



1.为什么要加末笔字型识别码
构成汉字的基本字根之间存在着一定的位置关系。例如:同样是“口”与“八”这两个字根,它们的位置关系不同,就构成“叭”与“只”两个不同的字。字根“口”的代码为K,“八”的代码为W,这两个字的编码为
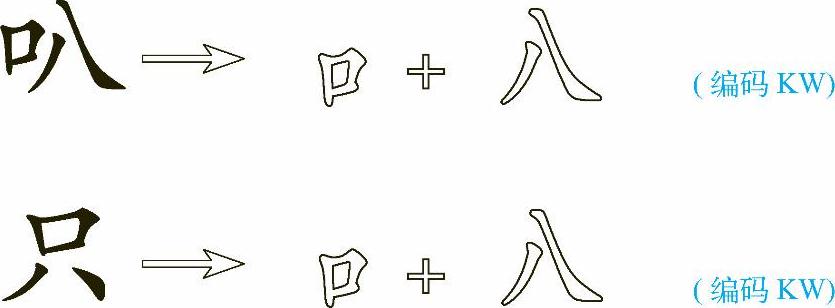
两个字的编码完全相同,因此出现了重码。可见,仅仅将汉字的字根按书写顺序输入到计算机中还是不够的,还必须告诉计算机输入这些字根是以什么方式排列的,计算机才能认定选的是哪个字。若用字型加以区别,则是
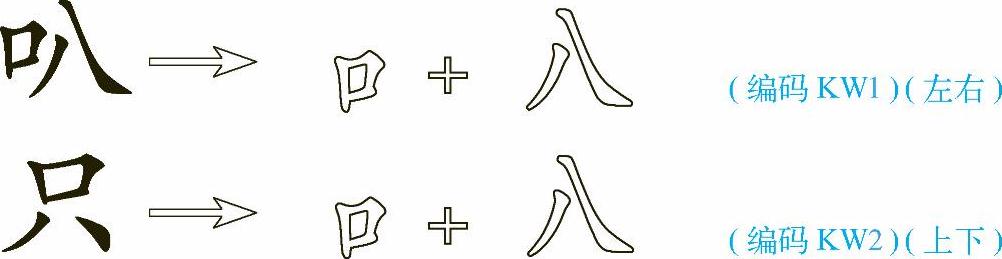
于是,这两字的编码就不会相同了,最后加的叫字型识别码。
但还有一些字,它们的字根在同一个键上而且字型又相同,如“沐、汀、洒”是由“氵”和<S>键上“木、丁、西”3个字根组成的,它们又都是左右型汉字,若用字型识别码加以区别,则是

上面3个字虽然字根拆分不同,但它们的第二部分字根都在同一个键上(<S>键)。如果分别加一个字型识别码,由于3个字都是左右(1)型,还是出现了重码。因此,仅将字根按书写顺序输入到计算机中,再用字型识别码加以区别,也还是不够的,还必须告诉计算机输入的这些字根各有什么特点。若用末笔画识别码加以区别,则变成:

这样就使处在同一键上的3个字根在和其他字根构成汉字时,具有了不同的编码。最后一笔叫做末笔识别码。
综上所述,为了避免出现重码,有的时候需要加字型识别码,有的时候又要加末笔识别码;如果以末笔画为准,以字型识别码(1,2,3)作为末笔画的数量,就构成“末笔字型识别码”。如:“字”的末笔画为横,它是上下(2)型字,则“字”的末笔识别码为两横(二)。“团”的末笔画为撇,它是杂合(3)型字,则“团”的末笔识别码为三撇(彡)。追加末字型识别码后,重码的概率会大量减少,汉字的输入效率也大大提高。
末笔字型识别码见表6-6。末笔字型识别码的键盘分布如图6-13所示。
表6-6 五笔字型末笔字型识别码表

