



1.基础研究,机器翻译的兴起:20世纪40年代末至50年代初期
自然语言理解领域的研究最早可以追溯到第二次世界大战结束时,那个时代刚发明了计算机。由于计算机能够进行符号处理,使得自然语言理解和处理成为可能。理论方面,有两项基础性的研究值得注意:一项是自动机的研究,另一项是概率或信息论模型的研究。这些早期的研究工作为后来形式语言理论(Formal Language Theory)的产生奠定了基础。
机器翻译是自然语言理解最早的研究领域,1949年,美国工程师W.Weaver发表了一份以《翻译》为题的备忘录,正式提出了机器翻译问题。同一年,美苏两国开始俄—英和英—俄语言之间的机器翻译研究。1954年,美国乔治敦大学在国际商用机器公司(IBM公司)的协同下,用IBM-701计算机,进行了世界上第一次机器翻译试验,把几个简单的俄语句子翻译成英语。接着,苏联、英国、日本也进行了机器翻译试验,机器翻译出现热潮。早期机器翻译系统的研制受到韦弗思想的很大影响,许多机器翻译研究者都把机器翻译的过程与解读密码的过程相类比,试图通过查询词典的方法来实现词对词的机器翻译,因而译文的可读性很差,难于付诸实用。
2.机器翻译的没落,两个阵营,第一代系统:20世纪50年代末期至1970年
在1950~1965年,机器翻译几乎成了所有自然语言处理系统的中心课题,早期机器翻译系统未获成功是因为没有尝试理解它所翻译的内容究竟是什么,所以机器输出的新语言不能精确复述源语言的同样意义。1966年在美国科学院发表的一篇题为《语言与机器》的报告,简称ALPAC报告,对机器翻译采取否定的态度。报告宣称:“在目前给机器翻译以大力支持还没有多少理由”;报告还指出,机器翻译研究遇到了难以克服的“语义障碍”(semantic barrier),认为全自动机译在较长时期内不会取得成功。此后世界范围内的机器翻译研究工作进入低潮。
