



2.2 数据的存储
我们明白了数据的表示形式和编码的基本思想,接下来应该考虑数据是如何存储的。本节将讨论数据的存储,我们先看两个很重要的概念。
2.2.1 数据的两要素
C语言中,数据有两个非常重要的概念———值和地址。看似这两个概念很简单,但是它们是打开整个C语言神秘大门的神奇钥匙,很多重要的概念都和它们有着密切的联系。
(1)数据的值
数据的值描述了数据的基本属性,是数据本身的信息。计算机中任何的信息都要以值的形式而存在。比如一个数字、一部小说等,都要通过相应的编码方式,转化为特定的二进制流(“01”串),这就是值。
(2)数据的地址
数据的值总要存储在特定的地方,就好比茶水总要放在水杯之中一样。其实在计算机中,所有存储介质(比如内存和磁盘等)都是一个容器,而且是具有一定次序的阵列。为了简化描述,我们简单地认为都是顺序排列的,并且假定地址从0开始以字节为单位依次排列,如表2-2所示。
表2-2 数据的存储

这样一来,我们就可以给每一个数据对应一个地址。所谓地址,其实就是表示数据存放位置的一个数字。比如上图中的第二个数据“10100001”的地址为1。在实际系统中,并非如此简单,可能地址是一个很大的数字,一般我们用十六进制表示地址。至于用几位十六进制数字表示那就要看具体的系统了。
2.2.2 两个操作
知道了数据的值和地址,就可以对数据进行读取和写入操作了。实际上对计算机而言,对于数据也就只有读和写两种操作。
顾名思义,读取一个数据就是得到其值,不会对该数据做任何改变。写入数据就是将一个新的值放到该数据的存储空间中,覆盖其值。我们不难想象其过程为得到地址和操作数据。很简单,但意义深远。在后续章节中还会做进一步讨论。
现在完全可以思考这样的问题———如何获得地址?地址是如何表示的?值是如何显示的?如何写入到指定地址的存储空间中去?
2.2.3 数据类型
数据的含义千差万别,其存储大小也将有很大的不同,比如一个整数和一个小数,其存储肯定是不同的,不管是内部的编码,还是外在的存储空间大小都将会有很大的不同。
从现实世界的观念来看计算机世界,也需要我们对数据进行分类。唯有进行合理的分类,才能很好地管理数据,同时也能有效地提高数据的运算效率和数据的存储能力,这就是数据类型的重要意义。
C语言给我们提供了很全面的数据类型,从整体上来看,可以分为基本数据类型、复合数据类型和指针类型。基本数据类型是C语言提供的最基本类型,是所有类型(复合数据类型和指针类型)的基础,可以说不管C语言提供多么强大的数据类型,都不能超出基本数据类型描述的蓝图。换句话说,基本数据类型必将限制全部的数据类型,在学习时一定要注意这一点,即便是后面将要讨论的结构体、共用体等自定义的复合数据类型也不能超出这个限制。
1.基本数据类型
C语言提供了三种基本数据类型:整型、浮点型和字符型。
(1)整型
在计算机中最常用同时也是最简单的数据类型是整型。
整型就是不含小数部分的数值,包括正整数、负整数和0。在C语言中用关键字int表示。
计算机中的整数与数学意义上的整数有很大的区别。数学上的整数可从负无穷大到正无穷大,而计算机中的整数类型有多种,并且值都是有范围的。整型按照表示长度有8、16、32位之分。具体如表2-3所示。
表2-3 整型按照长度分类表
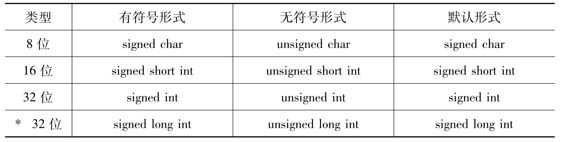
有了类型和符号形式,就可以得到表示范围,一般的,我们有公式:
有符号形式:L=-2n-1,U=2n-1-1
无符号形式:L=0,U=2n-1
其中,L表示范围的下限,即整型数据可以表示的最小数值;U表示范围的上限,即整型数据可以表示的最大数值;n表示类型,即位长。例如,short int,即默认的signed short int,其表示的数据范围为:-215~215-1,即-32768~32767。
(2)浮点型
