



二、描述统计分析
描述统计分析是社会统计分析的最基本和常用的方法,它是指运用一定的统计量说明数据资料的特征及其相互关系。主要包括集中趋势分析、离散趋势分析、相关与回归分析等。
1.变量的集中趋势分析
集中趋势分析是指用一定的指标反映数据资料的集中状况、集中程度或平均水平。前面谈了用分布来研究变量,这是最全面的研究方法。在很多情况下,我们并不需要对变量有详尽的了解,而只是要了解其大概,或只要了解分布的主要特征以便简化资料。例如,我们只要大概了解当前青年的结婚年龄等等。于是就产生了用某一个典型的变量值或特征值来代表全体变量的问题。这个典型的变量值或特征值就称作集中值或集中趋势。当然这样做的结果是会牺牲变量的某些信息的。我们的目的就在于选择这样的集中值,以便用它来估计或预测变量时所产生的误差最小。根据这样的原则,一般有三种方法来选择集中值:一是根据频次,哪个变量值具有的频次最多,就选择哪个变量值。例如,一个城市有多种产业,但如果以旅游业为最多,那就称为旅游城市。当然,我们也不排除城市中还有其他的产业,但是旅游业在城市的所有产业中所占的比重是最高。二是根据居中,举例说,如果一个城市的居民生活水平,居中的是小康家庭,那么就用小康家庭来代表这个城市的生活水平。三是根据平均,常见的有用平均成绩来代替一个班级、一个组的水平。这三种集中值就是集中趋势分析常用的三个测量指标:众数、中位数和平均数。
(1)众数(众值)
众数是指出现次数最多的数值,用来表示变量的集中程度,也叫众值。从某种意义上来说,具有频数最高的变量值,代表性也是最好的。如果变量x具有如下的分布:
1、2、2、5、2、6、2、3、8、2、0、1、2、4
那么,它的众值为M0=2。
对于连续型定距变量,如果变量在第i组具有最高的频次密度,则用第i组中心值bi来表示变量的众值。
众值可适用于任何层次的变量,因为只要知道频次分布,就能找到众值。因此,是最易求出的。它特别适用于单峰对称的情况。也是比较两个分布是否相近首先要考虑的参数。对于多峰的图形,由于众值不唯一,一般不用它来讨论。
(2)中位数(中位值)
中位数是变量的一个取值,它把观察总数一分为二,其中一半具有比它小的变量值,另一半具有比它大的变量值。所以,中位值是数据序列之中央位置之变量值。
未分组数据中位数的确定:
①根据原始资料求中位值。当原始数据比较少时,可直接将资料按顺序、大小排队。
当观察总数N奇数:中位值Md位于 的地方
的地方
234791111
或者:
丁丙丙乙乙
上述两组数据很容易就发现中位值分别是7和丙。
当观察总数N为偶数时,由于中位值位于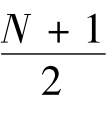 的地方不存在变量值,所以中位数取居中位置左右两数的平均值为中位数。
