



基于终端的回路数据实验
研究方法
在华数的应用层分离结构中,基于终端的测量技术主要集中于解决数字电视频道的收视率测量。由于收视率数据体量较大——平均每户每天频道切换数量超过130次(停留时间4秒以上统计数据)[3],每天数据量达5.5Kb[4]。与此同时,由于涉及机顶盒升级问题,而升级量又受到系统稳定性和安全性的掣肘,因此本次实验采用抽样方法进行,以降低数据采集、传输和运算的压力,同时选择更大样本以支撑实验的精度。
一、样本量的确定。设置信度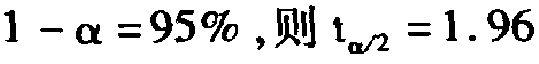 ,取最大允许绝对误差△p=1%,利用公式
,取最大允许绝对误差△p=1%,利用公式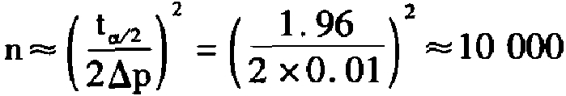 ,因此在本次实验中抽取10000户样本户。相对于传统收视率测量公司在杭州地区的样本数量300户,此次实验的样本量约为其33倍,高出近两个数量级,因此在下文描述中将此种数量级的样本称为“海量样本”。
,因此在本次实验中抽取10000户样本户。相对于传统收视率测量公司在杭州地区的样本数量300户,此次实验的样本量约为其33倍,高出近两个数量级,因此在下文描述中将此种数量级的样本称为“海量样本”。
二、抽样与配额。本次实验采用定向升级用户终端的方式确定样本户,其操作流程为随机抽样—定向升级—确定固定样组—稳定回收数据。
首先,在华数的配合下,根据运营商提供的网内用户登记信息,对用户的地理分布和终端类型进行排序,形成抽样框,共覆盖数字电视用户120万,采用等距抽样得到30000用户作为升级对象。
2007年8月至12月,在杭州地区对选定的30000户用户进行了定向升级,升级包下发后,至2008年1月升级包停止下发,升级成功、能稳定回收数据的机顶盒达到15 487个。在能够稳定回传数据的机顶盒中,我们提取了地理分布信息,以杭州地区有线数字电视用户的住址为字段排序进行等距抽样,成功获取9 376有效样本,然后通过配额补齐剩下的624户缺失样本,形成10000户在区域分布和机顶盒类型上与杭州地区数字电视用户分布情况基本一致的固定样组。采用配额的方法补充样本户实际上是在系统压力和升级复杂度方面做出的一种妥协。虽然艾尔·巴比指出,“近年来,不少研究者试着将概率抽样方法与配额抽样方法结合,但是其效果还有待观察”[5],但是为了使实验能够按照预先的设想顺利实施,我们最终选择了概率抽样和配额结合的方法。
三、测量精度设定。通过系统压力测试,实验最终将测量精度定为精确到秒,因为涉及收视测量的有效性问题,设定规则为≥3秒的数据为有效数据,低于3秒的数据将被直接抛弃。同时,由于机顶盒存在系统对时的问题,对时前的数据将缺失时间字段,需要依靠分析系统进行逻辑判断而补齐数据。由于基于终端的测量方法与频率电平的测量仪不同,无法记录电平状况,因此设置了重复记录的机制,如果每频道5分钟未有操作,即重复记录上一次的操作状态。