在这个时期,自然语言处理明显分成两个阵营:一个是符号派(symbolic),一个是随机派(stochastic)。符号派即我们所说的“理性主义”,他们采用基于规则的分析方法,着重研究推理和逻辑问题。随机派即我们所说的“经验主义”,他们主要针对大规模语料库,着重研究随机和统计算法。
符号派的研究工作可以分为两个方面。一方面,N.Chomsky等对形式语言理论和生成句法的研究,并于1957年提出了转换生成语法理论(Transformation Generative Grammar)。同时,很多语言学家和计算机科学家进行了剖析算法研究,Zelig Harris的TDAP系统是最早的完整剖析系统。另一方面,很多人工智能研究者着重研究推理和逻辑,典型的例子是Newell和Simon关于“逻辑理论家”和“通用问题解答器”。
随机派主要是一些来自统计学专业和电子学专业的研究人员。在20世纪50年代后期,贝叶斯方法开始用于解决最优字符识别问题。Bledsoe和Browning建立了用于文本识别的贝叶斯系统。Mosteller和Wallace用贝叶斯方法来解决文章中的原作者的分布问题。60年代还出现了第一个联机语料库:Brown美国英语语料库,语料是布朗大学在1963~1964年收集的。
受到当时计算机性能制约,经验主义在20世纪50年代末到60年代初几乎被否定。
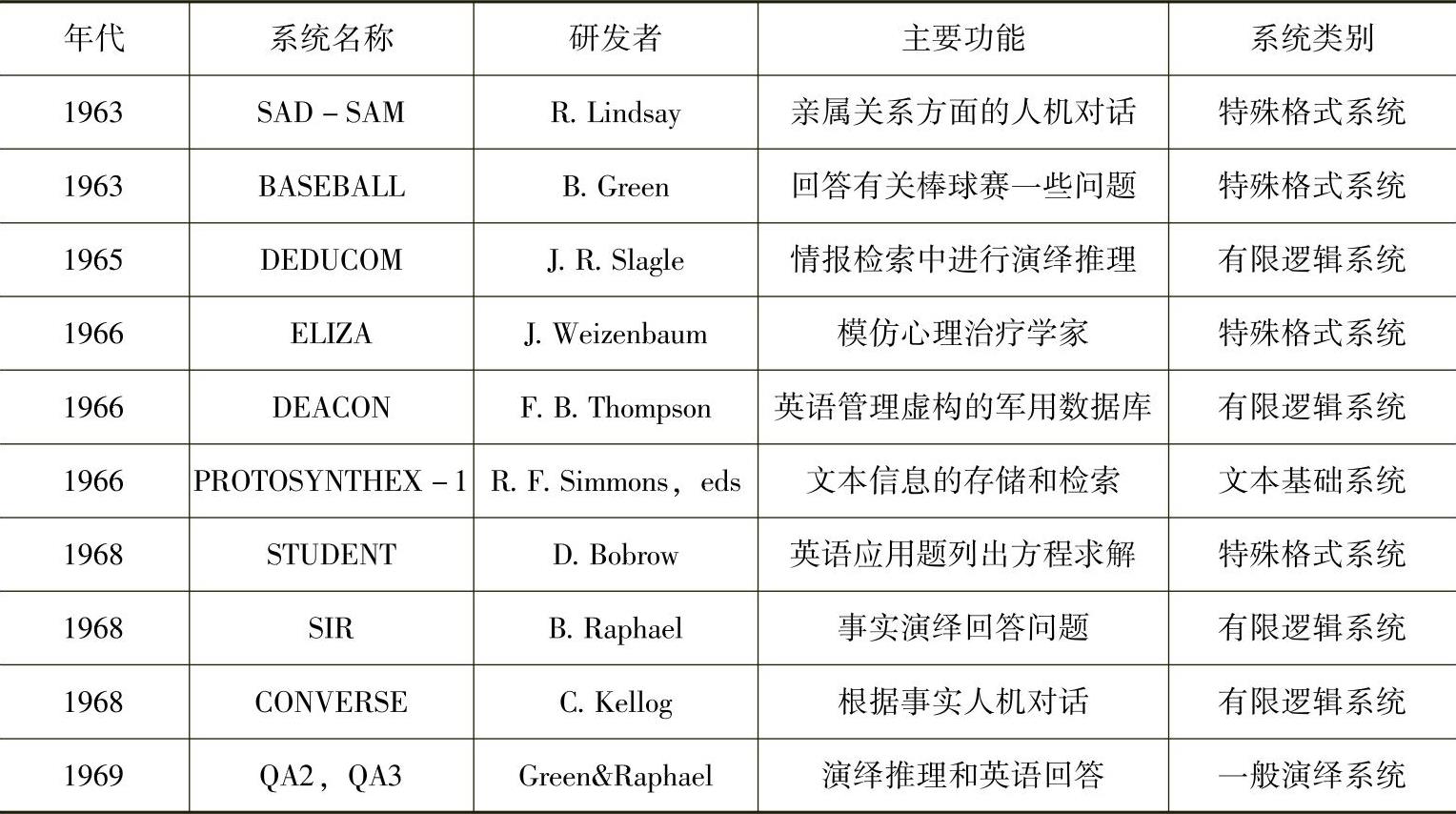
这一时期,由于N.Chomsky在语言学理论上的突破,以及高级程序设计语言和表处理语言的出现,在60年代中期,人工智能学者开发了一批新的计算机程序进行简单的机器自然语言理解。这些早期系统称为“第一代系统”,一些有代表性的系统见表2-1。它们把模式匹配和关键词搜索与简单试探的方法结合起来,进行推理和问题自动回答,它们都只能接受英语的一个很强的受限子集,在受限的专门领域内达到有限的目标。语法分析尚不成熟,语义和语用分析还未涉及。
