



进入“作业”(Job)功能模块后,主菜单中的Job菜单及工具区中第一行的“创建作业”(Create Job)工具和“作业管理器”(Job Manager)工具用于作业的创建和管理。
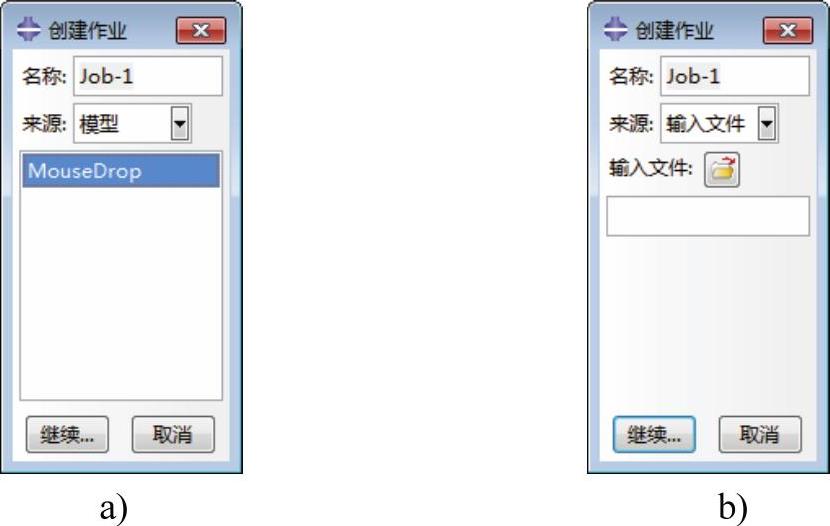
图8-3 “创建作业”对话框
a)来源为“模型” b)来源为“输入文件”
单击工具区中的 (创建作业,Create Job)工具,或选择“作业(Job)→创建(Create)”命令,弹出“创建作业”(Create Job)对话框,如图8-3所示。该对话框包括两个部分:
(创建作业,Create Job)工具,或选择“作业(Job)→创建(Create)”命令,弹出“创建作业”(Create Job)对话框,如图8-3所示。该对话框包括两个部分:
名称(Name):在该栏内输入作业的名称,默认为Job-n(n表示第n个创建的作业)。
来源(Source):该列表用于选择作业的来源,包括“模型”(Model)和“输入文件”(Input file)。
默认选择为“模型”(Model),其下部列出该CAE文件中包含的模型,如图8-3a所示。用户需要从该列表中选择用于创建作业的模型。
若用户选择“输入文件”(Input file),则可以单击按钮选择用于创建作业的.inp文件,或在其下的空格内输入,如图8-3b所示。
设置完成后,单击“继续”(Continue)按钮,弹出“编辑作业”(Edit Job)对话框,如图8-4所示,用户需要在该对话框中进行分析作业的编辑。
“编辑作业”对话框包含如下内容。
描述(Description):该栏用于输入对该分析作业的简单描述,并保存在结果数据库中,进入“可视化”(Visualization)模块后显示在标题区。该栏非必选项,用户可以不对分析作业进行描述。
■“提交”(Submission)选项卡,如图8-4a所示,用于设置分析作业的提交参数。
●作业类型(Job Type):该栏用于选择分析作业的类型。
 完全分析(Full analysis):此为默认选项,对模型执行一个完整的分析,将分析结果写入到输出数据库。
完全分析(Full analysis):此为默认选项,对模型执行一个完整的分析,将分析结果写入到输出数据库。
 恢复(Explicit)(Recover(Explicit)):完成一个ABAQUS/Explicit意外停止的分析,仅适用于ABAQUS/Explicit。
恢复(Explicit)(Recover(Explicit)):完成一个ABAQUS/Explicit意外停止的分析,仅适用于ABAQUS/Explicit。