的地方不存在变量值,所以中位数取居中位置左右两数的平均值为中位数。
345899
中位值Md= =6.5
=6.5
②根据频次分布求中位值。当原始数据很多时,这时可根据分布来求中位值(表11-11)
表11-11

中位值位置=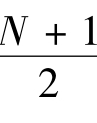 =250.5;中位值M=乙
=250.5;中位值M=乙
d
中位值对于变量层次在定序以上的都可以使用。因此,对定序变量来说,有两种集中值可供选择。但由于众值不考虑变量次序,所以对定序以上的变量,无疑是一个损失。定序变量一般采用中位值,以求其精确。
分组数据中位值的确定:对于分组数据,可以通过累计百分比中的50%点求出。
①根据统计表中的累计百分比,找出含有50%的区间(图11-9)
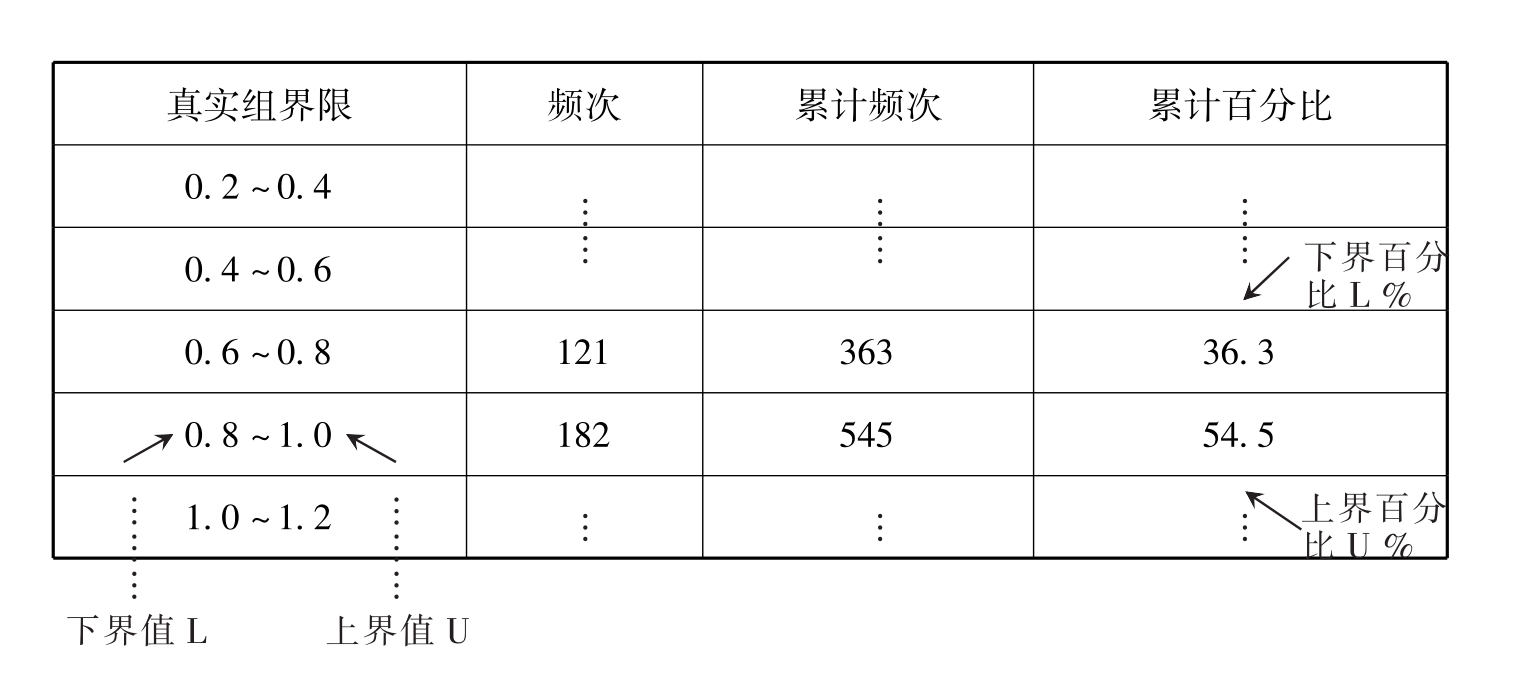
图11-9
②求出含有50%区间的上界值U、下界值L、上界累计百分数U%、下界累计百分数L%和组距h
L=0.8,U=1.0
L%=36.3%,U%=54.5%
h=1.0-0.8=0.2
(3)平均数(均值)
平均数是表达数量的集中趋势的常用方法。用平均数作为变量的集中值,不仅考虑到变量值的频次、次序,而且还考虑到它的大小。数据资料中任何频次、次序和数值大小的变化,都会引起平均数的改变。因此它是灵敏的,也是对资料所提供信息运用得最充分的。
未分组数据平均数的计算:
①根据原始资料求均数。当原始数据比较少时,可直接累加观察值,除以观察总数,以求得均值。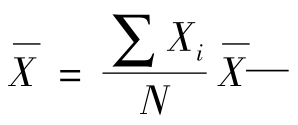 表示变量x的均值;
表示变量x的均值;
∑Xi—表示资料所观察到的变量值(观察值)的总和。
N:观察总数,例如;
五户干部家庭人数为:7;3;11;10;4。
六户工人家庭人数为:6;5;5;8;10;8。
根据公式:X(干)=(7+3+11+10+4)÷5=7(人)
X(工)=(6+5+5+8+10+8)÷6=7(人)
可见用集中值比较,说明干部家庭的平均人口与工人家庭的平均人口相同。
②根据频次分布求均值。利用频次分布可以简化均值的计算。
公式: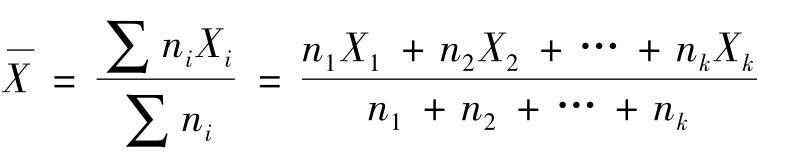
其中:n1Xi表示变量值Xi与它对应频次xn的乘积;
n2X2表示变量值X2与它对应频次n2的乘积; nkXk表示变量值Xk与它对应须次nk的乘积;
∑niXi=n1X1+n2X2+…+nkXk
∑ni=n1+n2+…+nK=N
分组数据平均数的计算:
对于分组数据,可用组中心值来代替变量值。计算方法与未分组数据相同。(https://www.xing528.com)