表2-1 第一代系统
3.理性主义和第二代系统:20世纪70~80年代
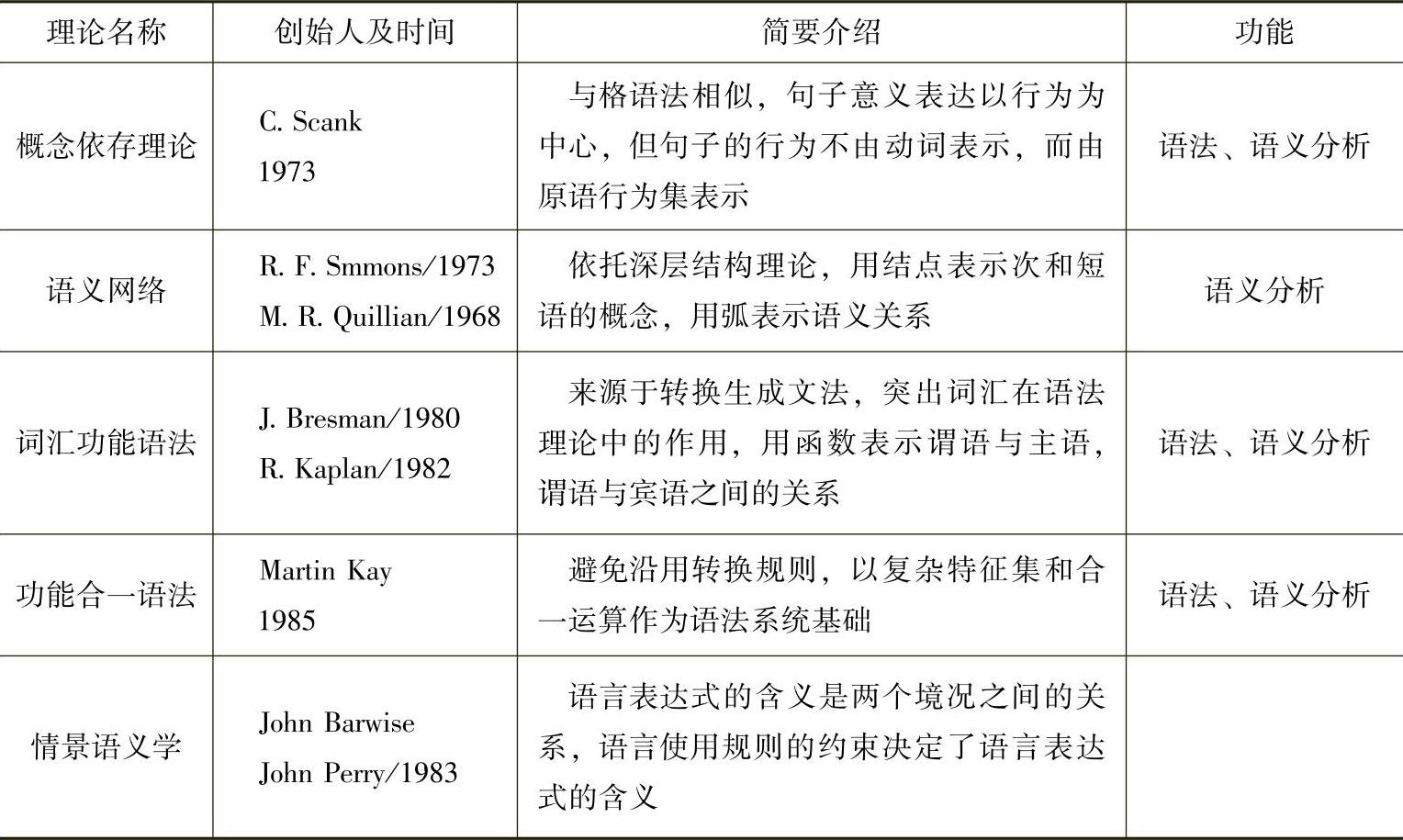
这一时期理性主义占据了绝对的上风,几乎完全抛开了统计技术。语法分析方面,出现了更适宜句法分析的扩充转移网络(Augment Transition Network ATN)。语义分析方面,由于认识到N.Chomky的生成语法缺少表示语义知识的手段,在20世纪70年代随着认知科学的兴盛,研究者又相继提出了语义网络(Semantic Network)、概念依存理论(Conceptual Dependency Theory)、格语法(Case Grammar)等语义表示理论。这些语法和语义理论经过各自的发展,逐渐开始趋于相互结合。到了80年代,一批新的语法理论脱颖而出,具有代表性的有词汇功能语法(LFC,Lexical Functional Grammar)、功能合一语法(GUG,Functional Unification Grammar)和广义短语结构语法(GPSG,Generalized Phrase Structure Grammar)等。随后语用分析也开始展开,情景语义学(Situation Se-mantics)、言谈语言学(Discourse Linguistics)和语用学(Pragmatics)成为研究热点。表2-2简要介绍了这些理论成果。
表2-2 “理性主义”理论成果表

(续)
 (https://www.xing528.com)
(https://www.xing528.com)
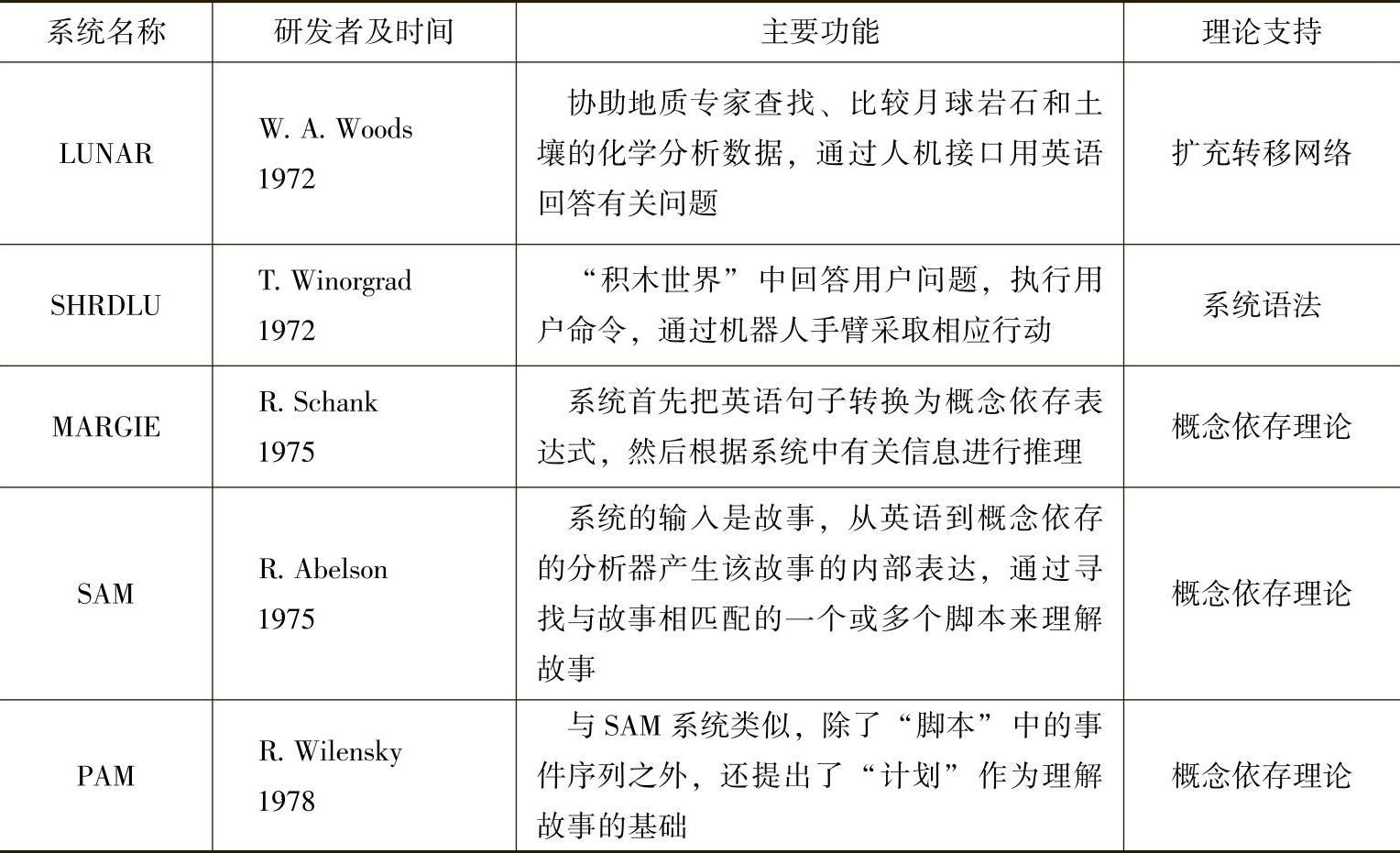