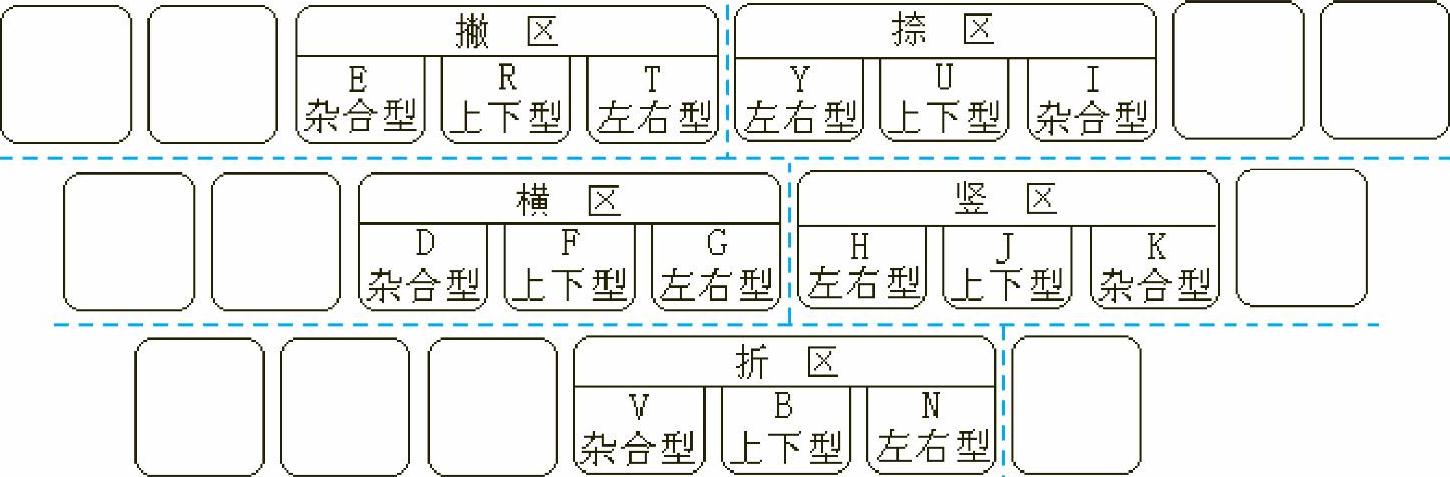
图6-13 识别码键盘分布图
2.末笔字型识别码的判定
加识别码的目的是为了减少重码数,提高汉字的输入效率。下面将介绍一种简单的确定识别码的方法。这种方法读者不需要学区位号的概念,就可以轻松掌握识别码的应用,而且简单快捷。
识别码共15个符号,输入时,只打圈里边的笔画键就行了。外带圆圈只是为了便于与真正的笔画相区别。下面举例说明。(https://www.xing528.com)
1)对于1型(左右型)字,输入完字根之后,补打1个末笔画即等于加了“识别码”。如:
腊,月 日 (末笔为“一”,1型,补打“
(末笔为“一”,1型,补打“ ”)
”)
蜊,虫 禾 刂 (末笔为“丨”,1型,补打“
(末笔为“丨”,1型,补打“ ”)
”)
泸,氵 尸
尸 (末笔为“丿”,1型,补打“
(末笔为“丿”,1型,补打“ ”)
”)
诔,讠 二 木 (末笔为“、”,1型,补打“
(末笔为“、”,1型,补打“ ”)
”)
礼,礻 乙
乙 (末笔为“乙”,1型,补打“
(末笔为“乙”,1型,补打“ ”)
”)
2)对于2型(上下型)字,输入完字根之后,补打由两个末笔画复合而成的“字根”即等于加了“识别码”。如:
娄,米 女 (末笔为“一”,2型,扑打“
(末笔为“一”,2型,扑打“ ”)
”)
弄,王 廾 (末笔为“丨”,2型,补打“
(末笔为“丨”,2型,补打“ ”)
”)
参,厶 大 彡 (末笔为“丿”,2型,补打“
(末笔为“丿”,2型,补打“ ”)
”)
彖,

 (末笔为“、”,2型,补打“
(末笔为“、”,2型,补打“ ”)
”)
号,口 一 乙 (末笔为“乙”,2型,补打“
(末笔为“乙”,2型,补打“ ”)
”)
3)对于3型(杂合型)字,输入完字根之后,补打由3个末笔画复合而成的“字根”即等于加了“识别码”。如:
同,冂 一 口 (末笔为“一”,3型,补打“
(末笔为“一”,3型,补打“ ”)
”)
乎,丿 丷 十 (末笔为“丨”,3型,补打“
(末笔为“丨”,3型,补打“ ”)
”)
户,丶 尸 (末笔为“丿”,3型,补打“
(末笔为“丿”,3型,补打“ ”)
”)
还,丆 卜 辶 (末笔为“、”,3型,补打“
(末笔为“、”,3型,补打“ ”)
”)
虎,虍 几 (末笔为“乙”,3型,补打“
(末笔为“乙”,3型,补打“ ”)
”)
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。