例如,以下是对每天看电视时间的统计(表11-12):
表11-12
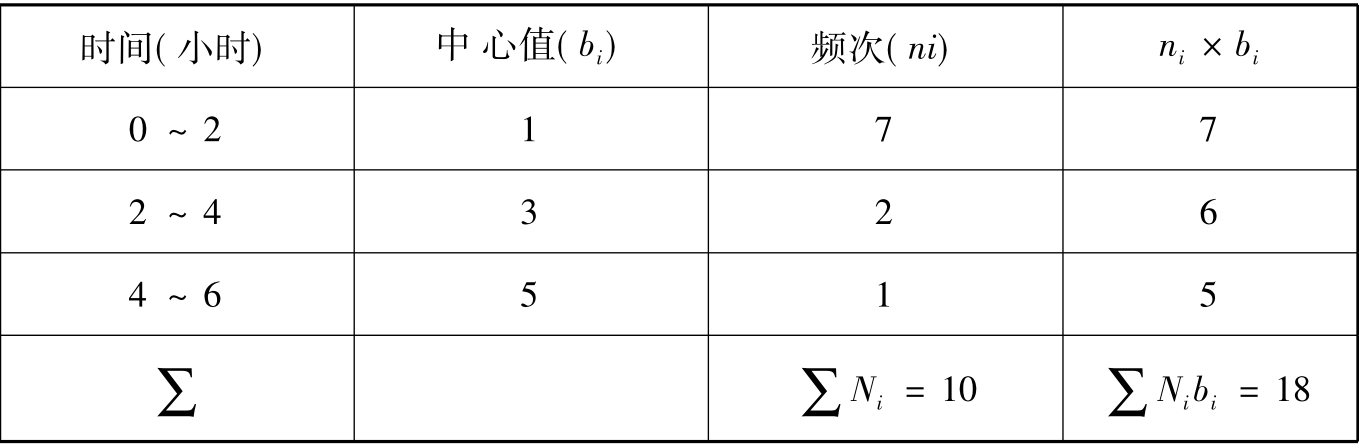
应该指出,用中心值计算的均值与用原始数据计算的均值相比是有误差的。但对社会科学来说,大多数情况下,其精确度已是足够的了。
(4)众值、中位值和平均值的比较
第一,三值设计的目的是共同的,都是希望通过一个数值来描述整体特征,以便简化资料。它们都是反映了变量的集中趋势。一般说来,
众值:适用于定类、定序和定距变量
中位值:适用于定序和定距变量
均值:适用于定距变量。
但有时对于定序变量,如果求平均等级也可使用均值。对于定类变量,如果人为地把每类赋予一个数值,例如设“男=1,女=0”,那么,男性在总体上所占的比例,实际就是这种特殊的均值。由于在统计技术中,应用更多的是均值,而不是中位值或众值。因此,我们应该更多地想法用上均值。
第二,众值仅使用了资料中最大频次这一信息。因此,资料使用是不完全的。实际上在两份资料中只要最大频次所对应的变量值相等,那么,用众值来评价资料,两者就没有区别了。而中位值由于考虑了变量的顺序和居中位置,因此,它和总体的频次分布都有关。但由于它只考虑居中位置,因此,其他变量值比中位值大多少或小多少是不影响中位值的。而均值由于既考虑到频次,又考虑变量值的大小,因此它是灵敏的。
第三,虽然均值对资料的信息利用最充分,但对严重偏态的分布,会失去它应有的代表性。例如,一个国家会因某些少数富翁的存在,使平均收入变得很高。因此对于偏态的分布应使用中位值作为集中的趋势。只有单峰和基本对称的图形,用均值作为集中趋势才是合理的。
对于对称的图形,众值、中位值和均值三者位置重叠。当图形正偏或负偏时,均值变化最快,中位值次之,众值不变。除了用众值、中位值和均值反映资料的集中趋势外,还有几何平均值、调和平均值等等,这里不再介绍,有兴趣的读者可以查阅有关书籍。
2.变量的离散趋势分析
虽然变量的集中趋势为我们提供了变量分布的综合数据,但是,在很多情况下,仅仅知道众数、中位数和平均数是不够的。比如我们想知道某城市两家出租车服务公司电话叫车的服务速度,甲公司在用户打通电话到出租车驶到其家门口的平均花费时间是12分钟,乙公司则平均花费时间13分钟,我们是否能够就此得出结论两家公司的叫车速度基本相同呢?进一步了解的结果是,甲公司的出租汽车慢的时候要30分钟才能到达,快的时候3分钟就能到达,而乙公司的汽车到达时间约在10~15分钟之间,显然,相比较而言,乙公司的出租车叫车速度比较稳定。
