



另外还有一种有关知觉的模型,它试图纠正模板匹配模型和特征分析模型的一些缺点,称为原型匹配。该模型和模板匹配模型一样,通过输入信息与业已储存的表征相匹配的原理对知觉加以解释。但是,它与模板匹配模型的不同之处在于,这里的所谓储存表征,不再是必须完全或非常接近匹配的整个模式(这是模板匹配的情况),而是一种原型(prototype),即对某类物体或事件的理想化表征,如字母R、一个茶杯、一台录像机、一只柯利大牧羊犬等。
你可以将原型看作其所代表物体的理想化模型。比如,狗的原型就是对一只非常典型的狗的描述,即你能想象的“最像狗”的狗。与原型完全相像的狗也许存在,也许不存在。图3-14显示了字母R的各种不同变体,如果你直觉就同意大多数先前看过这些R的人的观点,就会认为图中上一行靠左和靠右的字母比中间的字母更具原型的意味。
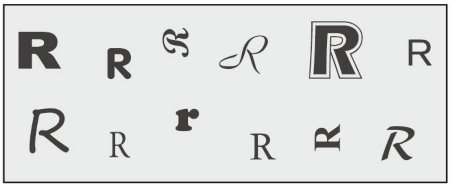
图3-14 字母R的样例
原型匹配理论是这样描述知觉加工的:当一种感觉装置收到了一个新刺激,该装置就会将它与原先存储的原型进行比较,但并不要求完全相匹配,事实上大致的匹配就可以了。原型匹配模型允许输入信息与原型之间存在差异,这就赋予了该模型比模板模型更多的灵活性。一旦这样的匹配找到了,一个物体也就被“知觉”了。
原型匹配模型与模板匹配和特征分析模型的区别在于,它不需要物体包含任何特定的用于识别的特征。相反,特定物体与原型共有的特征越多,匹配的可能性也就越大,而且原型匹配模型不仅顾及了物体的特征和各个部分,还将它们之间的相互关系也一并考虑在内。
然而,原型从何而来呢?Posner和Keele(1968)证实了人能以惊人的速度形成原型。这些研究者编制了一系列由点组成的图形模式,将9个点安排在30×30的方格中,形成一个字母、三角形或者其他的随机模式。然后,将这些点稍微移动到方格内的其他位置(Posner,Goldsmith & Welton,1967)。最初的模式被定为原型,其他(相对于原型发生微小变化的)则都是变形(distortions)。图3-15中显示了一些这样的例子。

图3-15 Posner和Keele(1968)所使用的刺激(https://www.xing528.com)
左上格中的是原型,其他格中的都是变形。
不让被试看到原型,只让他们看各种不同的变形,而且也不告诉他们这些图形其实是变形。被试会依据(他们自己并不知道)产生这些变形的原始模式,学会将这些变形分成各个组。在能够准确无误地执行分类任务之后,再让被试看另外一系列点的模式,并要求他们以某种方式将它们进行分类。实验这个部分呈现的点的模式有三种:旧刺激,即被试已经见过的变形图形;新刺激,即之前并未见过的变形图形;以及被试也不曾见过的原型。结果,被试对旧刺激进行分类的准确率为87%,能对67%的新刺激进行准确分类(仍旧高于随机水平),而原型分类的准确率为85%。
由于被试从来也没有见过原型,他们对原型分类的准确性如此之高实在令人感到惊奇。这又如何进行解释呢?Posner和Keele(1968)认为,在最初的分类任务中,人们对每一类物体都形成了某种形式的心理表征。这些表征可能是心理意象或画面。一些被试甚至可以用言语描述小点在哪里聚集,以及会以何种方式进行汇合的规则。在任何一种情况下,他们对新模式进行分类时都会用到这些表征。
这一研究为在日常的知觉中我们会形成和使用原型的观点提供了凭证,而且它不仅是在点的模式这样的人工刺激中才发挥作用。Cabeza、Bruce、Kato和Oda(1999)在实验中展示了同样的“原型效应”,不过他们的实验材料是人脸的照片,将照片中人脸一些特征(如眉毛、眼睛、鼻子、嘴巴)的位置做上下一定相位的改变。
图3-16显示了实验中所用到的不同刺激。Cabeza等人的报告结果与Posner和Keele的相似,被试更倾向于“认出”他们事实上从未见过的原型脸,而相对不易认出其他的、较少具有原型特点的新脸。
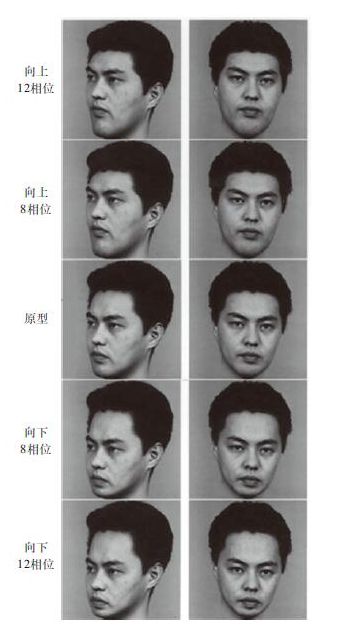
图3-16 Cabeza等人(1999)在研究中所使用的刺激
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。