



新闻事件相关文档摘要隶属于自动文摘的范畴,但是与普通意义的自动文摘又有所不同,普通的自动文摘处理的对象非常广泛,在本文中仅以新闻报道为处理对象,既借鉴了普通的文摘生成方法,同时也兼顾了新闻报道本身所具有的特点。
自动文摘按照是否采用了基于语义的分析手段主要可分为两类:基于统计的机械文摘和基于意义的理解文摘。基于统计的机械文摘,其核心思想是:根据特殊的统计特征,计算每个语言单元(通常是句子)的重要度,最后将最重要的句子抽取出来,形成文摘。而基于意义的理解文摘则是用句法和语义知识等自然语言处理和领域知识,对文章的内容在理解的基础上提取文摘。基于意义的理解文摘与基于统计的机械文摘相比,其明显区别在于对知识的利用,它不仅利用语言学知识获取文章的语言结构,而且利用相关领域知识进行判断和推理,生成的文摘质量较好。但由于基于意义的方法受限于具体的领域,即移植性较差,很难把适用于某个领域的理解文摘系统推广到另一领域。另外基于意义的方法还需要表达和组织各种领域和背景知识,这常常会导致巨大的工作量,迄今为止进展甚微。所以现在主流的方法仍然是通过抽取重要句子来形成文档自动文摘。虽然这种方法不是最好,但是现在无论是从效率还是速度来看,仍然比较有效。基于句子抽取的文摘方法需要处理以下4个问题:
第一个问题是如何对候选句(最初为文中所有句子)的重要性进行排序。现在最常见的方法是用向量空间的方法计算组成句子的词语的重要性,或者是通过机器学习的方法。本文中,针对候选句的排序,则采用关键命名实体结合实体间关系的方法进行。关键命名实体是指与文章主题最相关的命名实体。
第二个问题是如何对候选重要句进行去重。一般方法是把每个句子用向量空间模型表示,句子之间的相似度用两个特征矢量之间的夹角余弦表示。这样计算相似度会把修饰成分计算在内,使得判断结果不够准确。因而在本文中,我们把每个句子去掉修饰成分,得到其主干,主要是由主动词及逻辑论元组成的。这样计算相似性既简单又有效。
第三个问题是如何排序输出重要句子,形成比较好的文档。一般情况下,单文档的文摘句子可以直接根据句子在原文中的位置输出。但是,对于多文档来说,不可能从一个文档中找到所有的文摘句,所以不能简单地按照单文档文摘的方法进行输出。我们提出了以一种基于基准文档的排序方法。
