



在文本挖掘过程中,文本的特征表示是整个挖掘过程的基础,而关联分析、文本分类、文本聚类是三种最主要也是最基本的功能。下面,以文本特征表示和文本挖掘的三种核心功能为线索,对文本挖掘的研究现状和已经取得的成果作简单总结。
1.文本特征表示
传统数据挖掘所处理的数据是结构化的,其特征通常不超过几百个,而非结构化或者半结构化的文本数据转换成特征向量后,特征数可能高达几万甚至几十万。所以,文本挖掘面临的首要问题是如何在计算机中合理的表示文本。这种表示法既要包含足够的信息以反映文本的特征,又不至于太过庞大使学习算法无法处理。这就涉及文本特征的抽取和选择。
文本特征指的是关于文本的元数据,可以分为描述性特征,如文本的名称、日期、大小、类型以及语义性特征,如文本的作者、标题、机构、内容、描述性特征较容易获得,而语义性特征较难获得。在文本特征表示方面,内容特征是被研究的最多的问题。
当文本内容被简单地看成由它所包含的基本语言单位(字、词、词组或短语等)组成的集合时,这些基本的语言单位被称为项(Term)。如果用出现在文本中的项表示文本,那么这些项就是文本的特征。
对文本内容的特征表示主要有布尔模型、向量空间模型、概率模型和基于知识的表示模型。因为布尔模型和向量空间模型易于理解且计算复杂度较低,所以成为文本表示的主要工具。
(1)特征抽取。中文文档中的词与词之间不像英文文本那样具有分隔符,因此中、英文文本内容特征的提取步骤略有不同,如图2-7所示。
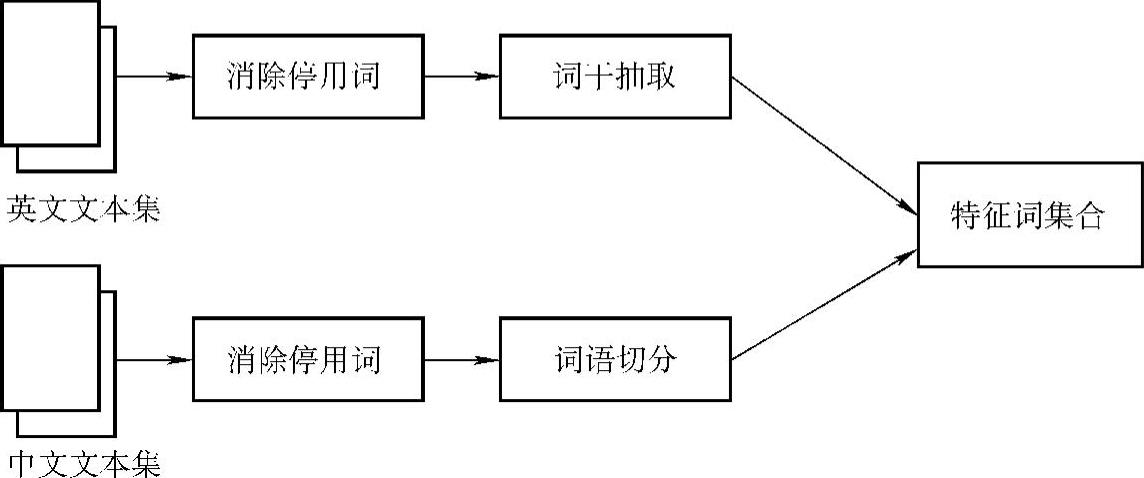
图2-7 中、英文文本特征抽取的一般过程
1)消除停用词:文本集有时包含一些没有意义但使用频率极高的词。这些词在所有文本中的频率分布相近,从而增加了文本之间的相似程度,给文本挖掘带来一定困难。解决这个问题的方法是用这些词构造一个停用词表或禁用词表(stop word list)[33],在特征抽取过程中删去停用词表中出现的特征词。
常见的停用词包括虚词和实词两种,如:
①虚词:英文中的“a,the,of,for,with,in,at…”;
中文中的“的,地,得,把,被,就…”。
②实词:数据库会议上的论文中的“数据库”一词,可视为停用词。
2)词干抽取:令V(s)是由彼此互为语法变形词组成的非空词集,V(s)的规范形式称为词干(stem)。
例如,如果V(s)={connected,connecting,connection,connections},那么s=connect是V(s)的词干。
词干抽取(stemming)有四种不同的策略:词缀排除(affix removal)、词干表查询(table lookup)、后继变化(successor variety)和N-gram。其中词缀排除最直观、简单且易于实现。多数词的变形是因添加后缀引起的,所以在基于词缀排除策略的摘取算法中后缀排除最为重要,Porter算法[34]是后缀排除算法中最常用的一种。
词干抽取将具有不同词缀的词合并成一个词,降低文本挖掘系统中特征词的总数,从而提高了挖掘系统的性能。
当然,也有两点需要注意:
①词干抽取对文本挖掘性能的提高仅在基于统计原理的各种分析和挖掘技术下有效。在进行涉及语义和语法的自然语言处理时,不适宜采用词干抽取技术。
②词干抽取对文本挖掘或信息检索准确性的影响至今没有令人信服的结论,因此许多搜索引擎和文本挖掘系统不使用任何词干抽取算法。
3)汉语切分:汉语的分词问题已经基本解决,并出现了多种分词方法。这些分词方法可以分为两类:一类是理解式分词法,即利用汉语的语法知识、语义知识及心理学知识进行分词;另一类是机械式分词法,一般以分词词典为依据,通过文本中的汉字串和词表中的词逐一匹配完成词语切分。第一类分词方法算法复杂,实际应用中经常采用的是第二类分词方法。机械式分词法主要有正向最大匹配法,逆向最大匹配法,逐词遍历法。