浮点数也称为实数型,共有两种表示形式:小数表示法和指数表示法。在C语言中用关键字float和double表示。
①小数表示法
使用这种表示形式时,实型常量分为整数部分和小数部分。其中的一部分可在实际使用时省略,如10.2,.2,2.等。但整数和小数部分不能同时省略。
②指数表示法
指数表示法也称科学记数法,指数部分以E或e开始,而且必须是整数。如果浮点数采用指数表示法,则E或e的两边都至少要有一位数。如以下数是合法的:1.2e20,-3.4e-2。
浮点数在计算机中同样也必须要用二进制表示,分两部分:整数部分和小数部分。整数部分的转化采用“除2取余法”,小数部分采用和整数部分相反的方法进行,即“乘2取整法”,这里不再详细讨论。
(3)字符型
字符型在C语言中用关键字char表示,有两种表示方法:
①用一对单引号括起来的图形符号。
②用一对单引号括起来的以反斜杠开头的ASCII码值或者特定符号。比如ˊ\nˊ和ˊ\007ˊ。
这里要特别交代一下ASCII和转义字符。ASCII有128个字符,其中ASCII值从0~31和127为不可见字符,也就是控制字符。那么仅仅如此还不足以体现字符型的个性所在,在C语言中,允许用一种特殊形式的字符常量,以“\”开头的格式字符,这就是所谓的转义字符。表2-4列出了C语言中的转义字符的所有形式。
表2-4 转义字符
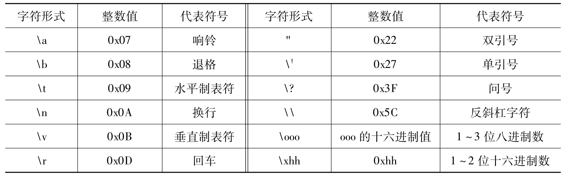
字符型变量分为一般字符型(char)和无符号字符型(unsigned char)两种。可以看出,字符型完全是为ASCII字符而生的,从而建立了与整型的密切联系,在表示方法和操作上都与整数吻合,但两者毕竟不同,最大的区别就在于输出方式上。
2.复合数据类型
基本数据类型勾画出了数据类型的雏形,而且限定了数据类型的表现形式和范围。但是在实际应用中我们发现基本数据类型根本不能满足或者不能很好地满足任务需求。C语言提供了四种复合数据类型———枚举、数组、结构体和共用体。它们都是对基本数据类型的变形和扩充,具有更好的功能和性能。
(1)枚举
枚举从本质上讲是整型的一个真子集。枚举类型定义的一般形式为:
enum枚举名{枚举值表};
在枚举值表中应罗列出所有可用值,这些值也称为枚举元素。
对于枚举而言,主要是定义了一种具有特殊明确意义的整型类型的新型数据类型,是实现了数字符号化,即可以使用具有贴切含义的文字描述特定的值。比如可以使用Man和Woman分别描述数值0和1等。一般而言有两个目的:一是增强可读性,二是增加安全性。例如有如下定义:
enum Sex{Man,Woman};
这就定义了一个新的类型Sex(严格来讲应该叫做enum Sex),从此有了两个变化,一个是多了一个类型,另一个是多了一种0和1的表示方法。
该枚举名为Sex,枚举值共有两个,即性别男和女。凡被说明为Sex类型变量的取值只能是两者中的某一个。如果不是,则会产生编译错误,这样就增强了数据的安全性。
枚举类型在使用中有以下规定:
①枚举值是常量,不是变量。不能在程序中用赋值语句再对它赋值。
例如对枚举Sex的元素再进行以下赋值:
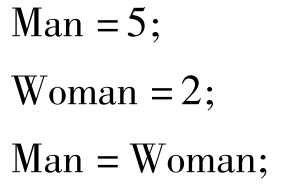
都是错误的。
②枚举元素本身由系统定义了一个默认的值,从0开始顺序定义为0,1,2…如在Sex中,Man值为0,Woman值为1。如果想更改值,可以在其后直接赋值。例如:
enum Sex{Man=1,Woman};
指定Man的值为1,Woman为2。注意Woman是自然增1。
又比如:
enum Sex{Man=1,Woman=3};
则Man的值为1,Woman为3。(https://www.xing528.com)
(2)数组
C语言中提供数组的概念,是为了方便管理同一种数据类型的大量关系密切的数据。比如我们现在要对任意输入的10个整数进行排序输出,可以想象如何进行呢?
