



通常当人们提到记忆时,总认为信息的保持要长于一两秒。在本章剩下的部分和下一章中,我们将讨论对于非心理学家的人来说更为熟悉的记忆种类。
首先我们来看短时记忆(STM),当你查了电话号码,穿过一个房间来到电话机旁并开始拨电话时,使用的正是这个记忆系统。假如我让你打电话给我的一个学生,他的电话号码是555-4362。而且,如果你不能带着本书而必须记住这个号码,直到你在附近的电话上拨这个号码,你将怎样完成这个任务呢?你可能会在穿过房间时出声地复述这个号码。一旦拨完号码开始对话,你就很可能忘记所拨的这个号码。这个例子说明了短时记忆一个方面的特性:它只能持续很短的时间。(认知心理学家一般认为短时记忆可以持续1或2分钟,但也有一些神经心理学家认为,短时记忆中的信息可以保持一天,这引发了一些争论。而在本书中提到的短时记忆,所指的是信息能保持约一分钟的记忆。)
除了信息保存时间的长度外,还有没有其他的特性能把短时记忆与长时记忆区分开呢?致力于此项工作的心理学家相信,有许多这样的特性存在,它们包括信息储存的多少(容量)、信息储存的形式(编码)、信息保持和遗忘的方式,以及信息提取的方式。
在过去的20年中,从信息加工范式对记忆进行研究的心理学家对短时记忆的定义有了很大的改变。为了避免混淆,我们先对短时记忆的传统描述进行回顾,然后再讨论一种新的被称为工作记忆的概念。
如果你只想在短时期内保存信息(如上面例子中的记电话号码),你会有多少空间来完成呢?换句话说,在很短的时间内你能记住多少信息?针对这些问题,乔治·米勒(George Miller,1956)在一篇经典论文中做出了如下与众不同的阐述,文章的开头是这样的:
我一直为一个整数所困扰。7年以来,这个数字总是如影随形,闯入我最为隐私的数据之中,并且从最公开的杂志中向我袭来,这个数字有许多伪装,有时大有时小,但从来也不会变得太多以至于认不出来。
折磨我的这个数字持续存在远非偶然事件那么简单。引用一位著名议员的话来说,它的背后有一个阴谋,某种模式控制着它的表现。关于这个数字,要么确实有一些不同寻常的意义在里面,要么就是我产生了遭受困扰和迫害的错觉(p.81)。
这个困扰米勒的整数是7(加减2)。在其他事物中,7(加或减2,依个体、材料及其他情景因素而定)是我们短时记忆所能保持独立单元数的最大值。我们将它称为短时记忆的容量(capacity)。
米勒(1956)对相关的证据进行了回顾,如果向你呈现一串随机的数字,只有当这串数字个数小于或等于7个时,被试才能将它回忆出来。对于任何其他随机的字符串(字母、单词、缩写词等)情况也是一样。唯一能克服这种局限的方法就是把单个字符构成的单元组块(chunking)为较大的单元。例如,以如下一串字母为例:NFLCBSFBIMTV。它包含了12个字母,超过了一般人的短时记忆容量。但是,如果你仔细观察这些字母,就会发现它们其实是由4个众所周知的缩写词组成:NFL(the National Football League,全美美式足球协会),CBS(美国目前主要的三大电视网之—),FBI(the Federal Bureau of Investigation,联邦调查局)和MTV(音乐电视台)。如果你注意到这12个字母实际上是由4个缩写词组成的话,就很容易回忆出整个字母串。认识到三个相邻字母能“联合在一起”形成一个独立单元,就意味着对它们进行了组块。
组块依赖于知识。不熟悉美国文化的人可能只把MTV看作三个随机呈现的字母。米勒(1956)把形成组块的加工(他称其为“再编码”)看作记忆的基本加工,即一个能在任何时间增加我们加工信息量的有力手段,也是我们日常生活中经常不断使用的方法。组块加工可视为一种克服短时信息储存仅有7个单元这一严重局限的重要手段。
