



我们遇到或使用语言的一种方式就是言语形式。除非听到的是外语或者讲话者有严重的口吃,否则在通常情况下,理解一个人对你说的话是相当容易的。我们在绝大多数情况下都能明白儿童、成人、说话流利的人,甚至是有很陌生的地方口音的人所讲的话。
一种看似很合理的说法是,我们知觉言语的方式(我们认为的)如同我们对书面文字的知觉一样每次知觉一个音,运用声音中的停顿(就像字母间的空白间隔)来识别单词,运用单词间的停顿来确认何时一个单词结束而另一个又开始。遗憾的是,事实上根本就不是这么回事。(事实上,有证据表明我们在加工书面文字时也不是一个接一个词进行的。)
Joanne Miller(1990)阐述了言语知觉中的两个基本问题。第一个问题是,言语是连续的。各个声音之间少有停顿,同一个词中的不同声音会相互掺杂。这在图9-4中表示得十分清楚,该图显示了一幅口语句子的声谱图,声谱图是对言语的图解表征,x轴表示时间,y轴表示声音的频率,单位是赫兹(每秒包含的周期数)。图中较暗的区域所表示的是每个频率上各个音的强度。注意其中的边缘(空白部分),它们并不同单词或是音节的边界相吻合。换句话说,当你在听某人讲话时,音节和单词之间听起来好像有停顿,但其中很多只是一种错觉!
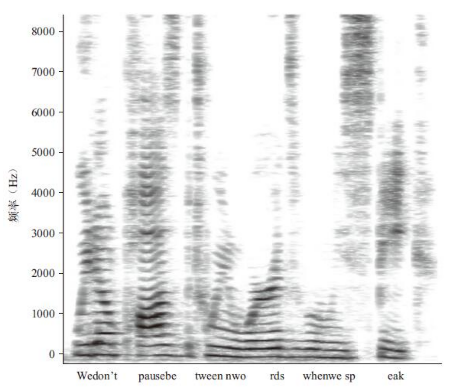
图9-4 一个人在说这句句子时的声谱图
言语知觉中的第二个问题是,单个的音素会因为上下文而听起来有所不同。虽然dog、dig、dug、deep和do看上去好像都是同一声音开头,但实际情况并非如此。图9-5是我发出这5个单词时记录的语图,仔细检查会发现这5个词根本没有什么共同的特征。此外,通常情况下女性和男性讲话时会有不同的音高(女性声音往往音高或频率更高),不同的人有不同的口音,同一个人在叫喊、诱哄、低语和讲演时讲话的方式也是不同的。因此你应该意识到,要确定哪个音素纯粹是由声音刺激的物理性质产生的有多么复杂。
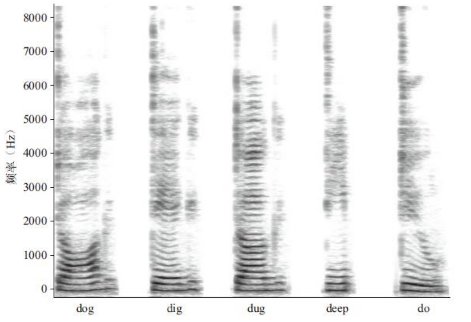
图9-5 人在发dog、dig、dug、deep、do这些单词时的声谱图
虽然我们显然都对语言中的关键声音差别予以仔细的关注,但并不只是声音才会影响我们的知觉。Massaro和Cohen(1983)设计的一个精巧研究证实了我们在言语知觉的过程中也利用了视觉信息。他们研究了\b\和\d\这两个只在发音清晰度上有区别的闭塞辅音的类别性知觉。实验中,被试听到9个计算机合成音节,根据声音属性从清晰的“ba”到清晰的“da”排列。在“中性”条件下,被试只听到声音而没有视觉信息。而在其他两个条件下,被试在听音节的同时,会看到一个没有出声但与磁带声音同步做出“ba”或是“da”发音模样的人。有一个问题是,当磁带发出“da”音而录影带中的人是发“ba”音时,被试是否能发现其中的差别,答案为否定。然而,有趣的是讲话者看上去在讲什么确实影响了被试所听到的内容。相对“中性”条件,在知觉“ba”-“da”系列中间的音节时,录影带中说话人的口型会使知觉产生细微的差别。
视觉线索显然影响了声音如何被知觉。你可以将其描述为一种情境效应,在第3章中我们已经提到过。许多其他研究证实了言语知觉还受到众多其他情境的影响。Warren及其合作者的研究(Warren,1970;Warren & Obusek,1971)已经证实,在一些情况下人们会“听到”根本不存在的音素。在1970年的研究中,Warren给被试听一个句子的录音,内容是“The state governors met with their respective legi* latures convening in the capital city”。句中有120毫秒的部分被一声咳嗽音替代(用星号表示)。20个被试中只有1个报告察觉到有一个缺少的声音被咳嗽声掩盖,但他没有报告对声音缺失的位置。剩下的19个人证实了“音素修复效应”(phoneme restoration effect)的存在,之所以用此名称来命名这种效应,是因为听者似乎在知觉过程中通过其他语言信息的预测“修复”了缺失的音素。
人们可以通过大量的信息来“预测”缺失部分该是什么声音。Warren等人(1970)通过向人们呈现下面4个句子中的1句,证实了这点。4个句子除了最后一个后期接上的单词外都以同样的方式进行录音,每个句子都缺少一部分,句中用星号表示:(https://www.xing528.com)
(11)It was found that the * eel was on the axle.
(12)It was found that the * eel was on the shoe.
(13)It was found that the * eel was on the orange.
(14)It was found that the * eel was on the table.
根据句子中为缺失声音提供的语境,被试报告听到了wheel、heel、peel或是meal。[1]这里我们又一次看到了上下文指引入对声音的知觉,特别是听者根本还没有意识到这种影响的存在。
其他研究同样表明了人们利用上下文来帮助他们进行言语知觉。Marslen-Wilson和Welsh(1978)在一项研究中要求被试“跟踪”言语,也就是大声重复听到的内容(就像你能记起的第4章中遇到过的追踪任务)。研究者呈现给被试的言语有所变形(比如cigaresh这种假单词)。他们发现被试经常会将变化过的内容恢复为确切的发音(cigarette),特别是该单词与前面的语境高度相关时(如,Still,he wanted to smoke a _____)。这个结论说明了读者和听者通常利用句子上下文中的前一个词来预测下一个词,如果那个词呈现的是歪曲的形式,甚至还会“错听”或是“错读”该词,你可能会注意到在第3章的一个标题下也提到了类似的视觉情境效应。
在过去的10年中,我所接触的一些公司(大多是航空公司和信用卡公司)相继安装了语音识别系统。举例来说,我可以拨打一个免费电话来查看信用卡的余额,或是查询航班起飞和到达的时间信息,而我所做的仅仅是在电话中清楚地报出卡号或是航班号。你可能会想,言语的识别是如此复杂,计算机是如何做到这些的呢?
这个问题的答案同我们在第3章中讨论的笔迹识别系统的原理是相对应的。简单来说,输入的刺激被限制在一些不同的类别之中。语音识别系统事实上只能够识别不同的数字。他们不需要了解我说的是哪种语言(他们只在一种语言下工作),而且他们只需要对“1”“2”或是“3”有特定的反应即可,而不是对“斑马”“坩埚”或是“飓风”有反应。
[1] 4句句子的后半部分分别是“车轴上的轮子”“鞋上的鞋跟”“橘子上的果皮”和“桌上的食物”之意。虽然4个单词都以eel结尾,但在不同的上下文中被试会听到不同的单词。——译者注
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。