 重启动(Restart):该选项用于完成一个重启动分析。重启动分析需要的文件包括输出数据库文件(job_name.odb)、重启动文件(job_name.res)、模型文件(job_name.mdl)、部件信息文件(job_name.prt)、状态外文件(job_name.stt),ABAQUS/Explicit分析还需要状态文件(job_name.abq)、打包文件(job_name.pac)和结果选择文件(job_name.sel)。用户可以在“分析步”模块设置重启动信息的写入频率,默认情况下,对于ABAQUS/Standard分析,无重启动信息的写入;对于ABAQUS/Explicit分析,仅在分析步的开始和结束时写入重启动信息。用户不能对来自.inp文件的分析作业进行重启动分析。
重启动(Restart):该选项用于完成一个重启动分析。重启动分析需要的文件包括输出数据库文件(job_name.odb)、重启动文件(job_name.res)、模型文件(job_name.mdl)、部件信息文件(job_name.prt)、状态外文件(job_name.stt),ABAQUS/Explicit分析还需要状态文件(job_name.abq)、打包文件(job_name.pac)和结果选择文件(job_name.sel)。用户可以在“分析步”模块设置重启动信息的写入频率,默认情况下,对于ABAQUS/Standard分析,无重启动信息的写入;对于ABAQUS/Explicit分析,仅在分析步的开始和结束时写入重启动信息。用户不能对来自.inp文件的分析作业进行重启动分析。
●运行模式(Run Mode):该栏用于选择运行模式。
 Background:此为默认选项,ABAQUS在后台运行分析。
Background:此为默认选项,ABAQUS在后台运行分析。
 队列(Queue):该栏用于选择已定义的批处理队列提交分析作业。
队列(Queue):该栏用于选择已定义的批处理队列提交分析作业。
●提交时间(Submit Time):该栏用于选择运行分析的时间。
 立即(Immediately):此为默认选项,分析作业立即在后台被执行或立即被提交到批处理队列。
立即(Immediately):此为默认选项,分析作业立即在后台被执行或立即被提交到批处理队列。
 等待(Wait):在指定的等待时间后运行分析。该选项仅在UNIX操作系统下可用,且仅适用于后台运行模式(Background)。
等待(Wait):在指定的等待时间后运行分析。该选项仅在UNIX操作系统下可用,且仅适用于后台运行模式(Background)。
 指定(At):在指定的时间运行分析。对于后台运行模式(Background),该选项仅在UNIX操作系统下可用。(https://www.xing528.com)
指定(At):在指定的时间运行分析。对于后台运行模式(Background),该选项仅在UNIX操作系统下可用。(https://www.xing528.com)
■“通用”(General)选项卡(如图8-4b所示)用于指定一些分析作业设置。
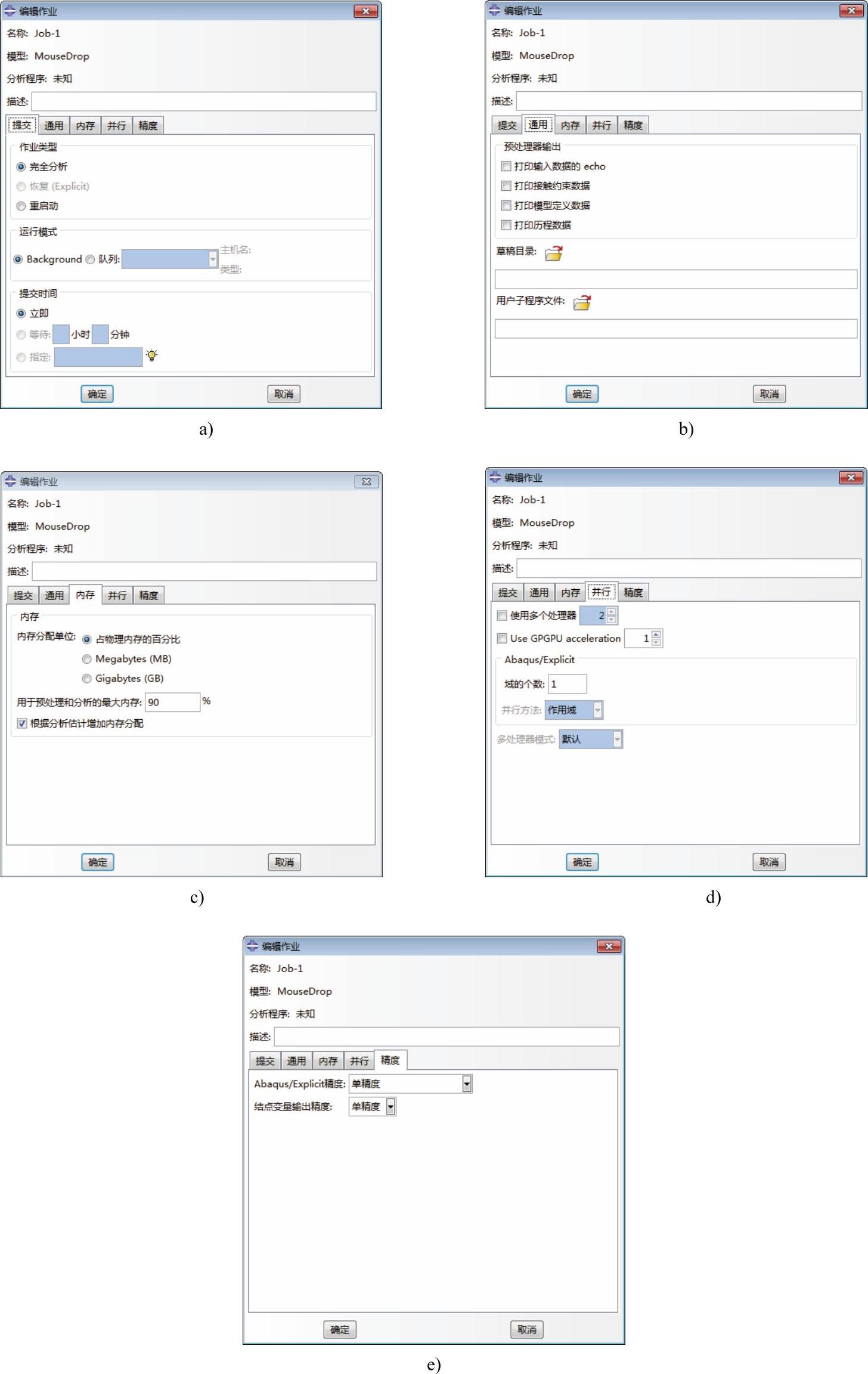