编码(coding)指的是对信息加以心理表征的方式,也就是信息保存的形式。如前面的例子一样,当你试着记住一个电话号码时,你是如何表征它的呢?Conrad(1964)进行的一项研究回答了该问题。他向被试呈现一个辅音表,然后让他们回忆。尽管字母是以视觉方式呈现的,被试易犯的错误却往往是那些在读音上与标准刺激相似的字母。因此,如果说呈现的是P,稍后如果被试回忆这个刺激时出错的话,就很可能会报告一个读音上与P类似的字母(如G或C),而不会报告一个与P外形相似的字母(如F)。请记住,最初呈现的是视觉信息,但被试显然是在声音上产生了混淆。被试明显是通过声音方面而不是视觉方面的特性来形成心理表征的。
Baddeley(1966a,1966b)后来的研究证实了这个效应,即使刺激不是字母而是单词,情况也是如此:读音相近的词的即时回忆效果差,词义相近的单词则不会这样,而对于延迟回忆来说情况正好相反。尽管听觉编码不是短时记忆中唯一使用的编码,研究者还是将其视为占主导地位的编码方式,至少对于听力正常的成人和年龄较大的儿童来说是这样的(Neath & Surprenant,2003)。
我们把短时记忆看作信息的短时存储。那么,这个保存时间到底有多短呢?Brown(1958)以及Peterson等人(1959)通过各自独立的研究得出了一致的结论:如果不加以复述,信息在20秒之内便会从短时记忆中丢失。这个时间长度被称为记忆的保持时间(retention duration)。
Brown-Peterson的任务是以如下方式执行的。呈现给被试三个相连的辅音字母,例如BKG。同时呈现一个数字如347,并让他们按节拍器以每秒两次的速度做递减3的运算。计算的目的就是避免被试复述三连字母。被试必须进行计算的时间长度是有所变化的。如果只让被试计算3秒钟,约80%的被试能记起那个三连字母,而如果让他们计算18秒的话,能回忆的人数就会下降到7%。Brown和Peterson都把这个发现解释为记忆痕迹的衰退(decays)或者破坏,即需要记住的短时记忆信息的心理表征没有得到复述。通常这一衰退就是在约20秒的时间里发生的。下面我们用这个来解释电话号码的例子:如果告诉你我的电话号码,而你又没有采取什么措施去记住它(即通过复述或把它写下来),那你将至多记住它30秒。过后,记忆痕迹就已衰退而信息也将会丢失。
然而,不久其他的认知心理学家就开始挑战这种对遗忘的衰退解释。他们提出了一个不同的遗忘机制,称为干扰(interference),其大致原理是:一些信息可以“替换”其他信息,从而使得前面的信息难以获得提取。你可以把干扰的解释理解为在桌面上找一张纸。每学期开始的时候,我的桌子(相对而言)比较整洁。每一张放在桌上的纸都很容易找到。然而,随着学期的进行,我的时间会越来越紧,我会听任所有便签纸和期刊的堆积,而学期初放在桌上的纸被彻底掩埋了;它们肯定在桌上,但很难马上找到它。后面的纸取代了先前的纸。

我办公桌的照片,用来类比记忆干扰。
我们能用干扰来解释Brown-Peterson的实验结果吗?再想一想计数任务,其目的无非是分散被试的注意力,使得他们不能复述三连字母。但可能这一任务不仅起到阻止被试复述的作用,实际上它可能干扰了三连字母的短时存储。当被试大声计数时,是在一边计算一边报告数值。而在他们计算和报告数值的同时,会把结果储存在短时记忆中。这样,计算得出的数值实际上可能取代了最初的信息。
Waugh和Norman(1965)做的一个研究证明了干扰在短时记忆中的作用。他们发明了数字探测任务(probe digit task),具体操作如下:给被试一个由16个数字组成的数,如1596243789024815。该数中最后一个数字是被试回答报告的线索,被试的任务是要报告该数第一次在数列中出现时紧跟其后的数字。(这一说明稍有些复杂,但确实能够做到;不妨停下阅读自己试一试。)在我们的例子中,线索数字是5(位于数列中的最后一个数字),而该数第一次出现时紧随其后的数是9,所以应该回答9。
