[曾养甫还作了10月底周恩来到广州的准备,并向张子华表示:如周恩来不去广州,国民党派人去陕面商谈判地点。]
在上述句子中,和语义谓词相关的候选语义主体有三项,{曾养甫、周恩来、张子华},通过计算,“曾养甫”的分值最高,因而被判定作为语义主体。
参照以下例句:
[在中共义正词严的批评与桂系强烈抵制下,蒋介石不得不于五届二中全会上明确表示不签订承认“伪国”的协定。]
在上述句子中,和语义谓词相关的候选语义主体有三项,{中共、桂系、蒋介石},通过计算,“蒋介石”的分值最高,因而被判定作为语义主体。
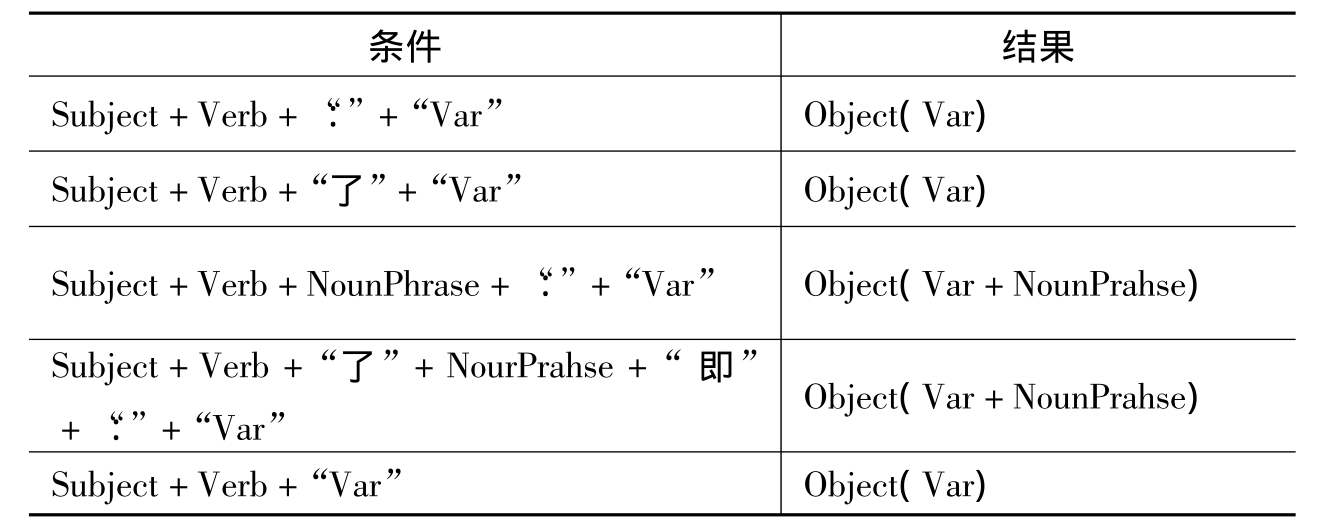
语义客体的提取也采取了基于规则的方式(参见表6-3)进行提取,参照以下例句:
表6-3 语义客体提取规则列表
[周恩来表示:逼蒋或联蒋抗日是有道理的,抗战如果争取不到蒋介石集团参加是一大损失,但蒋的方针是西太后的“宁予外人,不给家奴”,坚持内战,人民惨遭涂炭,积怨甚大,不过为了抗日大计,可以不咎既往,与其团结。但更要斗争,不斗争,就会认为软弱可欺,联合也不可能。]
在上述例句中,符合规则1的左半部分“Subject+Verb+‘:’+‘Var’”,因而语义客体的提取结果为“逼蒋或联蒋抗日是有道理的,抗战如果争取不到蒋介石集团参加是一大损失,但蒋的方针是西太后的‘宁予外人,不给家奴’,坚持内战,人民惨遭涂炭,积怨甚大,不过为了抗日大计,可以不咎既往,与其团结。但更要斗争,不斗争,就会认为软弱可欺,联合也不可能。”
(https://www.xing528.com)
5.代词消解与时间修订
所谓代词消解,指的是判断两个名词短语是否指代现实中的同一个实体。目前关于名词指代消解的方法大致可以分为两类,即机器学习方法和非机器学习方法,对于非机器学习方法,主要指通过设计一些启发式规则和过滤器来解决指代问题。比如,最直接的方法就是认为代词的前一个与其具有相同属性的名词或名词短语为其指代的实体。
要进行同指消解,首先必须解决从哪些名词中选择,也就是确定候选先行语集。理论上,所有位于照应语前面的名词短语都应该被认为是可能的先行语。但是,在实际应用中必须设定一个范围来查找先行语,在这个范围之外不予考虑。Hobbs[21]在它的研究报告中指明:在100个使用代词的例子中,有98%被指代的对象就和代词在同一个句子中或在前面紧挨着的句子中。因此,我们将思路局限在当前句和前面紧挨着的若干句子中寻找。这里,引入了Context变量,用于存取前面句子的语义主体,Context的定义结构如表6-4所示(其中,subject数组用于存取语义主体,timebase数组用于存储时间基点,location数组用于存储地点基点,event变量用于存储事件基点)。
表6-4 语义提取背景的结构表

对于以下例句:
[同时,蒋介石又以军事压迫和政治分化并用的方法对西北的抗日联合战线进行破坏。1937年1月他下令将杨虎城、于学忠两人撤职留任。1月20日又决定强迫东北军和十七路军分别调防,移驻甘肃和渭北,派顾祝同为军事委员会西安行营主任,调集37个师的兵力分五路向西安推进。]
系统能够将第二句中“1937年1月他下令”中的“他”判断为“蒋介石”。第三句缺省主语,将继承前一句的语义主体。
对于以下例句:
[2月18日,宋庆龄针对汪精卫提出以坚持“剿共”为中心内容的政治决议草案,在全会上发表了《实行孙中山的遗嘱》的演说。她指出:“令人万分遗憾的是,直到今天,政府中仍有个别人士不了解救国必先结束内战的道理。在今天居然还可以听到‘抗日必先剿共’的老调,这是多么荒谬!我们要先打断一只手臂之后再去抗日吗?我们已经有了十年的内战经验。在这期间,国力都耗费在内争上面,日本军阀将我们的土地一块块地割去,使我们的国家受到蹂躏。”她强调:“每一个中国爱国志士现在都庆幸政府在这些痛苦经验之后已开始了解,救国必须停止内战,而且必须运用包括共产党在内的全部力量,以保卫中国国家的完整。”]
系统能够判断出第二句和第三句的语义主体为“宋庆龄”。
另外,系统对时间的修订,利用了Context中的timebase变量,timebase是一个数组,它存储了最新的年、月以作为时间基线。在提取的过程中,如果时间的基线变化在定义的阈值之内,则更新时间基线。对于没有时间的句子,系统将选择从上一句继承时间基线。
对于以下例句:
[同时,蒋介石又以军事压迫和政治分化并用的方法对西北的抗日联合战线进行破坏。1937年1月他下令将杨虎城、于学忠两人撤职留任。1月20日又决定强迫东北军和十七路军分别调防,移驻甘肃和渭北,派顾祝同为军事委员会西安行营主任,调集37个师的兵力分五路向西安推进。]
系统能够将“1月20日”自动补全为“1937年1月20日”。
6.将结果存入语义数据库
对于前述的提取结果,接下来将结果存入系统中,这里应用了HP公司的Jena API接口,按照以下步骤进行:
(1)获取本体类,利用OntoModel中的getOntClass方法OntClass smallevent=ontoModel.getOntClass(″http:PP localhostPgghzOntProPowlPevent.owl#SmallEvent″);
(2)创建实例,利用ontoModel中的createIndi2vidual方法,ontoModel.createIn dividual(″http:PPlocalhostPgghzOntProPowlPevent. owl#test″+id,smallevent);
(3)获取实例的语义属性定义,这里的语义属性在第二章中已经通过Protégé工具创建,包括语义主体involvedRole、语义谓词mainAct、语义客体object、时间sTime、地点happenLoc等,利用了OntoModel中的getOntProperty方法。
Property p1=ontoModel.getOntProperty(″http://localhost/ gghzOntPro/owl/event.owl#abstract″);
Property p2=ontoModel.getOntProperty(″http://localhost/ gghzOntPro/owl/event.owl#object″);
Property p3=ontoModel.getOntProperty(″http://localhost/ gghzOntPro/owl/event.owl#relatedRole″);
Property p4=ontoModel.getOntProperty(″http://localhost/ gghzOntPro/owl/event.owl#mainAct″);
Property p5=ontoModel.getOntProperty(″http://localhost/ gghzOntPro/owl/event.owl#sTime″);
Property p6=ontoModel.getOntProperty(″http://localhost/ gghzOntPro/owl/event.owl#involvedRole″);
Property p7=ontoModel.getOntProperty(″http://localhost/ gghzOntPro/owl/event.owl#happenLoc″);
(4)获取实例的语义属性值,这里的语义属性值已经在前述三个步骤中获得,语义属性值分为两类,即Literal和Individual两种类型,前者可以直接生成,利用了Model中的createLiteral方法。后者则需要进一步查询原有语义库,利用了ontoModel中的getIndividual方法。
Literal Abstract=model.createLiteral(t.sourcetext);
Literal object=model.createLiteral(t4);
Literal mainAct=model.createLiteral(t2);
Literal happenTime=model.createLiteral(t.time);
Individual role=ontoModel.getIndividual(″http://localhost/ gghzOntPro/owl/indiviActor.owl#″+t.role);
Individual loc=ontoModel.getIndividual(″http://localhost/ gghzOntPro/owl/ndiviActor.owl#″+t.loc);
(5)将获取的语义属性值赋给语义实例,利用了Individual的addProperty方法。
in.addProperty(p1,Abstract);//p1 abstract
in.addProperty(p2,object);//p2 object
in.addProperty(p3,role);//p3 relatedRole
in.addProperty(p4,mainAct);//p4 mainAct
in.addProperty(p5,happenTime);//p5 sTime
in.addProperty(p6,role);//p6 involvedRole
in.addProperty(p7,location);//p7 happenLoc
7.将结果写入文件,利用了ontoModel的write方法。
File f=new File(″filepath\filename″);
OutputStreamWriter bfo=new OutputStreamWriter(new FileOutput Stream(f),″GB2312″);
ontoModel.write(bfo);
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。