四、分析工具。由于回收数据量庞大,传统的分析工具在某些数据的分析上无法支撑如此规模的数据量,因此本实验采用了CCData公司的Rating Viewer[6]系统与SPSS相结合的分析工具。
数据回收情况
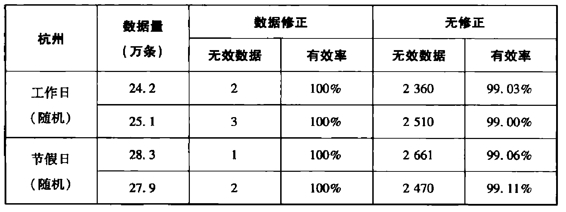
2008年1月开始,系统稳定运行。至2010年1月,共回收有效收视数据547 500000条,系统测量数据的平均错误率小于0.95%,无效数据的主要问题集中在机顶盒ID的获取和时间序列的逻辑问题上。因此在本实验中设计了无效数据的修复程序,通过修复使数据的错误率大幅降低,有效率达到100%。
表14 杭州终端回路数据的有效性
终端回路数据的实验结果
经过两年的稳定运行,终端回路数据系统获取了大量的杭州数字电视用户收视行为数据。本书试图通过整理和分析这些数据,验证回路数据的可操作性和先进性。同时,即使基于抽样的研究,由于采用了10000的海量样本,因此研究所得的数据量远远超过了传统社会研究和传播研究的数据量。在这种情况下,为了使一些研究能够顺利完成,本书在数据运算的时间维度上采用了灵活的方式,在满足研究目的的情况下尽量缩短纳入运算系统的数据时间周期,同时在系统允许的情况下,尽量选取新近的数据进行分析,以保证数据和分析结果的实效性。
样本量对测量数据影响的检验
如前文所述,在收视率研究中,样本规模一直是广受诟病的问题。传统研究中对于样本规模对收视率的影响的争议主要集中于理论的数学运算和分析的层面,因为收视率测量的巨大成本投入往往使科研机构无力承受对收视率和样本规模的研究。但对于测量公司来说,这种研究又无法解决在传统技术下收视率成本与精度的博弈问题,因此这项研究在国内外并无进展。本次实验要解决的问题之一,是样本量规模的扩大与收视率数据的质量和稳定性之间的关系问题,因此设计了三个收视率样本的对照组,样本数量分别为10000户、3000户和300户。
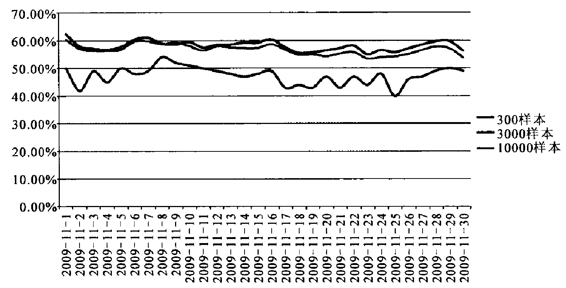
图8 不同样本量下开机率(HUT)情况(2009年11月)
我们首先对不同样本组的开机率测量数据进行对比研究。在同样的测量条件下,3000样本和10000样本的开机率数据表现基本相似,11月的开机率曲线基本呈现吻合状态,而300样本的开机率数据相对偏差比较大。
计算3000样本与10000样本的开机率数据的相关系数:
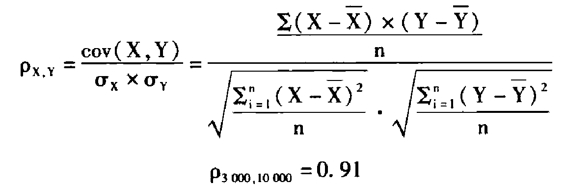
再以10000样本的数据为基准,计算300样本与10000样本的开机率数据的相关系数:
p3000.10000=0.57
从两组相关系数数值上看,300样本开机率曲线同10000样本的相关系数要远远小于3000样本同10000样本的相关系数。从均值上看,10000样本的11月平均开机率为56.6%,3000样本的11月平均开机率为58.1%,300样本的11月平均开机率为47.4%。可以看出,在同等实验环境下,根据统计推算以10000样本为基准,样本量越小,稳定性和相关性越差。在开机率指标上,不同样本量的数据表现已经有了明显的分野,在最常用也最为敏感的收视率指标上,几组对照数据的差异更加明显。
