



Kibana是一个日志聚合展示的可视化Web工具,可以在Kibana中查看单条日志的情况,可以根据特定条件聚合某类日志信息,从而实现饼图等可视化视图的分析展示。Kibana的安装请参看第19章,本节介绍Kibana的几种基本使用方法。
(1)基本配置
使用Docker安装Kibana需要注意ElasticSearch的地址,如果使用了错误的地址会出现如图18-2所示的错误提示信息。
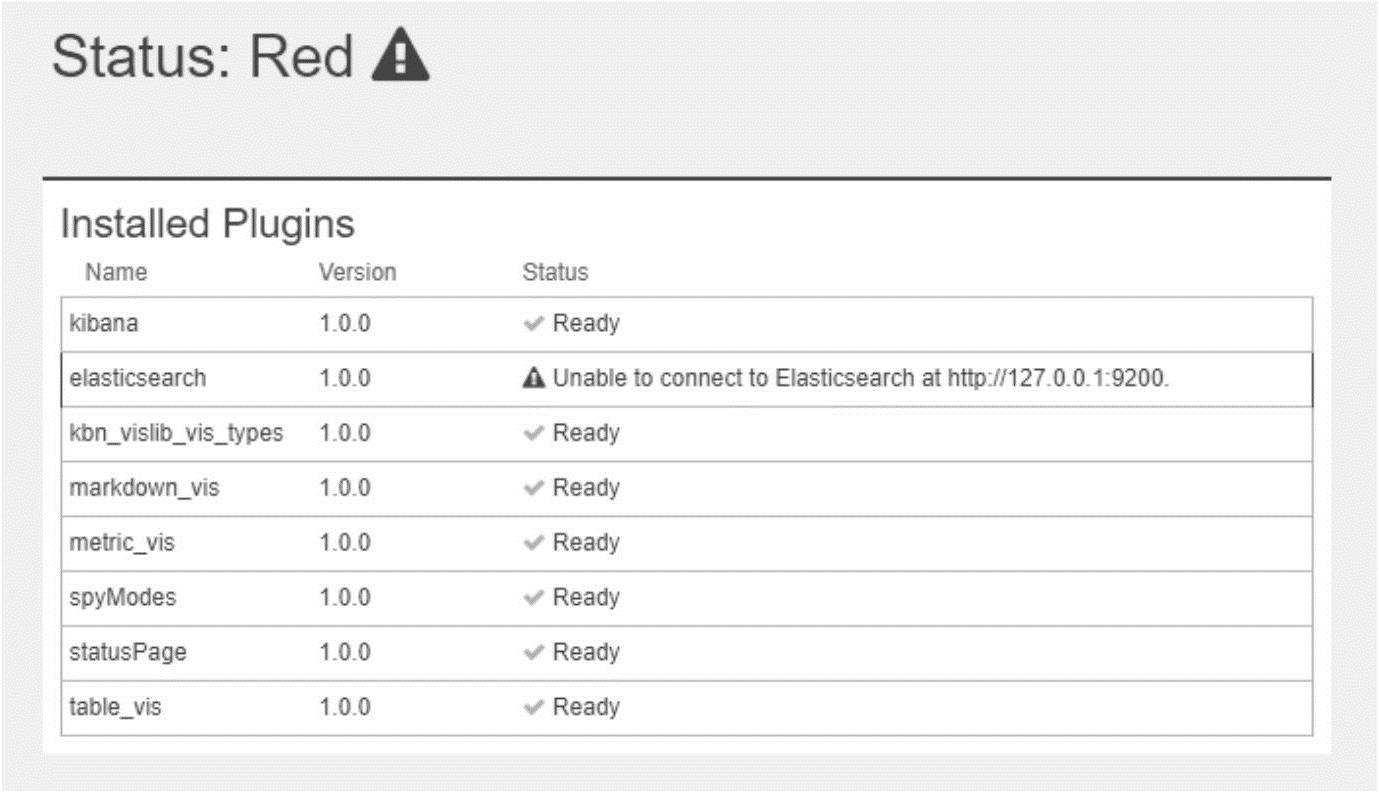
图18-2 Kibana配置错误提示
正确配置ElasticSearch地址,并且进入Kibana之后,可以在“Settings”选项中选择要检索的index,本节使用正则匹配“logstash-*”,如图18-3所示。
(2)简单搜索