依托于当时的语法和语义理论研究,研究者们开发了一大批著名的系统,如LUNAR系统、SHRDLU系统、MARGIE系统、SAM系统、PAM系统等。它们被称为第二代系统。这些系统绝大多数是程序演绎系统,大量地进行语义、语境以至语用的分析。表2-3简要介绍了第二代系统中具有代表性的重要成果。
表2-3 第二代系统表
4.经验主义复苏,实用化系统开发:20世纪80年代中期至90年代中期
到了20世纪80年代,一方面由于计算机技术的飞速发展,大规模数据存入计算机并加以处理成为可能;另一方面也是对旧方法的深刻反思,出现了“重回经验主义”的倾向。
单纯采用基于规则的自然语言理解系统,主要缺陷表现在:
(1)规则所能刻画的知识颗粒度太大;
(2)不能保证语言学规则之间的相容;
(3)获取语言学和世界知识非常困难。
正是因为上述原因,人们开始转向大规模语料库,试图从中获取颗粒度较小的语言知识来支持大规模真实文本的自然语言处理系统。语料库的建设和语料库语言学(Corpus Linguistics)成为计算语言学的新的研究分支迅速崛起。概率模型和其他数据驱动的方法被广泛应用到词类标注、句法剖析、附着歧义的判定等研究中去。国外学术界利用这种方法已取得实质性的进展,1994年IBM的Adam L.Berger等人发表了题为“The Candidate System Of Machine Translation”的文章,称为“统计翻译”。该系统历时5年,完成从法语翻译成英语的任务,准确率超过美国著名的SYSTRAN系统,使国际计算语言学界为之震动。表2-4列举了世界上一些著名的语料库项目。
表2-4 世界著名语料库项目表