Waugh和Norman(1965)快速(每秒4个数字的速度)和慢速(每秒1个数字)呈现数字。他们的推理是,如果是衰退导致了短时记忆的遗忘,那么接受慢速呈现的被试就不能很好地回记出该数字第一次出现在数列中的位置。因为慢速呈现势必会使报告时间滞后,从而导致前面数字更多的衰退。而图5-3(标绘出回忆率与干扰项数目多少之间的函数关系)表明,其实这并没有发生。该数字无论以什么速率呈现,被试回忆数字的表现都是一样的。在所有实验中,被试对位于后面数字的回忆不如对开头数字的回忆,这表明短时记忆中信息的遗忘是干扰而不是衰退造成的。(https://www.xing528.com)
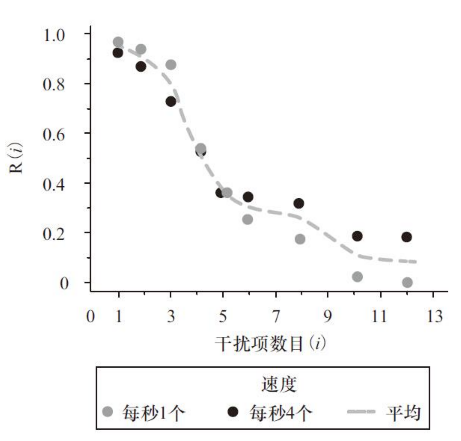
图5-3 Waugh和Norman(1965)的数字探测研究结果
所有这些证据可能会使你认为,所有认知心理学家都同意只有干扰才是导致短时记忆中遗忘的原因。然而,情况没有这么简单。Reitman(1971,1974)起初提供了支持短时记忆遗忘干扰说的证据。其被试在执行Brown-Peterson任务的同时,还执行一项没有干扰的任务:从一串反复读出的类似音节 (“toh”)中侦察一个音节 “doh”。一般认为听力侦察任务能阻止被试复述三连字母,但不会干扰保存在短时记忆中的材料。从对短时记忆遗忘的干扰解释中可以预计,在保持期间三连字母不会丢失,这也正是Reitman(1971)得到的结果。然而,在一个重要的后续研究中Reitman(1974)发现,一些被试承认有“欺骗”行为发生:当他们执行侦察任务的同时会偷偷地复述字母。当Reitman只看那些没有复述过的被试表现时,发现了明显的衰退效应:在15秒的间隔后,只有65%的三连字符串得到了保持。Reitman从中得出结论,如果在短时记忆中没有进行复述的话,信息确实会衰退。
Reitman的研究给我们留下了一个没有解决的问题:究竟是什么导致了短时记忆中的遗忘,是信息痕迹的衰退还是干扰?至少到目前为止,我们不能排除其中任何一种可能。困扰我们的是很难想出一个没有干扰的任务。因而,设计一个限定性的实验(或一系列限定性的实验)超出我们目前的能力范围。
当然,也许“究竟是衰退还是干扰”这一问题提得不好,因为它排除了两者皆包含于其中的可能性。也就是说,短时记忆丢失信息不是只有一种机制。Baddeley(1990)认为,在短时记忆中,伴随着干扰确有一些(尽管很少)衰退痕迹发生。Altmann和Gray(2002)提出,衰退的确会发生而且事实上这对避免灾难型的干扰十分重要。他们相信,当记忆中的信息必须频繁更新时(例如,你正在开车并且必须记住每条公路的限速),当前内容(你在州际公路上行驶,时速70英里[1])的衰退可以避免后续内容的干扰(驶离高速公路,现在的速度限制为时速55英里)。
我们已经讨论了人们在短时期内保存信息的方法:他们如何编码信息,能编码多少信息以及能够保持多长时间。这又给我们带来了一个问题,“当我们再次需要这些信息时,怎样将它们从短时记忆中提取出来?”Saul Sternberg(1966,1969)在一系列关于如何从短时记忆中提取信息的实验中,获得了一些令人吃惊的发现。在介绍他的实验之前,我们先来思考一下从短时记忆中提取信息的各种可能性。
Sternberg第一个考虑的是,我们在短时记忆中搜寻信息是以平行的方式还是以系列的方式进行。例如,想象一下短时记忆中全是一些(少量的)电影名称。假设你的短时记忆中保存了一张我向来都很喜欢的电影清单,我刚刚口头告诉了你。我们把这些电影名称的数目称为记忆组大小。现在假设有人问你《玩具总动员3》是否在你的清单上,要想回答这个问题,你就会在头脑中检索这张清单。
如果你把《玩具总动员3》同时与你清单上的所有电影名称相对照,你所执行的就是平行搜索(parallel search)。不管这些电影名称的数目有多少,你基本上都会同时对它们加以检查,将《玩具总动员3》与10个电影名称相比所需的时间不会比与1个电影名称相比的时间多。图5-4a描述了用平行搜索时的数据走势,图中表示的是搜索时间与记忆组大小的关系。