在Kibana中,进入“Discover”页签,可以在输入框输入简单的查询条件,并且在右上角配置正确的时间维度,Kibana会根据查询条件进行搜索,并且在搜索到的内容中对搜索关键词高亮显示,如图18-4所示。
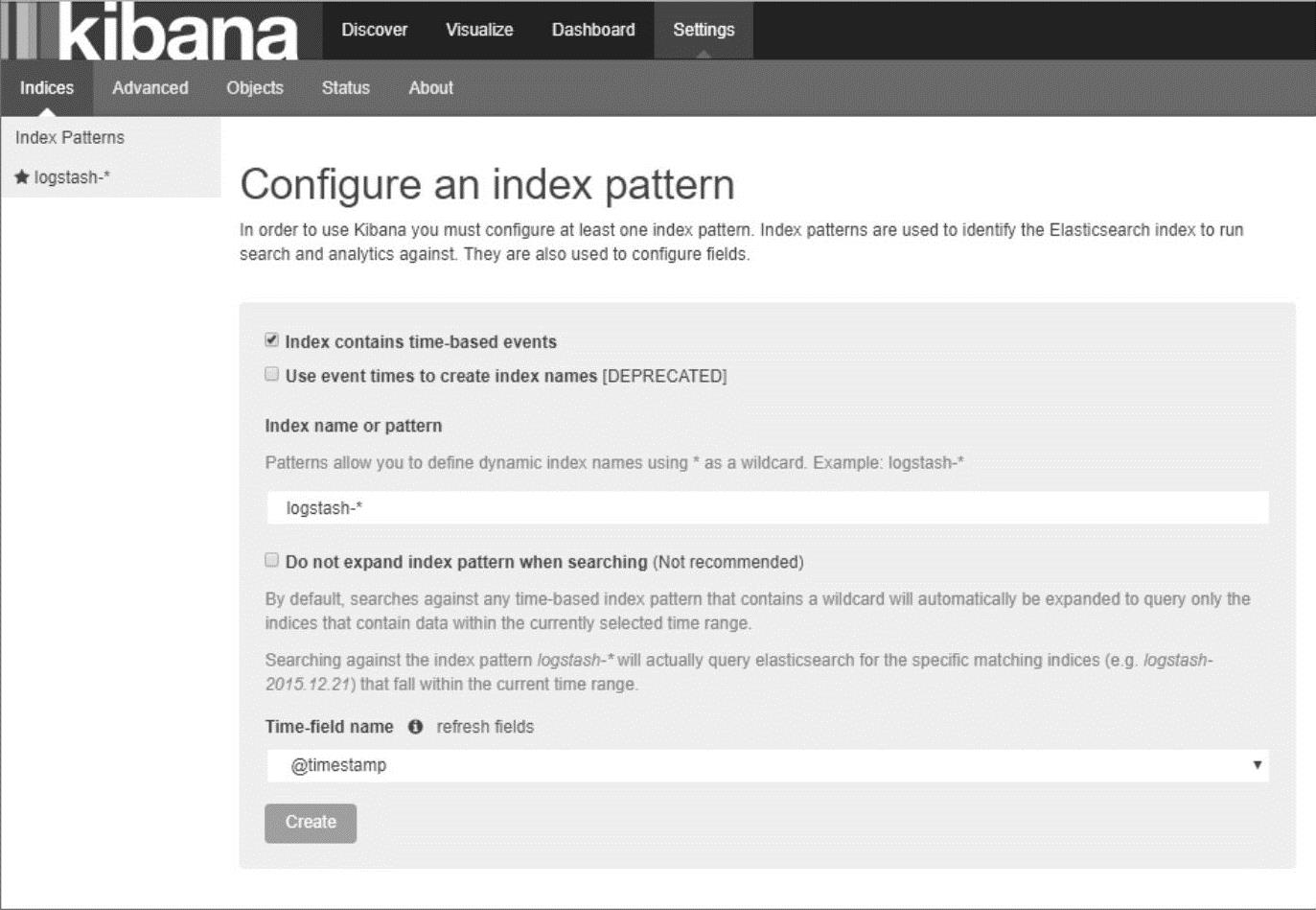
图18-3 Kibana起始页面
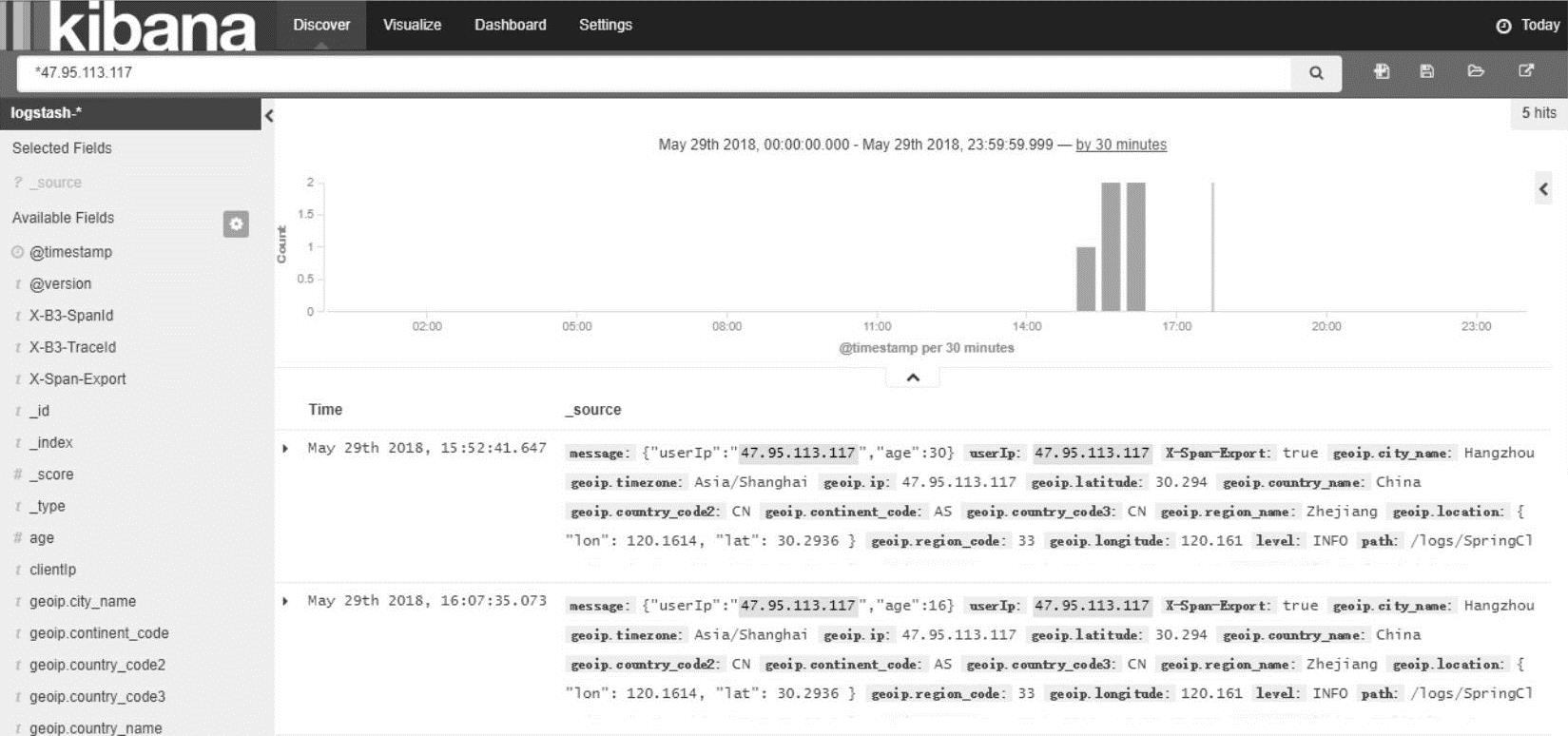
图18-4 Kibana搜索
(3)制作简单的饼图
如果想查看某种数据的分布比例情况,可以制作一个饼图。例如查看用户的年龄分布情况,可以选择“Visualize->Pie chart->From a new search”,然后配置检索的数据项和展示的个数,点击执行按钮后就可以看到统计情况,如图18-5所示。
(4)双层饼图
可以在饼图的基础上,选择子分析项,从而形成双层的饼图。在图18-5的左下方,点击“add sub-buckets”,再次输入一个分析条件,可以看到效果如图18-6所示。
