



利用搜索引擎检索人物信息是互联网用户的主要活动之一。然而现实世界中,多个人物共享一个人名是很普遍的现象。这导致搜索引擎对某一特定人名的检索结果往往是共享这一人名的不同人物相关网页的混合。例如,百度检索“王刚”返回的前10个结果中就有“国家著名演员”、“中央政治局委员”、“西北工业大学副教授”、“山东黄金篮球队队员”、“建筑师”、“中国作家协会会员”等6位不同的人物。重名消解就是根据上下文或篇章信息来区分同一人名表示的不同人物的过程。
虽然现在有些系统能对检索结果进行聚类处理,例如iBoogied、SnakeT、Vivisimo、Apex搜索、Bbmao等,但它们都把人名当成普通词汇进行处理,聚类结果的标签也是这个人名相关的一些词汇,没有对人名的重名结果进行区分。现在尚未完全公开的Spoek系统检索人名时能够找出重名的不同人物,但这个系统不是针对搜索引擎检索结果进行处理,而是通过不同途径抓取并索引了超过1亿人的相关资料,在检索时根据同名人物的个人信息来实现重名消解。同时,这个系统只能检索英文人名,不支持中文人名。
人名检索结果的重名消解,可以采用类似于自然语言处理中词义消歧的方法,利用人名的上下文信息来实现。常见的方法将人名检索结果对应的Snippet或者网页内容采用向量空间模型表示,或者抽取上下文中的关键性短语,然后采用计算向量相似度的方法来实现最终的检索结果聚类。更为深入的方法是在网页中抽取人物的相关信息,例如性别、民族、籍贯、出生年月、家庭关系、住址、职务等,然后在人物属性集上计算人物的相似度,从而实现人物同一性判别。
对于检索结果的重名消解,基于文本聚类的方法考虑了很多无用词汇,而且需要人工设定阈值或者类别数量;基于信息抽取的人物相关属性相似度的方法对于人物信息的抽取具有很大的依赖性,各种属性在抽取时的错误容易导致错误级联。针对这些问题,提出了基于社会网络的人名检索结果重名消解方法。主要依据是“物以类聚,人以群分”,即重名的不同人物所属的社会网络具有区分性。例如演艺圈的“王刚”和政界的“王刚”在社会网络上是明显不同的。本文利用检索结果背后潜在的社会网络关系来解决检索结果重名问题。与参考文献[5]和[6]不同的是,本方法针对中文人名进行处理,并采用了不同的社会网络构建方法,而且结合谱分割和模块度的方法能自动确定最优的类别数量。
整个系统处理流程主要分为三步:
(1)社会关系获取。在检索结果中抽取全部人名来构建同一人名的初始社会网络,并对其中各个子图进行拓展,使得有所关联的离散的社会网络连接起来。(https://www.xing528.com)
(2)社会网络聚类。在拓展后的社会网络图上采用图分割的算法来实现自顶向下的图聚类算法,结合模块度的评价指标自动得到局部社会圈子。
(3)社会网络映射。将形成的各个局部社会圈子映射回到最早检索人名的Snippet上,从而实现检索结果的重名消解。系统框架如图5-6所示。
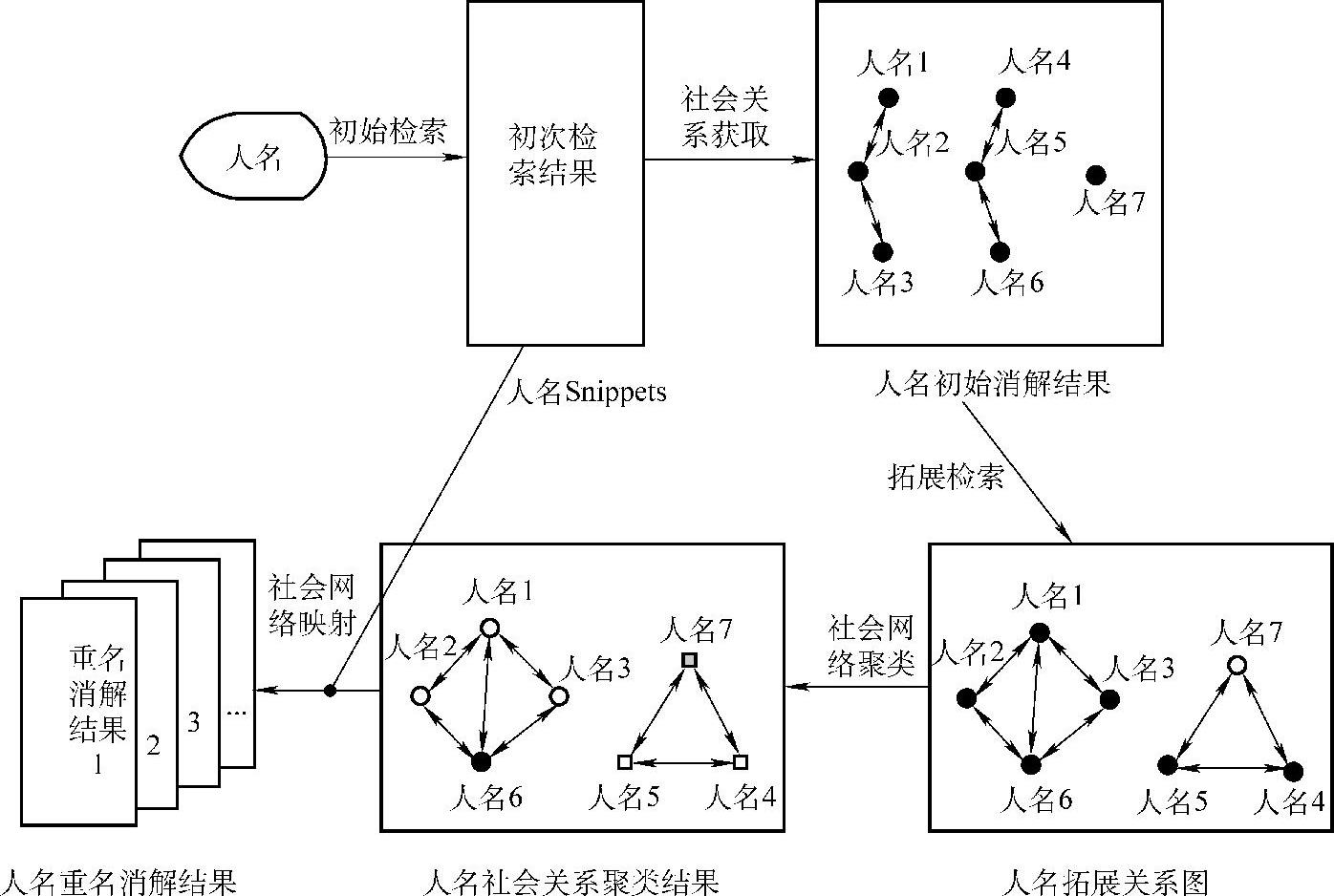
图5-6 重名消解系统框架图
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。