还有一种可能,你使用的是系列搜索(serial search)。在电影名称的例子中,你可能会先把《玩具总动员3》与清单中的第一个电影名称相对照,然后再与第二个相对照,依次进行下去,直到比照清单中最后一个名称,每次只对比一个。对于这个模型来说,清单越长,用来确定《玩具总动员3》是否与你清单中的一个名称相符所需的时间也越长。一次成功的搜索就如图中“是”那条线所描绘的情况,而失败的搜索(未找到匹配项)则如“否”所代表的直线。
我们还可以确定这个搜寻是自我终止搜索还是完全搜索。自我终止搜索(self-terminating search)一旦发现匹配项后就停止继续搜索。假设你清单上的电影名称包括《公民凯恩》《泰坦尼克号》《玩具总动员3》和《冰川时代》。如果你执行的是自我终止搜索的话,就会在第三次对比完成后停止搜索,因为你已经发现了匹配的目标。通常而言,成功的搜索(发现匹配项后不再继续搜索)比不成功的搜索(必须搜索所有项目)耗时较少。图5-4b描述的是用自我终止系列搜索提取记忆中信息时的情况。

图5-4 Sternberg(1966)的短时记忆扫描实验理论上的预期结果
“是”和“否”代表被试是否能报告记忆组中的探测字母。图5-4a描述的是平行搜索的情况;图5-4b是系列的、自我终止搜索;图5-4c是系列完全搜索,Sternberg报告的数据与图5-4c最为接近。
另一种系列搜索称为完全搜索(exhaustive search),它意味着即使匹配项已被发现,你还须继续检查记忆组中所有其他的项目。在我们的例子中,这就意味着即使找到了《玩具总动员3》,你还得检查清单中余下的电影名称。使用这种搜索时,未成功搜索与成功搜索所用的时间是一样的,图5-4c描述了这种可能性。
Sternberg(1966)的实验任务如下。首先,给被试呈现一排7个或少于7个的字母组。这些字母被编码保存在短时记忆中,因此可以称为“记忆组”。当被试记牢这组字母后,就示意做好准备可以开始实验。此时,呈现给被试一个单独的字母称为探子,被试的任务就是尽快确定这个探子是否在记忆组中出现过。例如,记忆组可能是BKFQ,而探子则可能是K(回答肯定,它是在记忆组中),也可能是D(回答否定,不在记忆组中)。
与直觉相反,Sternberg(1966)的实验结果证实我们从短时记忆中提取信息所采取的是系列、完全搜索的方法。对此的解释是,搜索过程本身可能很快,并且具有一旦启动就难以停下的特点。从加工的角度来看,让搜索过程得以完成并在最终做出决定,而不是在记忆组中各项目后做出决定,其效率更高。Hunt(1978)在回顾中发现,所有类型的人群(大学生、老年人、记忆特别好的人、智力低的人)尽管搜索效率各不相同,记忆好的人快些,老年人慢些,但表现出的结果却都与使用系列完全搜索从短时记忆中进行提取的观点相一致。
正如任何科学观点一样,其他的后续研究发现了Sternberg(1966,1969)提出的系列完全搜索也存在着问题。Baddeley(1976)对其中的一些问题以及对Sternberg发现的其他解释进行了回顾。使人们对Sternberg研究结论发生态度转变要归功于DeRosa和Tkacz(1976)的研究,他们证实在图片刺激的情况下,人们明显是以一种平行的方式在短时记忆中进行搜索。这个研究提出了一个重要的观点:记忆的加工方式会因材料的不同而有所不同,它是所需记忆材料(刺激)的函数。因此,我们不能不假思索地将实验室的研究结果推广到日常生活中来。反之,要想知道一个实验模型对应哪种现象,就需要考虑什么样的信息会以什么样的方式进行加工的。
让我们总结一下到目前为止所介绍的短时记忆系统。20世纪60年代和70年代出现的关于短时记忆的描述是,它是一个短期的、容量有限的仓库,信息在其中进行听觉编码,并通过复述来加以保持。可以用高速、系列、完全搜索的方式从这一存储中将信息提取出来,而短时记忆中信息的特性对改变记忆容量和对已存信息的加工有所帮助。
[1] 1英里=1.6千米。——译者注
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。