可以选择保存此图片,在页面的右上方有一个保存按钮,点击此按钮,输入信息并保存即可。
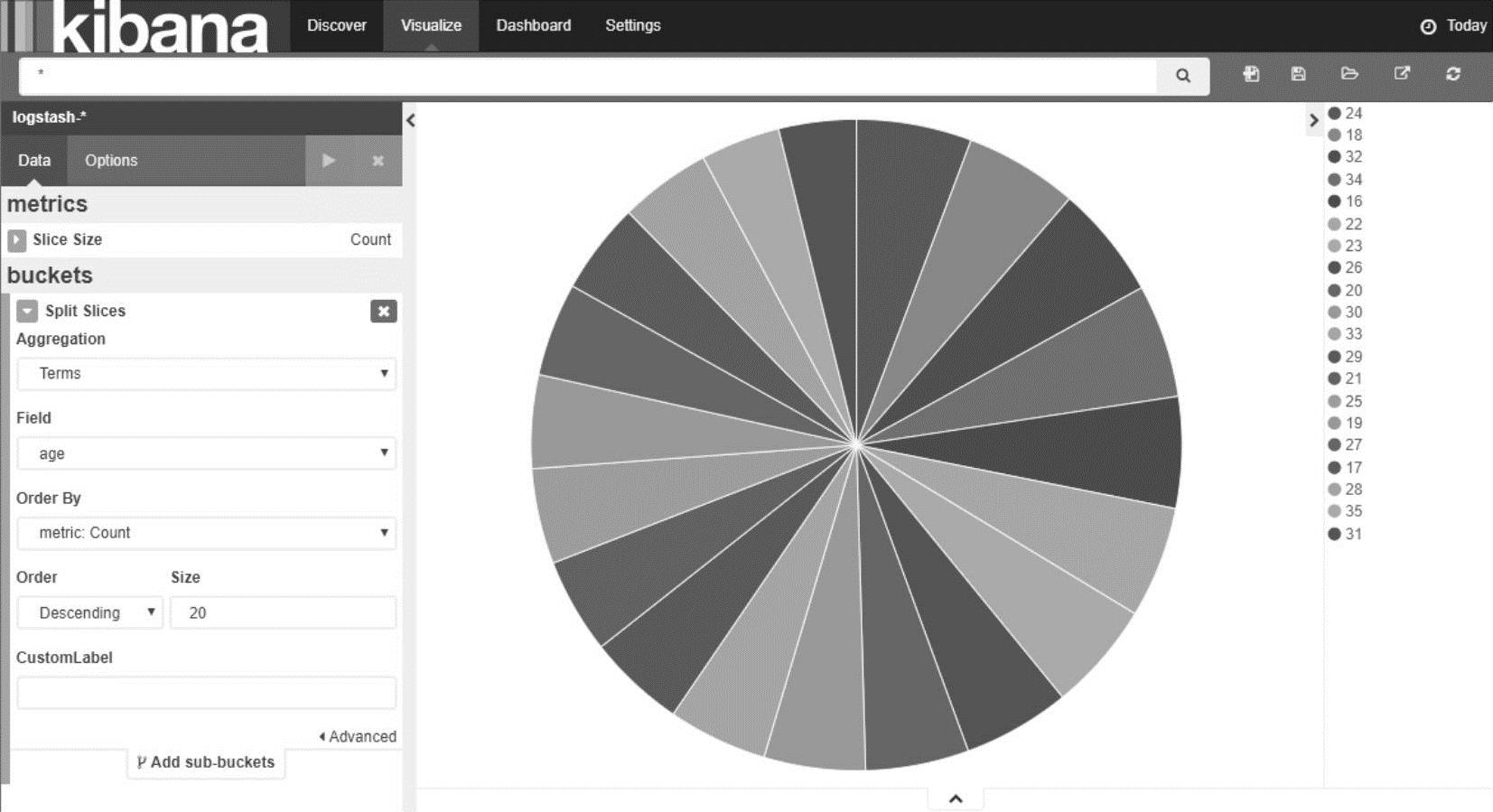
图18-5 Kibana饼图
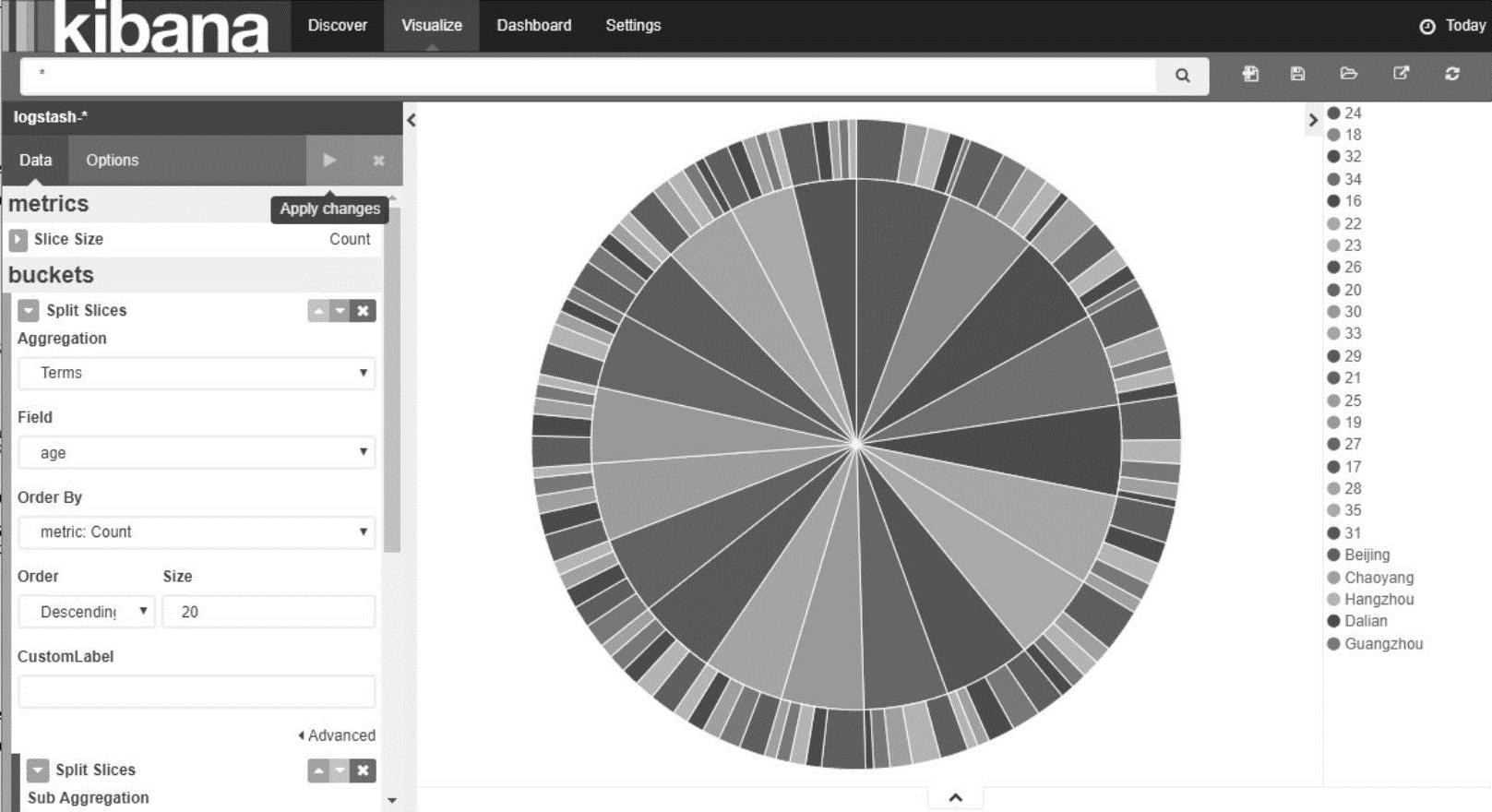
图18-6 Kibana多维饼图
(5)地图分布
Kibana可以根据地理位置绘制一个用户的位置分布图。选择“Visualize->Tile map->From a new search”,然后在配置项中选择Geohash和geoip.location,可见如图18-7所示的用户分布情况,此地图可以放大、缩小。
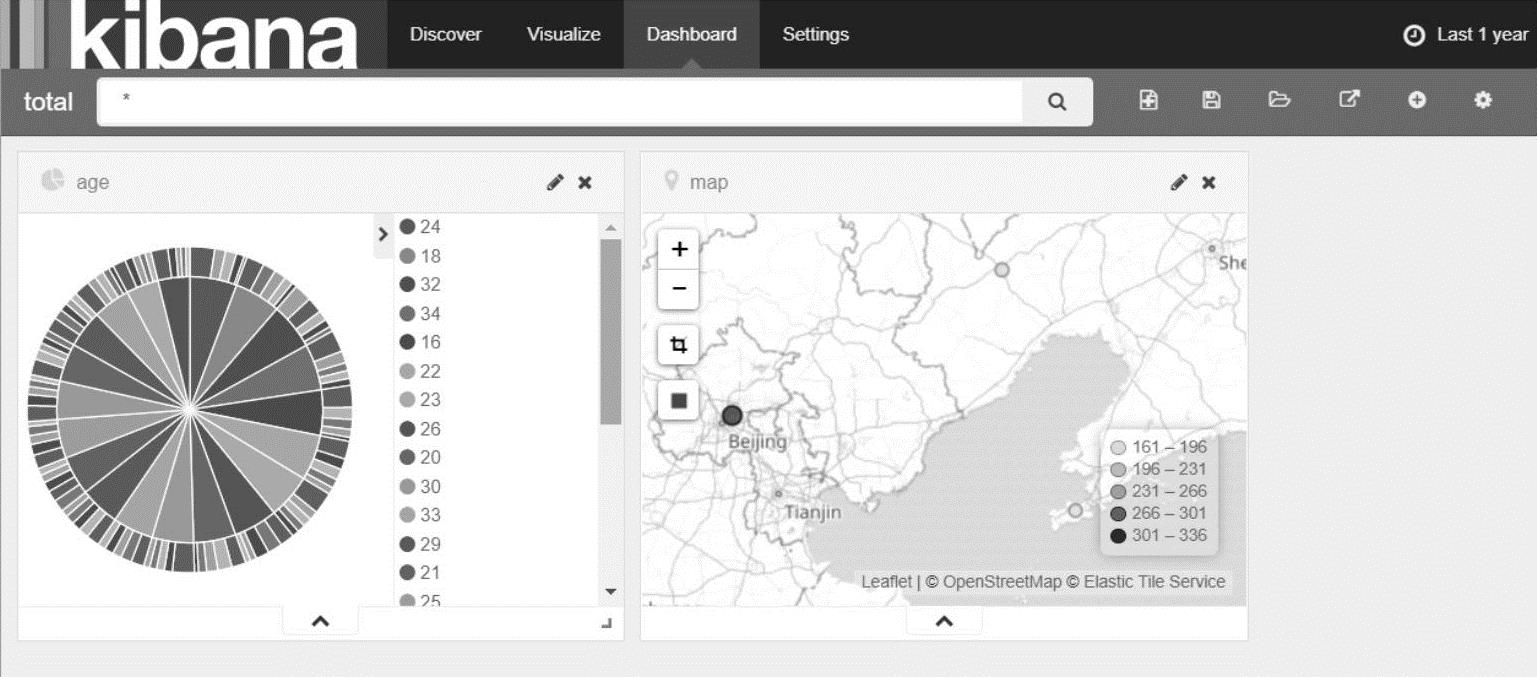
(6)聚合展示
Kibana可以把之前保存的分析图聚合展示出来,选择“Dashboard”,然后根据页面的提示添加之前保存的分析图,可以看到如图18-8所示聚合展示页面。