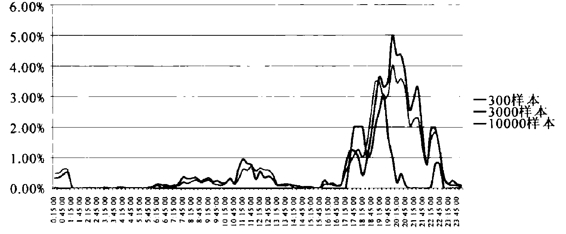
图9 浙江民生休闲频道不同样本量收视率对比(2010年1月4日)
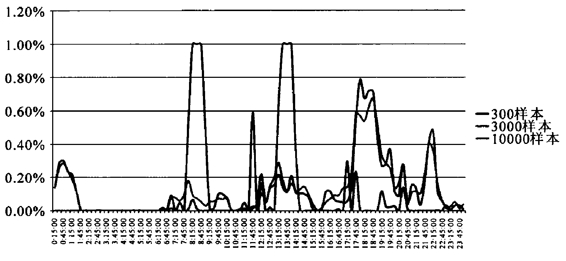
图10 浙江移动频道不同样本量收视率对比(2010年1月4日)
为了研究收视率数据在不同样本量下的数据表现,本实验分析选取了两个收视表现不同的频道:一个是杭州地区收视表现非常好的浙江民生休闲频道,另一个是相对表现较弱势的浙江移动频道,希望通过不同收视表现下不同样本量数据的比较,探求样本规模与收视率数据之间的影响关系。
首先看浙江民生休闲频道在不同样本量下的收视率表现。总体上看,3000样本和10000样本在收视率表现上比较一致,整体趋势明显一致,300样本的数据则显示出比较大的波动性。300样本数据相对于其他两组数据,表现出的主要特点有二:一是零收视率的概率非常高,二是数据异常波动较大。从图9中可以看出,300样本的数据在0∶00—17∶00之间出现了大量的零收视率点,而相对来说3000样本和10000样本的数据就能够较为明确地体现出早高峰和午间高峰的常识性收视规律。在高峰时段,300样本出现了两处和另外两组数据截然相反的数据表现,即17:30—18∶00的数据异常升高,20∶00—22:15的数据异常降低,而其他两组数据则表现出较为一致的曲线。
再看相对收视表现弱势的浙江移动频道的3组数据。零收视率表现上,随着样本量的提升明显下降,300样本的数据表现出明显的离散特征,其全天的收视率曲线除几个特殊时段外,基本收视率为零。相对来说,3000样本和10000样本的零收视点比较少,尤其是10000样本,在6∶30以后极少出现零收视率的数据。反观300样本的非零数据,其收视率数值在比较图中显得异常突兀,其中重要的原因就是样本量偏小,导致个体权重过大,一旦有样本户落在区间内,便极易导致数据异常升高。
回路数据与传统测量仪数据的对比
由于回路数据目前采取户为单位的测量结构,因此测量指标体系以“户”为基本单位。但是,在传统测量仪数据体系中,测量指标是以“个人”为单位的,因此在进行两种测量方法的比较中,最好是向某一个标准统一。由于本实验未涉及有关人的技术解决内容,同时目前的传统测量公司也不提供以家庭为单位的数据,因此在回路数据与传统测量数据的比较中,采用了户收视率和人收视率并行的形式。这种方法虽然无法直接比较数值之间的数量关系,但是在趋势等方面还是能够反映出两种测量方法之间的诸多差别。在进行比较前,首先通过收视率的计算公式,研究户收视率和人收视率的数学关系。
假设在某一测量体系下,户收视率为R户,人收视率为R人。
收视户数为n,平均每户收视人数为a;
样本户数为N,平均每户人数为A,样本人数为AN
人均收视时长为t1,户均收视时长为t2,时段总长为T。
根据收视率计算公式得到:
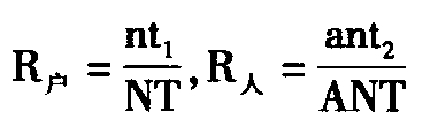
比较二者大小关系,(https://www.xing528.com)
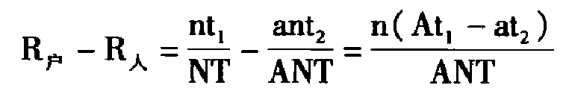
在实际情况下,平均每户人数一定大于或等于平均每户收视人数,即A≥a;同时人均收视时长大于户均收视时长,即t1 ≥ t2。因此R户-R人≥0,即
R户≥R人
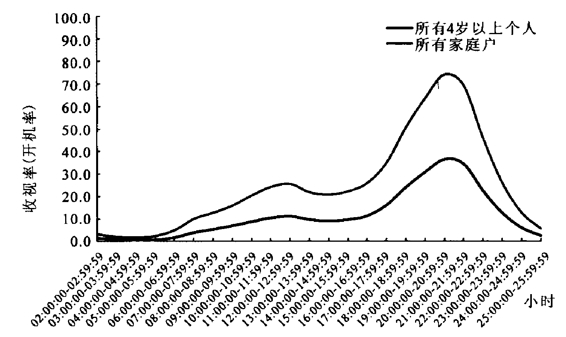
图11 2008年杭州地区户收视率与人收视率对比关系
根据2008年AGB尼尔森的杭州地区测量仪收视数据,全年平均到户开机与人开机率的比例范围在(2.0,3.1)之间(对比时间范围60分钟)。
因此可以得出结论:在同样的测试环境下,户收视率应该大于或等于人收视率,二者之间的数学关系如公式所示。以下进行回路数据与测量仪数据的对比。
首先,回路数据与测量仪数据收视份额比较。通过对回路数据和测量仪数据2009年12月1日—31日的平均收视份额进行比较,可以发现在这个指标上回路数据与测量仪数据表现截然不同:在测量仪数据中,杭州地区的省级频道占据绝对优势,平均份额接近一半,达45%;在回路数据中,央视、省级频道、市级频道和卫视的份额基本呈现均匀分布的状态,其中央视的份额最大,达31%,是测量仪数据中央视份额(16.9%)的近一倍。
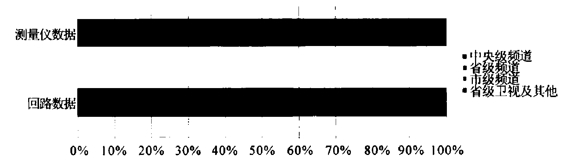
图12 回路数据与测量仪数据对比
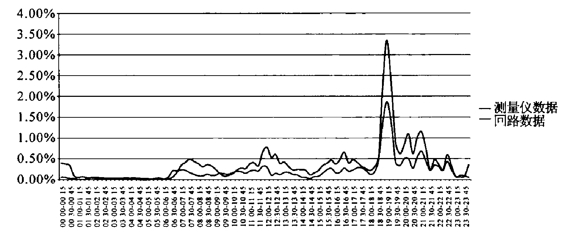
图13 2009年12月 回路数据与测量仪数据收视率对比(央视一套)
其次,回路数据与测量仪数据收视率比较。在收视率的对比实验中,选取了央视一套、杭州一套和北京卫视作为具有典型特征的频道进行两种测量方法的数据比较。其中央视一套作为中央级频道的代表,杭州一套作为地方频道的代表,二者都是相对的强势频道;北京卫视作为落地卫视的代表,也是收视率表现上相对弱势的频道。通过对这几个频道2009年12月1日—31日平均收视率的对比,试图解释收视率在不同测量技术和不同样本规模下的不同表现。
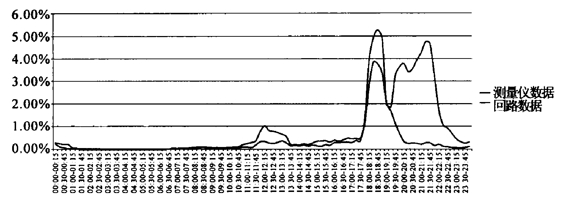
图14 2009年12月 回路数据与测量仪数据收视率对比(杭州一套)
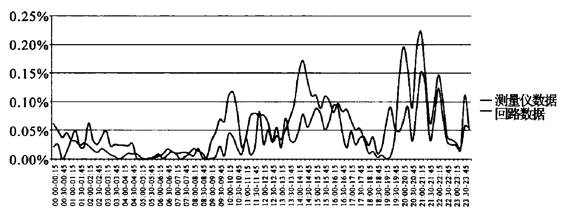
图15 2009年12月 回路数据与测量仪数据收视率对比(北京卫视)
对比使用两种测量方法在中央频道和地方频道上表现出的数据差异,在央视一套的收视率数据中可以清楚地看到,两种测量方法的数据在趋势上基本保持一致,测量仪数据整体上比回路数据低,因为存在户收视率与人收视率之间的数学关系,这种趋势趋同但整体上略低的情况基本上还在可以接受的范围内。在杭州一套的收视率数据中,情况发生了逆转:在白天时段,两种测量方法的数据保持相对统一的趋势;但到了晚间黄金时段,两种测量方法的数据就呈现出截然不同的情况,测量仪数据基本保持在持续高峰的状态,而回路数据则明显只有一个峰值,并且在黄金时间(18∶00—22∶00)收视率均值方面,测量仪3.84%的数据要远远高于回路数据的1.33%。