众数、中位数和平均数都反映了资料的集中特征,但这还不够,我们不能只是考虑变量的集中情况,而且还要考虑变量的分布情况,这就要用到离散趋势分析。所谓离散趋势分析,就是指反映数值资料的分散或差异程度的统计分析。在离散趋势分析中,往往使用变异指标来度量数值分布的离散程度。常用的变异指标有极差、四分位差、方差和标准差以及异众比率等。
(1)极差与四分位差
极差是最简单、直观的变异指标,是各总体单位标志值中的最大值(L)和最小值(S)之差,又称全距,通常用R表示,计算公式如下:
R=L-S
全距的优点在于计算方便,意义明确。在实际工作中,全距可用于工业产品质量的检查和控制。在正常的生产条件下,产品质量性能指标如强度、硬度、浓度、长度等的差距总是在一定的范围内波动的。利用全距指标进行产品质量检查和控制,可以及时发现问题,采取相应措施,保证生产正常运转。
但是全距说明的只是极端标志值之间的差异,它不受中间标志值的影响,更与变量数列的次数分布状况无关,只取决于极端标志值,具有一定偶然性。因而它不能全面反映各单位标志的变异程度,也不能用以评价平均指标的代表性程度,还需要适当运用其他的变异指标。
分位差是对极差指标的一种改进,或者说,就是从变量数列中剔除了一部分极端值之后重新计算的类似于极差的指标。常用的分位差有四分位差、八分位差、十分位差、十六分位差、三十二分位差以及百分位差等。这里仅以四分位差为例加以说明。
计算四分位差的直接目的是排除部分极端值对变异指标的影响,为此,需要首先从总体分布中剔除最大和最小的四分之一的单位,再对中间剩余下来的总体半数单位计算全距。这个全距实际上就是3/4位次与1/4位次的标志值的差,通常称为四分位差,即Qd=Q3-Q1
上式中,Qd表示四分位差,Q1和Q3分别表示1/4位次和3/4的标志值。
与四分位相差类似,还可以计算总体分布的八分位差、十分位差、十六分位差等。它们的作用都是排除少数极端值对分布变异范围的异常影响。分位的程度越高,分位差所排除的极端值的比例就越小。实际分析时,需要根据具体情况和要求有选择地运用。
(2)标准差和方差
标准差和方差是测定离散趋势最重要、最常用的指标。方差是总体各单位数值与其均值之差的平方和除以总体单位数,用σ2表示为:
![]()
标准差是方差的平方根,即各数值与其均值之差的平方和除以总体数的平方根,其公式为:

方差和标准差都是衡量一个样本波动大小的量,样本方差或样本标准差越大,样本数据的波动就越大。
标准差与方差不同的是,标准差和变量的计算单位相同,因此很多时候我们分析的时候更多的使用的是标准差。
(3)变异系数
各种变异指标,包括极差、四分位差、标准差,都有与平均指标相同的计量单位,都是反映总体各单位标志值变异的绝对指标。这些变异指标的大小不仅取决于总体的变异程度,而且还与标志值绝对水平高低、计量单位的不同有关。所以,不同现象或具有不同水平的单位,不宜直接用变异指标来比较它们的变异程度,必须消除水平高低的影响,才能真正反映出不同水平的变量数列的离散程度。这时应该采用标志值变异的相对指标,即变异系数。