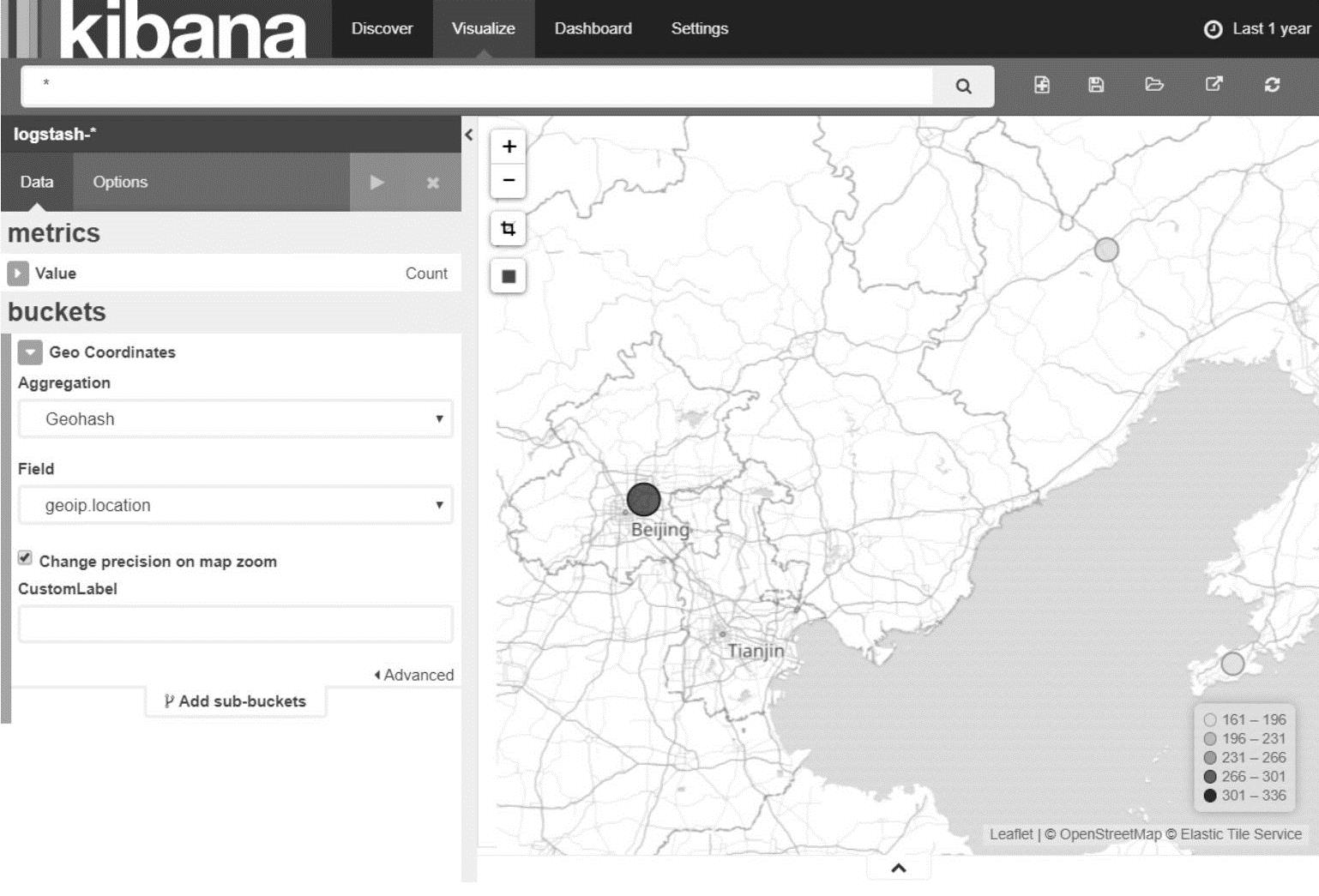
图18-7 Kibana地图
 (https://www.xing528.com)
(https://www.xing528.com)
图18-8 Kibana聚合展示
[1]由于本篇介绍的内容较多且较难归类,并且本篇所介绍的内容都是为了满足或者扩充系统程序的某些能力,所以把本篇介绍的内容统称为系统组件。
[2]生成此文件后,记得检查工程的application.yml文件,查看mybatis属性项是否添加了对此文件的扫描。
[3]设置此值时需要注意MySQL的文件操作权限。
[4]RDBMS即关系数据库管理系统(Relational Database Management System),是将数据组织为相关的行和列的系统,而管理关系数据库的计算机软件就是关系数据库管理系统。
