



在优化步骤中,我们通过调整线程网格和线程块的大小来进行优化。首先,确定一个块的大小为16×16,每个块共有256个线程,很明显,它比线程束的尺寸更大。基于线程块和图像的大小,可以确定线程网格的大小。在第一种方法中,每个线程块中只利用了其中一个线程。所以本方法通过给每个线程块分配更多的线程,利用线程块中的其他线程。
每个新的线程块中包含256个以二维方式排列的线程,如图4.11所示。线程块中的每个线程对应处理输入图像的每个像素。图4.12为MATLAB的原始输入图像。
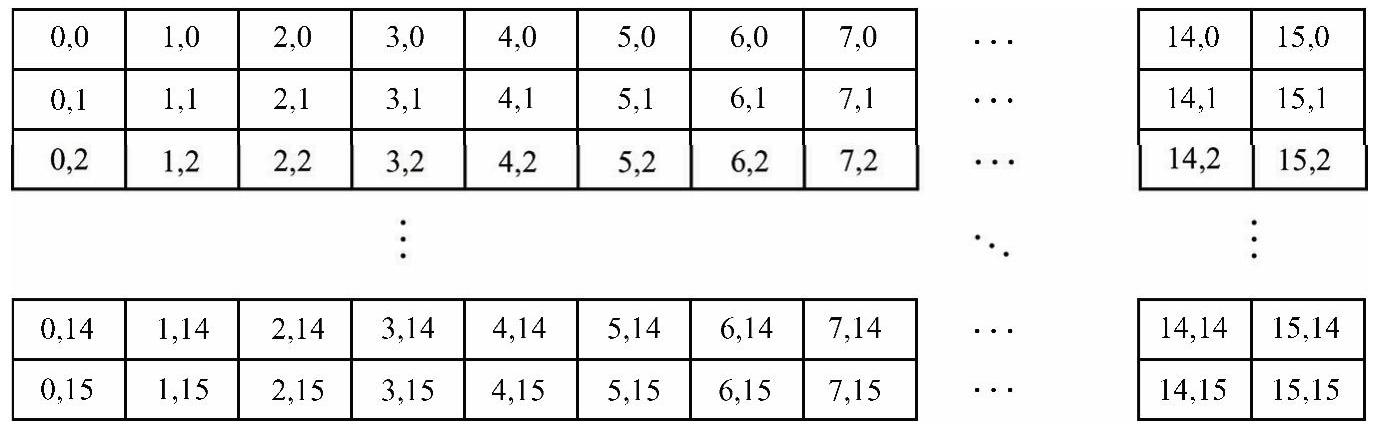
图4.11 大小为16×16的线程块

图4.12 MATLAB中显示的输入图像
出于演示的目的,首先将输入图像进行转置。这是因为来自MATLAB的输入图像是按列顺序存储的,然而在C/C++和CUDA中,图像是按行顺序存储的。然后,把线程块置于输入图像的顶部,看看这个原始图像是如何分为线程块和线程的,如图4.13所示。

图4.13 由线程块覆盖的输入图像
给定输入图像和线程块的大小,可以确定在水平和垂直方向上分别有多少线程块。注意到线程块覆盖的整个区域比输入图像大。这是因为所有的线程块应该是相同大小的,而图像的大小可能不是线程块大小的整数倍。因此,要使线程块覆盖的整个区域比输入图像大。