变异系数也称离散系数,是各变异指标与其算术平均数的比值。对不同的变异指标计算变异系数,分别有
极差系数:V极=极差/平均数×100%
标准差系数:V标=标准差/平均数×100%
(4)异众比率
当用众值表示资料的集中值时,我们不知道非众值的频次和在总数N中所占的比例。显然,非众值的比例越小,众值的代表性就越好,信息量越大。反之,非众值所占的相对频次越大,众值的代表性越差,所提供的信息量也就越小。异众比率Vr是非众值在总数∑fi中所占的比例。

其中:Vr为异众比率,∑fi为变量值的总频数,fm为众数组的频数。
可见,异众比率是众值的补充。当Vr=0,说明变量只有一个取值,那就是众值。这是众值可以完全代表变量,因此它的信息量最大。当Vr→1时,表示资料十分分散。众值几乎没有代表性。
3.变量的回归分析
回归分析是确定两种或两种以上变数间相互依赖的定量关系的一种统计分析方法,运用十分广泛。回归分析按照涉及的自变量的多少,可分为一元回归分析和多元回归分析;按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。如果在回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
提到变量之间的关系,很容易想到变量之间的函数关系,那就是由一个变量可以通过函数关系确定另一个变量。但回归所研究的变量之间的关系,却不是确定的函数关系,她所研究的是变量之间的相关关系,或者是研究其间的因果关系。
实际上,非确定性的关系在自然、社会中是广泛存在的。这是由于任何一个现象的产生,究其原因是多方面的。当我们只研究其中的某一个原因或几个原因,而对其他原因未予控制时,变量间的因果关系就表现为不确定的相关关系,而不是函数关系。
简单地说,回归分析就是对拟合(1)问题作的统计分析。
具体地说,回归分析在一组数据的基础上研究这样几个问题:
第一,建立因变量y与自变量x1,x2,…xm之间的回归模型(经验公式);
第二,对回归模型的可信度进行检验;
第三,判断每个自变量xi(i=1,2,…m)对y的影响是否显著;
第四,诊断回归模型是否适合这组数据;
第五,利用回归模型对y进行预报或控制。
回归分析的检验包括:相关系数的显著性检验、回归方程的显著性检验、回归系数的显著性检验等,它们是从不同角度对回归方程的预测效能进行验证的。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。