这个问题我们不妨先放在这里,下面来看一个小区改造的例子。
这是来自乌托邦的乌托社区。这里有很多业主,每一个业主可以享受很多的特权,比如可以在社区内的任何地方、任何方向建造自己的家园,但是也有一个规定,所有的户型和面积都必须统一。好了,大家可以想象一下目前社区的布局吧!如果你进入这个社区会有什么感觉呢!
错落有致的雅舍,个个极其相似,南北东西难以辨认,如坠迷宫,如果你想找到某一人家的话,必定是困难重重,因为你根本无法描述你的目的地。没有任何次序,即便是有对方的家园标识,谁能够告诉你具体的位置呢?即便找到物业服务部门,按照你提供的标识,可以得到其地址,但是问题是如此错落有致(也可以称为“杂乱”)的社区中,如何寻找?
突然有一天,乌托邦政府颁布了一条改造社区的法令,要求全部的家园必须按照严格的次序建造,并且给每一个家庭都统一编上号码,这些号码和建造的次序完全一致。好了,这样的话,你再次来到社区,又会是怎样的感觉呢?
你可以很轻松地踏遍整个社区,而且可以很容易地找到想拜访的人家。整个社区的管理部门也省了很多的麻烦,大大地方便了管理。
其实,在C语言中,就有这样的改造过程,这就是数组。C语言中可以在一片连续的存储单元中依次存放相同类型的数据,以首地址为标识,用下标来表示里面全部的数据,这样就可以通过地址(第一个数据的地址)和数字(相应数据的地址与第一个数据的偏移量)来确定数据了。一般的,在C语言中,可以通过如下形式来定义一个数组:
数据类型数组名称[<常量表达式>][<常量表达式>]…[<常量表达式>];
其中,常量表达式表示数组的元素个数,一般的为整数常量。如果只有一个[<常量表达式>]就为一维数组,如果有两个[<常量表达式>]就为二维数组,以此类推可以得到多维数组。这一点在后面还会进一步讨论。
例如:
int aiT1[4];
定义了一个包含4个整型元素的一维数组;
int aiT2[3][4];
定义了一个包含12个整型元素的二维数组。
这里涉及一个如何看待二维数组的问题,实际上二维数组也是一个一维数组,只是其中的元素又是一个一维数组,也可以说是数组的嵌套。比如这里的二维数组aiT2,包含着三个元素,而每一个元素又是长度为4的一维整型数组,它们的名称为aiT2[0]、aiT2[1]、aiT2[2]。具体如图2-1所示。
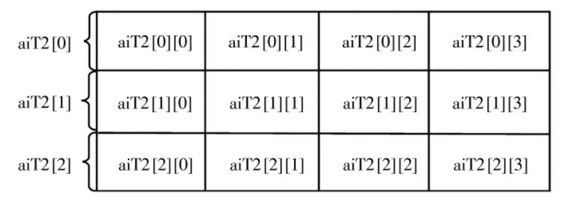
图2-1 二维数组的示意图
由于aiT2[0]是一个数组,所以由一维数组的引用法则(数组名[下标])自然的有aiT2[0][0]、aiT2[0][1]等。
由此不难得出三维数组以及更高维数组的实质,所以最终任何数组都可以转化为一维数组。明白了这个道理,任何复杂的数组我们都不怕了,只是下标稍微复杂一些而已。不过千万不要误认为图2-1是表状结构(二维结构)的存储,实际上是以线性结构(线状结构)连续存储的。比如aiT2[0][3]和aiT2[1][0]是亲密无间的。
最后我们探讨维数问题,到底最左边是第一维,还是最右边是第一维呢?从上面的推论过程可以看出,最左边是第一维。这个没有什么本质区别,但是为了避免混淆,还是在这里说明一下。
(3)结构体
通过上述讨论,已经看到C语言数据类型的丰富多样性,但是对于下面的问题,我们仍然感到捉襟见肘。
还从乌托社区说起,乌托社区的管理得到了广泛的关注,为了更好地建设优质社区,物业管理部门准备为每一位业主建立一份详细的档案,里面包括业主的姓名、联系方式、家庭编号和家属成员基本信息等等。如何才能很好地描述这个问题呢?