这一段代码展示了如何计算线程块的最小数量,这个数量必须是16的整数倍,且大于等于图片的大小。这里介绍两个dim3类型的变量blockSize和gridSize。
现在,通过线程指针和所分配线程块大小(每个像素对应一个线程),可以访问图像中的每个像素。当调用CUDA核函数时,可以知道哪个线程块中的哪个线程正在进行处理。在核函数中,使用以下CUDA的全局变量来找到确切的像素位置。
●blockDim:线程块的大小(例子中是16×16)。
●blockIdx:线程网格中线程块的索引。
●threadIdx:线程块中线程的索引。(https://www.xing528.com)
每个特定像素的位置可以用图4.14所示的变量计算。请再次注意,图像的行是水平表示的,而图像的列是垂直呈现的,因为在MATLAB中,图像是按列顺序存储的。
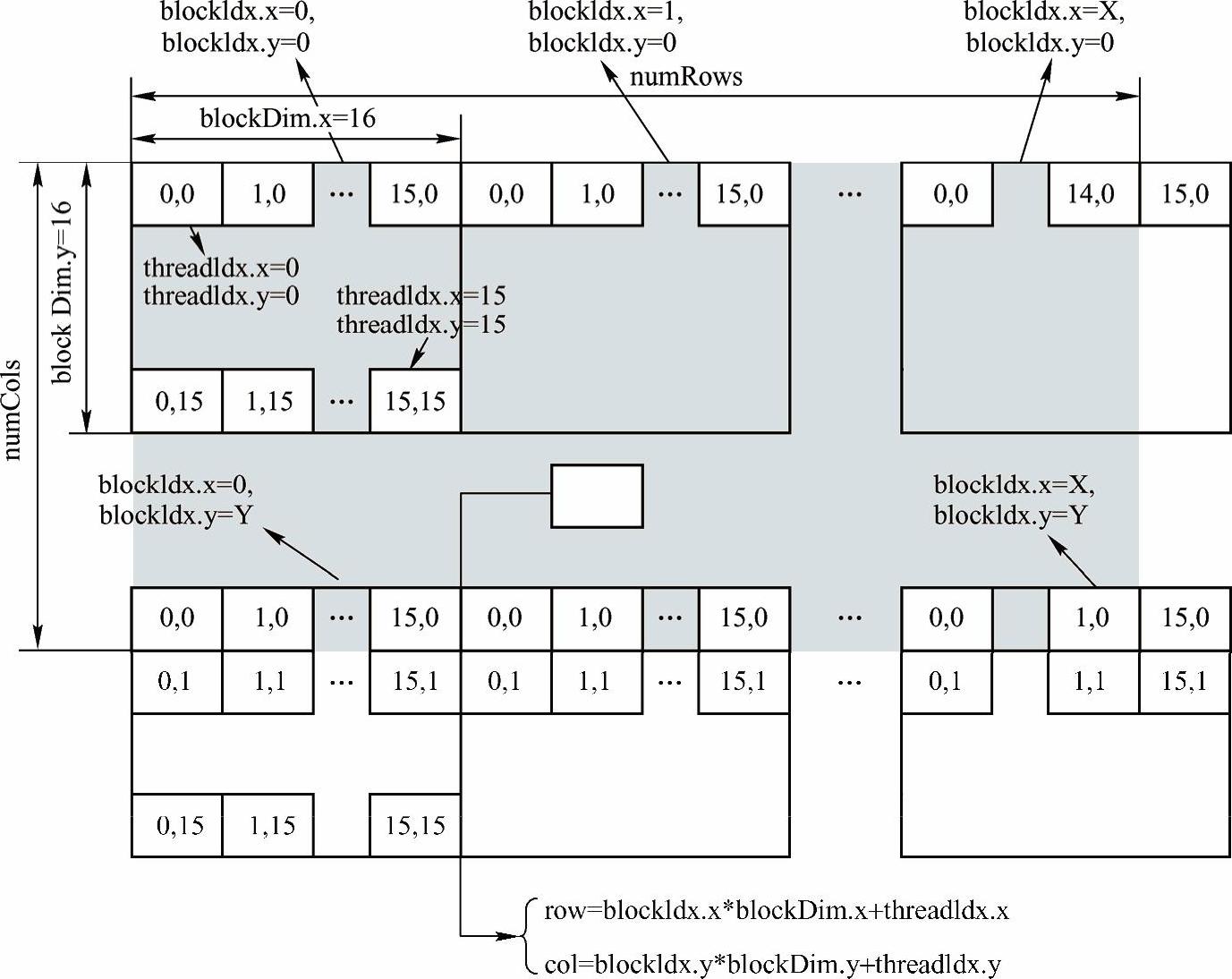
图4.14 分配给图像的线程块和线程
对于分配了图像以外像素的线程将直接返回,不进行任何处理。在本例中,也忽略了卷积操作的边界区域。在核函数中,通过如下方式检查操作是否在边界内进行:

现在创建一个新文件,并保存为conv2MexOptA.cu。


在这个范例代码中,创建了一个新的核函数并以如下方式调用它:

我们向核函数传送新的线程块和线程大小。与之前每个线程块中只处理一个像素的方法不同,这里将图像重组成16×16线程块,但是,与之前方法相同,每个线程执行3×3掩膜乘法和加法。
然后,利用NVIDIA Visual Profiler分析这个新方法。时间分析结果显示,新方法有了巨大的改善,运算速度相比之前的方法提高了30多倍,如图4.15所示。
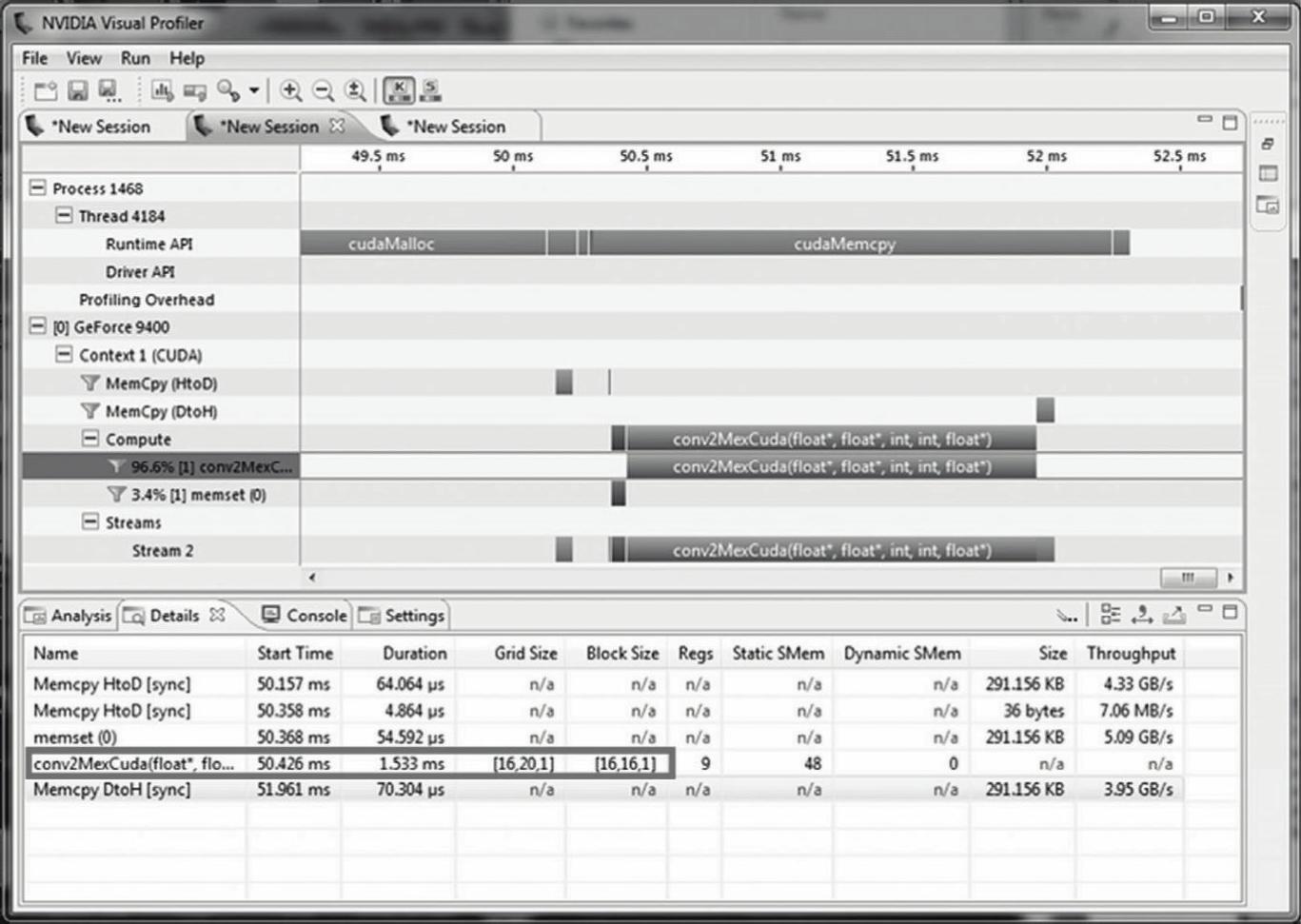
图4.15 采用新线程块大小优化后的卷积
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。