第四个问题是如何对文摘质量进行评价。学术界对自动摘要提出了许多评价方法,概括起来,可以分为两大类方法:内部评价和外部评价方法。内部评价方法是就一个独立的摘要系统,以某些性能标准对其本身进行评价,即通过一系列的参数直接分析摘要质量的好坏。这可以借助于用户对摘要的连贯程度以及包含多少原文章关键信息的判断,也可以比较自动摘要与“标准”摘要的相似程度。外部评价方法通过分析自动摘要对其他任务的完成质量的影响来评价,即在一组系统中,在摘要系统和其他系统,如检索系统、问题回答系统等进行相互作用的情形下,通过考察摘要系统与外部环境之间的联系进行评价。因为对中文自动文摘评测方法研究并不多,所以没有像ROUGE那样的评测系统可以用。所以本文中采用内部方法对实验结果进行评测。内部评价的一个关键问题是标准文摘的制定,为了减少标准文摘的主观性和不确定性,我们采用了统计模型,通过多个专家分别生成文摘,而不是只用一个专家生成的文摘。本文主要通过对比机器摘要和专家所做的标准文摘来评价所提摘要方法的性能。这个标准文摘是将几个专家对一篇文章手工做出的摘要进行综合平均,将得到的结果视为标准摘要。综合平均是指将各专家做出的摘要进行比较,从完全性、重复性和信息量等多个角度综合考虑,从而形成一篇标准摘要,也叫目标摘要。
1.方法主要框架
给定一个单文档,或者关于某个主题的一组相关文档。进行文摘的方法如图5-11所示。
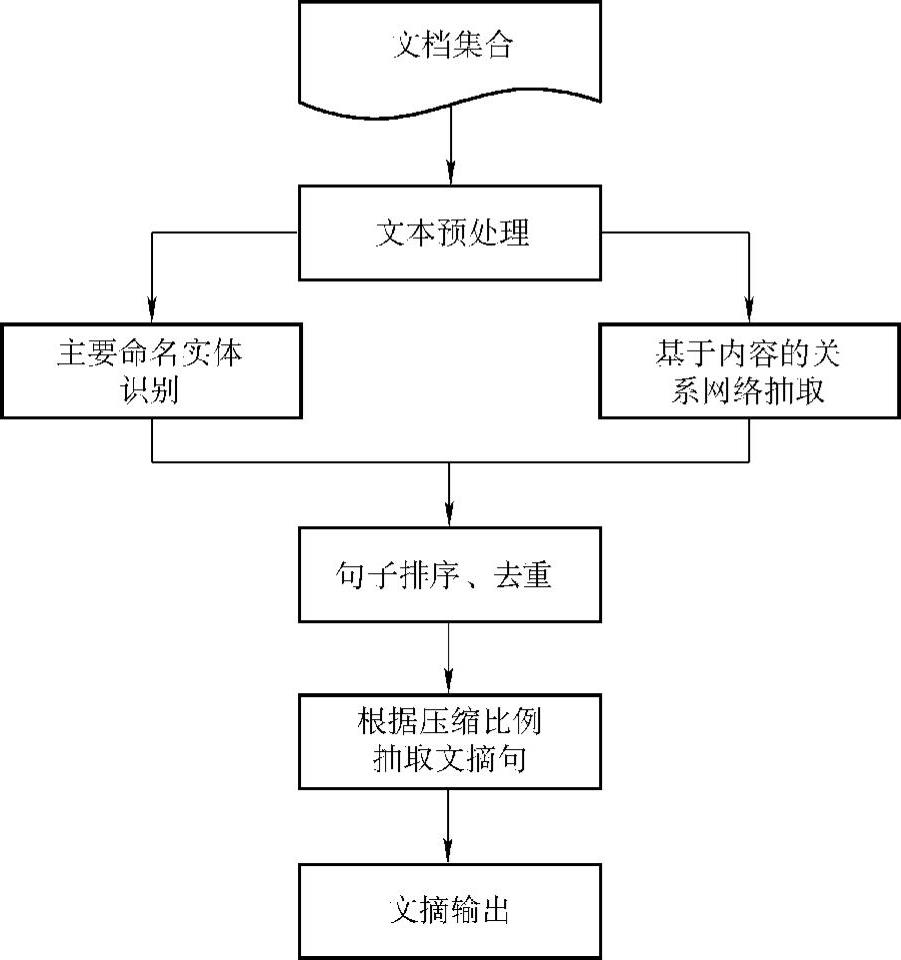
图5-11 基于关键词抽取的中文新闻文档自动文摘方法实现流程
(1)系统首先对输入文本进行分词标注、指代消解等预处理;
(2)然后利用机器学习的方法得到文中所有的关键命名实体;
(3)进行话语片断划分;
(4)利用基于规则的方法分析文章内容,得到文档中命名实体之间的关系网络和核心词;
(5)根据句子特征,实体特征,FNE、关系网络、主动词等综合信息,对文中话语片断句子进行去重、排序;
(6)最后根据摘要的压缩比例对文档中片断进行抽取;
(7)根据一个参考文档形成文摘输出。
文本预处理的方法与前一部分相同。此处我们着重强调关键命名实体的识别以及文摘的构成。
2.基于学习的关键命名实体识别(https://www.xing528.com)
关键命名实体是一篇文章中与主题最相关的命名实体。关键命名实体概念对文档理解具有很重要的意义,特别是新闻文档。因为新闻文档的特点:它的五要素基本上都属于命名实体的范围。实际上,很多研究中已经提出了命名实体对文档文摘很重要[76-79]。
关键命名实体识别可以看做一个二分类问题。考虑一个实体,通过一系列的特征来判断是否为关键命名实体,标注结果只有两种:“是”与“否”。此处我们输入文档可以是经过预处理的文档,标注,共指消解工作已经完成。
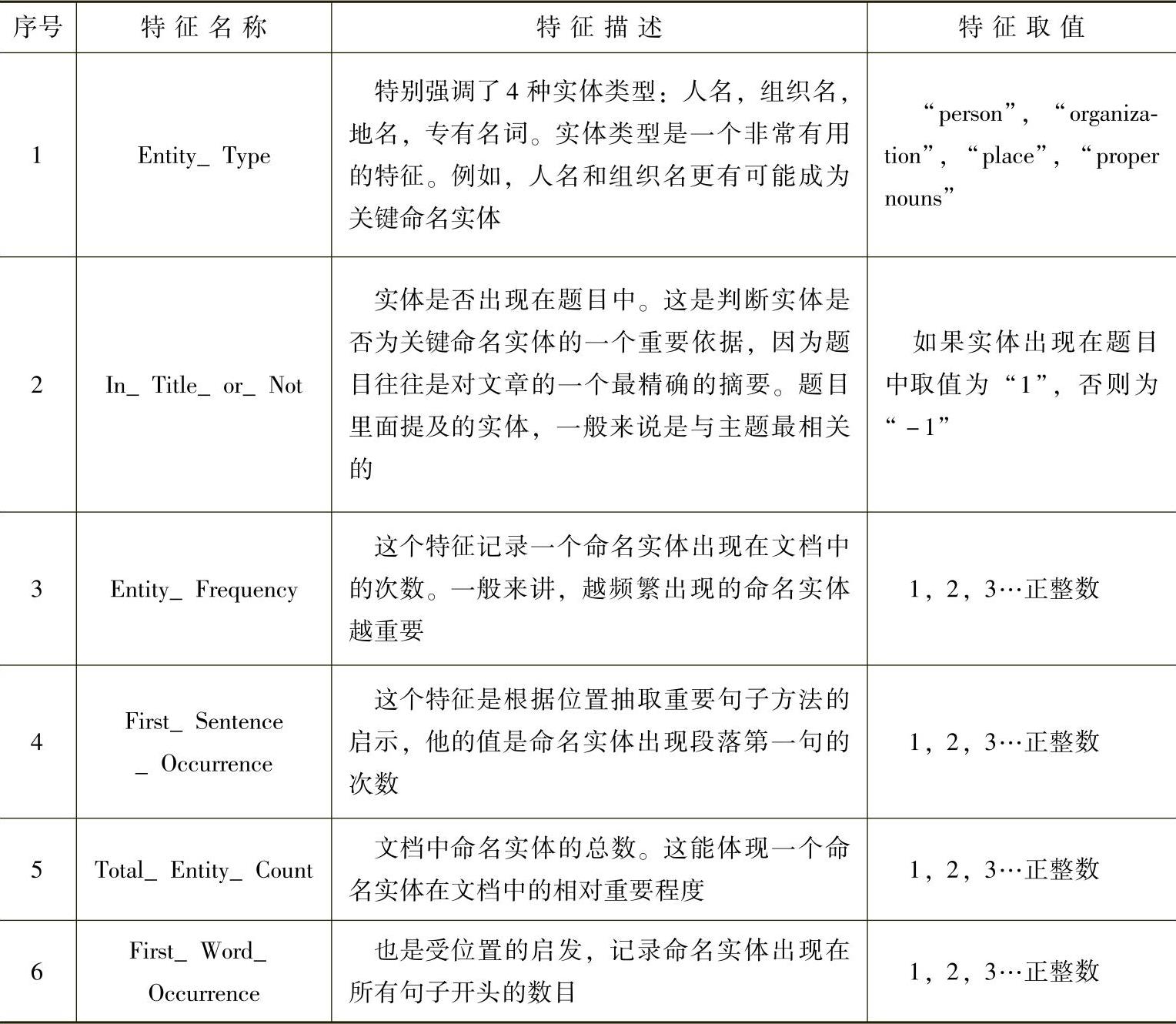