[5]NoSQL,指的是非关系型的数据库。NoSQL有时也称作Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。
[6]Robomongo是一个基于Shell的跨平台开源MongoDB可视化管理工具。官网是https://robomongo.org/。
[7]Java对象的保存也可以转成Json格式后,存入String类型中。
[8]Zookeeper的官网是http://zookeeper.apache.org/。
[9]Zookeeper集群中只要有过半的机器正常工作,就是可用的。例如集群有2个Zookeeper节点,那么只要有1个宕机,Zookeeper就不能用,因为1没有过半,2个Zookeeper的宕机容忍度为0;同理,集群有3个Zookeeper节点,一个宕机,剩下2个正常的,过半了,所以3个Zookeeper的容忍度为1;多列举几个:2->0;3->1;4->1;5->2;6->2,会发现一个规律,2n和2n-1的容忍度是一样的,都是n-1。多出一台用处不大,所以集群总数为奇数。
[10]网址是http://mvnrepository.com/artifact/com.101tec/zkclient。
[11]group组也可称为卷。同一组内服务器上的文件是完全相同的,同一组内的存储服务器是对等的,文件上传、下载、删除等操作可在任意一台存储服务器上进行。
[12]ElasticSearch官网是https://www.elastic.co/cn/。
[13]Lucene是一款高性能的、可扩展的信息检索(IR)工具库。
[14]ElasticSearch中索引的名称不能有大写字母。
[15]Spring Data与ElasticSearch进行整合,让操作变得简单。通过两者进行整合,用户可以像操作关系型数据库一样操作ElasticSearch,CURD、排序、分页操作统统一步到位。