此外,自然语言理解的研究从20世纪50年代开始一直到70年代,可以说基本上停留在实验和纯理论的探讨阶段。到了80年代,由于计算机硬件技术飞速发展和自然语言理解的理论水平的提高,自然语言理解的应用研究广泛展开,机器翻译研究又活跃起来,并出现了许多具有较高水平的实用化系统。其中比较著名的有美国METAL和LOGOS,日本的PIVOT和LOGOS,法国的ARIANE,德国的SUSY等。
5.合流,新突破,新挑战:20世纪90年代中后期至今
“理性主义”现有的手段虽然基本上掌握了单个句子的分析技术,但是还很难覆盖全面的语言现象,特别是对于整个段落或篇章的理解还无从下手。统计方法的引入推动了自然语言理解研究的步伐,但是几年过去了,也同样没有看到近期能有重大突破的迹象。“经验主义”对于语言中基本的确定性的规则仍然用统计强度的大小去判断,这与人们的常识相违背。“经验主义”研究中的不足要靠“理性主义”的方法来弥补,统计和规则相结合成为这一时期的主流研究方法。这类方法中出现了两个比较有代表性的动向:一个是以宾州大学Macus为代表的把语料库内容的结构化,即树库(Tree Bank)的方法和以Xtag为代表的词汇树邻接文法;另一个是以AT&T的Abney为代表的加大语言处理单元的粒度,即语段(Chunk)的思想。
这一时期,在实用系统开发方面也有了新的突破,由于计算机的速度和存储量的增加,使得自然语言处理的一些子领域,特别是在语音识别、拼写检错、语法检查这些子领域,有可能进行商品化的开发。
另外,Web的发展使得基于语言的信息检索和信息抽取的需求变得更加突出。基于Web的语料库建设也成为热点。20世纪末国际互联网语言工程产品作为一种新的产业在这个世界上开始崛起。但是总的说来,知识表示和知识处理问题在20世纪之前都没有在根本上有所突破。21世纪将是自然语言理解学界迎接新挑战,解决新问题,寻求突破的全新时代。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。