由于词典的容量有限,在大规模真实文本处理中,会遇到许多词典中未出现的词,即未登录词。未登录现象是影响分词准确率的重要原因。为解决这个问题,人们提出利用N-gram语言模型进行词项划分[35],从而摆脱基于词典的分词方法对词典的依赖。与基于词典的分词方法不同,基于N-gram技术得到的词项不一定具有实际意义。
例如:“文本挖掘”的所有N-gram项为
1-gram:文,本,挖,掘
2-gram:文本,本挖,挖掘
3-gram:文本挖,本挖掘
4-gram:文本挖掘
其中除1-gram是单字外,2-gram中的“本挖”,3-gram中的“文本挖”,“本挖掘”都不具有实际意义。
(2)特征选择。特征选择也称特征子集选择或特征集缩减。经过特征抽取获得的特征词数量很多,有时达数万个特征。如此多的特征对许多文本挖掘方法,如文本分类、聚类、文本关联分析来说未必都是有意义的;而过大的特征空间还会严重影响文本挖掘的效率,因此选择适当的特征子集十分必要。
通常采用机器学习的方法进行文本特征选择。虽然机器学习中有许多选取特征子集的算法,但有些办法复杂且效率低下,不适于处理庞大的文本特征集。国外对特征选择方法的研究较多,特别是已有专门针对文本分类特征选择方法的比较研究[36]。国内对这一问题的研究以跟踪研究为主,集中在将国外现有特征评估函数用于中文文本特征选择[37]及对其进行改进。
2.基于关键字的关联分析
文本数据一旦被转化为结构化中间形式后,这种中间形式就作为文本挖掘过程的基础。
与关系数据库中关联规则的挖掘方法类似,基于关键词的关联规则产生过程包括两个阶段:
(1)关联挖掘阶段:这一阶段产生所有的支持度大于等于最小支持阈值的关键词集,即频繁项集。
(2)规则生成阶段:利用前一阶段产生的频繁项集构造满足最小置信度约束的关联规则。(https://www.xing528.com)
Feldman等人实现了基于上述思想的文本知识发现系统KD、FACT,表2-5给出KDT系统在Reuter22173语料集中发现的关联规则。
表2-5 文本关联规则示例

3.文本分类
文本分类是文本挖掘中一项非常重要的任务,也是国内外研究较多的一种挖掘技术。在机器学习中将分类称作有监督学习或有教师归纳,其目的是提出一个分类函数或分类模型,该模型能把数据库中的数据项映射到给定类别中的一个。
一般来说,文本分类需要四个步骤:
(1)获取训练文本集:训练文本集由一组经过预处理的文本特征向量组成,每个训练文本(或称训练样本)有一个类别标号。
(2)选择分类方法并训练分类模型:文本分类方法有统计方法、机器学习方法、神经网络方法等。在对待分类样本进行分类前,要根据所选择的分类方法,利用训练集进行训练并得出分类模型。
(3)用导出的分类模型对其他待分类文本进行分类。
(4)根据分类结果评估分类模型。
另外需要注意的是,文本分类的效果一般和数据集本身的特点有关。有的数据集包含噪声,有的存在缺失值,有的分布稀疏,有的字段或属性间相关性强。目前,普遍认为不存在某种方法能适合各种特点的数据。
随着因特网技术的发展和普及,在线文本信息迅速增加,文本分类成为处理和组织大量文本数据的关键技术。而近20多年来计算机软、硬件技术的发展和自然语言处理、人工智能等领域的研究进展为文本自动分类提供了技术条件和理论基础。迄今为止,文本分类研究已经取得了很大的进展,提出了一系列有效的方法,其中分类质量较好的有k-最近邻(k-Nearest Neighbor,kNN)、支持向量机(Support Vector Machine,SVM)、朴素贝叶斯(Naive Bayes,NB)。