图8-4 “编辑作业”对话框
a)“提交”选项卡 b)“通用”选项卡 c)“内存”选项卡 d)“并行”选项卡 e)“精度”选项卡
●预处理器输出(Preprocessor Printout):该栏用于选择预处理打印输出。ABAQUS会将用户选择的项输出到数据文件(job_name.dat)中。对于来自.inp文件的分析作业,用户需要在.inp文件中指定预处理打印输出。
●草稿目录(Scratch directory):选择用于保存分析过程中临时文件的文件夹。
●用户子程序文件(User subroutine file):该栏用于选择包含用户子程序的文件。
■“内存”(Memory)选项卡如图8-4c所示,用于指定分配到分析中的内存。
●内存分配单位:用于指定分配内存的方式。
■占物理内存百分比:用于预处理和分析的最大内存占计算机物理内存的百分比。
■Megabytes(MB):以MB为单位定义用于预处理和分析的最大内存。
■Gigabytes(GB):以GB为单位定义用于预处理和分析的最大内存。
●根据分析估计增加内存分配:勾选该项后,当分析需要,有可能超出用户定义的内存分配。
■“并行”(Parallelization)选项卡如图8-4d所示,用于并行运算的设置。
●使用多个处理器(Use multiple processors):选择用于分析的处理器数目,默认值为“1”,即不使用并行运算。
●Use GPGPU acceleration:使用GPGPU加速。
■Abaqus/Explicit:该栏用于选择ABAQUS/Explicit分析的设置。
■域的个数(Number of domains):该栏用于输入域的数目。
■并行方法(Parallelization method):该栏用于选择并行方法,包括“作用域”(Domain,拓扑域并行)和“循环”(Loop,循环级并行)。
●多处理器模式(Multi-processing mode):该列表用于选择多处理器模式,包括“默认”(Default,基于执行分析的平台)、“线程”(Threads,多线程方式)和MPI(消息传输平台),其中后两种模式仅适用于拓扑域并行(Domain)。
■“精度”(Precision)选项卡,如图8-4e所示,用于精度的控制。
●Abaqus/Explicit精度(ABAQUS/Explicit precision):该列表用于选择ABAQUS/Explicit分析的精度,包括“单精度”、“强制关闭”、“两者-只分析”、“两者-只约束”和“两者-分析+packager”。
●结点变量输出精度(Nodal output precision):该列表用于选择结点输出的精度,包括“单精度”(Single)和“完全”(Full)。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。