[16]在任意的查询字符串中增加pretty参数,会让Elasticsearch美化输出(pretty-print)Json响应,便于阅读。
[17]分词器:接受一个字符串作为输入,将这个字符串拆分成独立的词或语汇单元(token)(可能会丢弃一些标点符号等字符),然后输出一个语汇单元流(token stream)。
[18]IK-Analysis的网址是https://github.com/medcl/elasticsearch-analysis-ik。
[19]ik_smart会做最粗粒度的拆分,例如会将“java程序员”拆分为“java,程序员”。
[20]ik_max_word会将文本做最细粒度的拆分,例如会将“java程序员”拆分为“java,程序员,程序,序,员”,会穷尽各种可能的组合。
[21]本章展示的代码中省略了OrderDao接口类的代码。
[22]因为订单是占用商品库存的,如果用户长时间不支付会使商品数量被未生效订单占用但是又无法卖出,这是不符合商家利益的,所以订单都会有一个超时时间。
[23]即Advanced Message Queuing Protocol,高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。
[24]在代码中可以点击此注解查看其注解内容,其使用范围不只是作用于类之上。
[25]在日志搜集方面,可以在各个服务器上使用Filebeat作为专门的日志搜集工具,Filebeat可以把搜集到的数据发送给消息队列用于Logstash读取,或者直接由Filebeat发送给Logstash。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。