你可能马上会想到数组,不错,这是一个很好的提议。假定乌托社区有100位业主,可能你会这样处理:为姓名、联系方式、家庭编号和家属成员基本信息等分别建立长度为100的数组,然后通过下标来取得对应关系,比如第1位业主的信息可以通过下标0来分别取得。
问题似乎解决了,可是我们肯定会感到十分麻烦。因为想要取得某一位业主的信息,需要操作这么多数组,而且他们的联系似乎不很密切。明明是很密切的关系(因为是一个业主),为什么要强行分开呢?可是不分开又能如何呢?对于同一个业主的信息,我们是通过不同的数据类型进行描述的,比如姓名是字符型的,联系方式假定是电话号码的话可以用整型表示,家庭编号可以用枚举表示,诸如此类。数组必须是相同的类型,所以不得不进行分割。这必然造成数据的混乱局面。
假定我们可以引入一种新的记录单元完整描述一位业主的信息。换句话说,用一种统一的结构完整描述业主的信息,然后做一百份记录,就可以详细登记所有业主的信息了,甚至可以想象,用数组对其管理,更能够有效地完成这项工作了。为此,C语言引入了结构体的概念。实际上,结构体就是用户自定义类型,完全可以将它当做一个和整型同样友好的类型来看待,只是她更人性化和自由化,也更加的复杂和强大。注意,这里是新的整体,不是简单的相加。这样就很好地描述了本来关系就很密切的逻辑单元(业主信息)。
C语言这样定义结构体:
struct结构体名称
{
数据类型成员1名称;
数据类型成员2名称;
……
数据类型成员n名称;
};
这样,一个新的数据类型就诞生了,它的名字就叫“结构体名称”,从此系统将增加一个新的数据类型,就和int等基本类型一样。关于结构体的详细讨论,我们在后续章节继续。
(4)共用体
有时需要使几个不同类型的变量存放到同一段内存单元中,也就是使用覆盖技术,几个变量互相覆盖。这种若干不同的变量共同占用一段内存的结构,在C语言中,被称做“共用体”类型结构,简称共用体。
一般定义形式如下:
union共用体名
{
数据类型成员1名称;
数据类型成员2名称;
……
数据类型成员n名称;
};
在使用共用体的时候需要注意几个问题:
①同一个内存段可以用来存放几种不同类型的成员,但是在每一瞬间只能存放其中的一种,而不是同时存放几种。换句话说,每一瞬间只有一个成员起作用,其他的成员不起作用。
②共用体变量中起作用的成员是最后一次存放的成员,在存入一个新成员后,原有成员就失去作用。
③共用体变量的地址和它的各成员的地址都是同一地址。
④不能对共用体变量名赋值,也不能企图引用变量名来得到一个值,可以对共用体变量初始化,但初始化表中只能有一个常量。
⑤不能把共用体变量作为函数参数,也不能作为函数的返回值,但可以使用指向共用体变量的指针。
⑥共用体类型可以出现在结构体类型的定义中,也可以定义共用体数组。反之,结构体也可以出现在共用体类型的定义中,数组也可以作为共用体的成员。
3.指针
到目前为止,我们学习了C语言的基本数据类型和复合数据类型,应该说是学习了全部的数据类型。但是,C语言提供了指针的机制,可以说在C语言中,每一种数据类型都有相应的指针类型。
指针完全可以用地址进行解释。在C语言中,指针就是地址,在2.2.1节中,我们详细讨论了地址的概念,如果对此有了一定的了解,那么,指针就变得很容易了。通过指针可以直接操作变量的地址,这样可以极大地提高C语言的能力和性能,大大地方便C语言工作者的工作。然而万事万物都是两面性的,指针的使用也为C语言程序带来了不少的隐患。但是使用指针仍是利大于弊,可以说如果学习C语言没有很好地掌握指针的话,就不能说是掌握了C语言。一般的,我们这样定义指针:
数据类型*变量名称;
关于指针将在第六章做专门的讨论。
4.给类型起一个别名
C语言允许给类型起一个别名,这是通过关键字typedef实现的。typedef声明有助于创建平台无关类型,甚至能隐藏复杂和难以理解的语法。注意,仅仅是起一个别名而已,并不是创建崭新的类型。
一般的有:
typedef标准的数据类型信息和新的数据类型信息的融合;
对于后面的描述,大家可能觉得太冗长了些。其实这种描述更精确一些。一般情况下,从外表来看好像为一个普通的变量定义一样,只是这里的变量名往往成了数据类型的别名。例如:
typedef int integer;
就为整型起了一个别名———integer,这样就可以为那些习惯了integer的人提供很好的支持和帮助。由此我们可以体会到在第一章中提到C语言有良好的可移植性的缘由了。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。