再以北京卫视来比较弱势收视情况下两种测量方法的收视率数据。可以看到,测量仪的数据表现规律性不强,难以区分明确的高峰和低谷。相对来说,回路数据就显示出较强的可解释的收视特征。这种特征产生的主要原因在于:相对于测量仪的300户样本来说,如此小的收视率绝对值(全天平均收视率0.04%)实际上在统计学表述中已经失去了意义。
回路数据与传统测量仪数据在安全性上的考量
回路数据除了在测量精度上比传统测量方式相对更高之外,在数据的安全性上也因为样本户选择的不同而有很大区别。因为回路数据采用匿名的定向升级方式,因此并不需要样本户同测量公司进行互动,这带来的好处就是样本户的隐匿和更换的便利性。样本户的隐匿可以在很大程度上避免前文所述的让整个行业头痛的测量操控行为。传统测量中为避免样本户疲劳而必须定期地更换样本户,在回路数据测量技术下,这种更换的周期和比例都可以不再遵循传统做法——因为从某种程度上讲已经不存在样本户疲劳的问题了。
安全性的提升很难通过定量的方法进行测量比较,因此本书选取了2008年、2009年杭州地区的开机率(HUT)数据进行比较,采用的数据分别基于10000万户样本的回路数据和300户样本的测量仪数据。
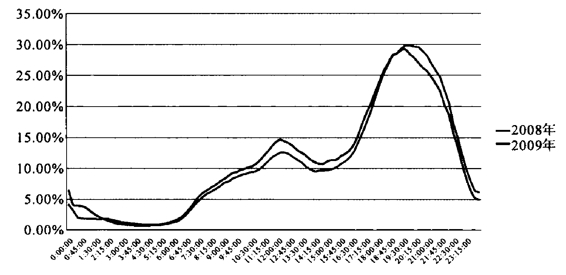
图16 2008—2009年终端回路数据开机率(HUT)比较
首先分析本次实验10000户样本的开机率数据。该数据表现出2008年、2009年全天时段开机率(HUT)数据保持了相当的稳定性,从图17的开机率曲线对比中可以看到,2008年、2009年的开机率曲线基本呈现吻合状态。
计算2008年和2009年开机率数据的拟合度:
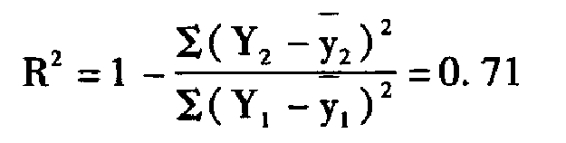
在以15分钟为基准时段的比较中,开机率增长的时间段主要集中在午夜0∶00—1∶15,白天7∶00—16∶00,开机率下降的时段主要集中在19:30—22∶00。因为晚间黄金时段集中了电视广告的主要价值,因此以该时段中的18∶00—22∶00时段来分析两套数据的差别。在该时段中,2008年的平均开机率为27.15%,2009年的平均开机率为25.79%,相对于2008年下降了5.15%;21∶30—21∶45为开机率下降的峰值,达到10.45%。
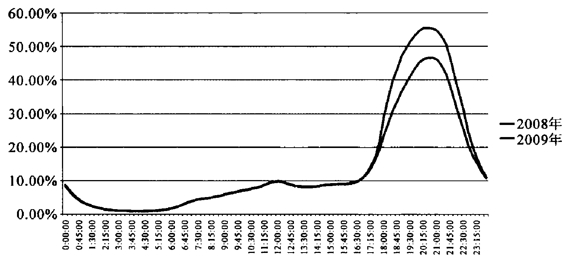
图17 2008—2009年测量仪数据开机率(HUT)比较
再对CSM300户样本的杭州地区开机率数据进行分析。可以看到,测量仪数据的全天平均开机率在非高峰时段吻合度非常高,两年的曲线基本呈重合状态;但是在晚间黄金时段,开机率的情况迥然相异,2009年的晚间黄金时段开机率数据大幅提升。
计算2008年和2009年开机率数据的拟合度:
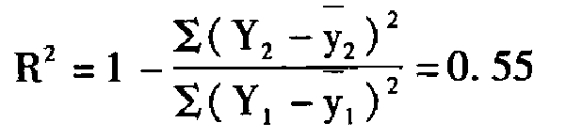
依然以18∶00—22∶00黄金时段的开机率数据进行比较,2008年的平均开机率为39.5%,2009年的平均开机率达到48.5%,相对于2008年的开机率增长了23.3%;19∶00—19∶15为开机率增长的峰值,达到28.7%。
再将回路数据和测量仪数据进行横向比较,可以看到:二者的数据无论是绝对值还是相对变化趋势都呈现出截然不同的情况,二者之间的某些差异可以间接对两种数据系统的测量安全性进行一些判断。
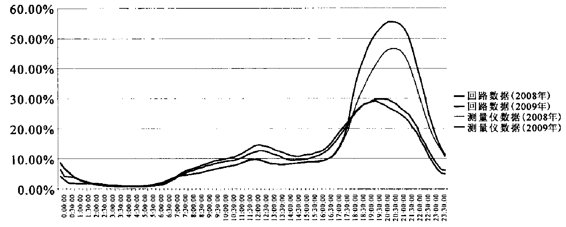
图18 2008—2009年回路数据与测量仪数据开机率(HUT)比较
从图18可以看出,对于开机率绝对值本身,由于两种测量系统存在着抽样框、抽样方法等方面的区别,因此在数值上反映出不同总体的开机率情况(测量仪数据包含少部分模拟信号用户,回路数据只包含数字电视用户),但是通过图示可以看出,二者在开机率数值上的差异已经不能用这种样本分布情况来解释了。以2009年的开机率为例,回路数据的时段平均开机率为11.1%,而测量仪数据的时段平均开机率为14.63%;回路数据在黄金时间18∶00—22∶00的平均开机率为25.8%,而测量仪数据在该时段的平均开机率高达48.5%。也就是说,在白天时段中,两种测量方法的开机率情况相似度较高;而在晚间高峰时段,测量仪数据的开机率高出回路数据近一倍,这种差异已经不是简单的样本分布和抽样方法可以解释的了。
再看两种测量方法得出的两年开机率数据的拟合度。回路数据两年全天时段平均开机率的拟合度为0.71,测量仪数据为0.55,可见回路数据的稳定度大大超过了测量仪数据。两种测量方法在黄金时段(18∶00—22∶00)开机率的拟合度上表现出更大的差别:回路数据的黄金时段拟合度为0.62,测量仪数据为-0.198。换用更为直接的现象表述,即相对于测量仪数据来说,回路数据更好地证明了两年之间杭州地区电视观众开机行为的相对稳定性,而测量仪数据在黄金时段的数据表现则很难说明问题。
通过对两种测量方法的数据进行横向和纵向的比较分析,可以得出一种假设,即测量仪的数据在某种程度上存在测量操控的可能。这种假设的主要原因是:首先,本书进行比较所采用的数据指标是开机率,这也是收视测量体系中最为宏观的一个指标,其受内容细分、受众细分的影响不大,主要表征的是观众的基本开机情况。从统计学理论上讲,测量仪数据在这个指标上并不存在样本量过小的问题——也就是相对于测量内容来说,300户样本足以表征有多少受众打开了电视机。其次,两种测量方法在相邻两年开机率数据上的绝对值和拟合度差异说明,在绝对值上,两种方法存在着白天时段一致而黄金时段相差一倍的数据表现;而在拟合度上,测量仪数据在稳定性上表现较差,其黄金时段的拟合度甚至无法用正常的逻辑来解释和判断。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。