国内对中文文本自动分类的研究起步较晚,尽管已有一些研究成果[38,39],但由于尚没有通用的标准语料和评价方法,很难对这些成果进行比较。而对基于关联规则的文本分类的研究在国内还未见到。
4.文本聚类
文本聚类是根据文本数据的不同特征,将其划分为不同数据量的过程。其目的是要使同一类别的文本间的距离尽可能小,而不同类别的文本间的距离尽可能的大。主要的聚类方法有统计方法、机器学习方法、神经网络方法和面向数据库的方法。在统计方法中,聚类也称为聚类分析,主要研究基于几何距离的聚类。在机器学习中聚类称作无监督学习或者无教师归纳。聚类学习和分类学习的不同主要在于:分类学习的训练文本或对象具有类标号,而用于聚类的文本没有类标号,由聚类学习算法自动确定。
传统的聚类方法在处理高维和海量文本数据时的效率不很理想,原因是:
(1)传统的聚类方法对样本空间的搜索具有一定的盲目性;
(2)在高维很难找到适宜的相似度度量标准。
虽然,文本聚类用于海量文本数据时存在不足。但与文本分类相比,文本聚类可以直接用于不带类标号的文本集,避免了为获得训练文本的类标号所花费的代价。根据聚类算法无需带有类标号样本这一优势,Nigam等人提出从带有和不带有类标号的混合文本中学习分类模型的方法[40]。其思想是利用聚类技术减少分类方法对有标号训练样本的需求,减轻手工标记样本类别所需的工作量,这种方法也称为半监督学习。
文本聚类包括以下四个步骤:
(1)获取结构化的文本集。结构化的文本集由一组经过预处理的文本特征向量组成。从文本集中选取的特征好坏直接影响到聚类的质量。如果选取的特征与聚类目标无关,那么就难以得到良好的聚类结果。对于聚类任务,合理的特征选择策略是使同类文本在特征空间中相距较近,异类文本相距较远。
(2)执行聚类算法,获得聚类谱系图。聚类算法的目的是获取能够反映特征空间样本点之间的“抱团”性质。
(3)选取合适的聚类阈值。在得到聚类谱系图后,领域专家凭借经验,并结合具体的应用场合确定阈值。阈值确定后,就可以直接从谱系图中得到聚类结果。
目前,常见的聚类算法可以分为以下几类:
1)平面划分法:对包含n个样本的样本集构造样本集的k个划分,每个划分表示一个聚簇。常见的划分聚类算法有k-均值算法,k-中心点算法,CLARANS算法。
2)层次聚类法:层次聚类法对给定的样本集进行层次分解。根据层次分解方向的不同可以分为凝聚层次聚类和分裂层次聚类。凝聚法也称为自底向上的方法,如AGNES;分裂法也称自顶向下的方法,如DIANA、CURE、BIRCH、Cha-meleon。
3)基于密度的方法:多数平面划分法使用距离度量样本间的相似程度。因此只能发现球状簇,难以发现任意形状簇。基于密度的聚类法根据样本点临近区域的密度进行聚类,使在给定区域内至少包含一定数据的样本点。DBSCAN就是一个具有代表性的基于密度的聚类算法。
(4)基于网格的方法:采用多分辨率的网格数据结构,将样本空间量化为数量有限的网格单元,所有聚类操作都在网格上进行,如STING算法。
(5)基于模型的方法:为每个簇假定一个模型,然后通过寻找样本对给定模型的最佳拟合行聚类。
有些聚类算法集成多种算法的思想,因此难以将其划归到上述类别中的一类,如CLIQUE综合了密度和网格两种聚类方法。
文本聚类有着广泛的应用,比如可以用来:
(1)改进信息检索系统的查全率和查准率;
(2)用于文本集浏览;
(3)搜索引擎返回的相关文本的组织;
(4)自动产生文本集的类层次结构。在带有类标号的文本集上发现自然聚类,然后利用自然聚类改进文本分类器。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。