此处我们使用决策树C4.5[80]方法进行分类。学习阶段,每个实体看做是一个单独的学习实例。特征必须反映单个实体的特征。例如类型,频率等。表5-7列出了我们考虑的一些特征。
表5-7 关键命名实体识别特征定义
3.句子抽取
句子抽取包括两方面内容,一是句子重要性排序,二是去除冗余句子。
(1)句子重要性排序。针对候选句的排序,主要通过打分法进行。具体规则如下:
1)包含关键命名实体的句子比较重要,句子重要性分值加10,否则加0。此处取10是进行加权之后的数值,以此来平衡根据关系网络的加分标准。
2)另外一个标准是根据实体间关系。首先通过内容分析得到文档中包含的实体间关系网络,方法如前文所述,然后根据网络中点的出度、入度的大小对各个实体进行加分,从而对句子进行排序。句子分值为句子中实体的出度、入度大小之和。
3)标题是作者给出的提示文章内容的短语,包含标题中有效词(非停用词)的句子极有可能是对文章主题的叙述或总结,每包含一个有效词,其重要性值加1,否则加0。
4)线索词类似于“综上所述”、“由此可知”的线索词或短语大多出现在介绍或总结主题的句子中,因此需要提高包含线索词的句子的重要性,含有线索词的句子分值加5,否则加0。
5)美国P.E.Baxendale的调查结果显示:段落的论题是段落首句的概率为85%,是段落末句的概率为7%。因此,有必要提高处于特殊位置的句子的权值。段首句子重要性分值加2,段尾句加1,否则加0。
(2)句子去重。对任意两个句子判重时,首先把每个句子去掉修饰成分,得到其主干,主要是由主动词及逻辑论元组成的。判别步骤如下:首先判断两个句子中的逻辑论元是否相同,如果二者的逻辑论元不完全相同,那么两个句子不为冗余句;如果所有逻辑论元都相同,则进一步根据主动词进行判断,如果主动词语义相同,则认为两个句子为冗余。此处对主动词的语义相似性判断根据同义词词典得到。
4.输出摘要
输出文摘句,形成摘要包括两个方面的内容。第一是单文档摘要的输出,第二是多文档摘要的输出。
(1)单文档摘要形成:根据文摘句在原文中的位置顺序输出形成文摘文档。
(2)多文档摘要形成:首先把文摘句子集合与所有原文档进行比较,把包含文摘句子最多的文档作为基准文档。然后把文摘句集合与基准文档依次进行比较,对于基准文档中存在的句子,则按照它们在文中出现的顺序先后进行排序,对于没有在文中出现的句子,则查找基准文档中是否存在与之相似的句子,假如存在,则按照相似语句与其他语句之间的关系进行排序,对于在基准文档中找不到相似句子的句子,则按照重要程度,放在与其具有相同施事论元的句子附近。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。