



ElasticSearch内置的分词器[17]对中文的支持并不友好,它把中文拆分为单个字来进行全文检索,这就常常造成指定的文档没有被搜索到,中文搜索不能满足实际业务需求的情况。大部分情况归因于分词器和映射mappings的定义存在问题。
为了解决此问题,可以先对ElasticSearch分析过程进行调试。ElasticSearch提供了_analyze和_explain这两个专用的REST API。
■_explain用来帮助分析文档的相关性评分。
■_analyze可以帮助分析每一个字段(field)或者某个分析器(analyzer)/分词器(tokenizer)。
例如使用_analyze分析文本“java程序员”,使用Postman工具进行演示。分析效果如图15-15所示。 http://39.106.208.144:9200/_analyze?pretty&analyzer=standard&text="java程序员"
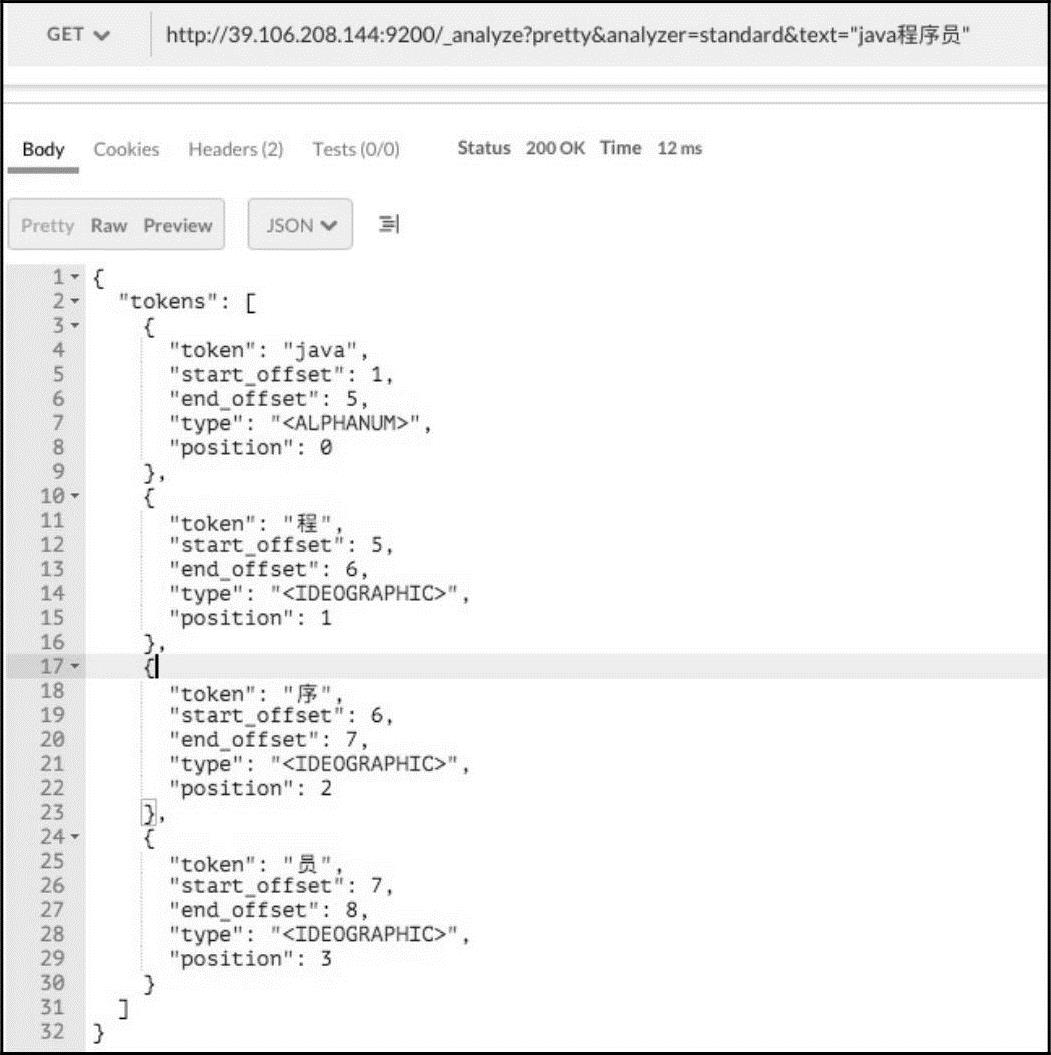
图15-15 默认分词结果
ElasticSearch中的默认分词器将“java程序员”拆分成了四个字,而实际希望它能拆分成“java”、“程序员”两个词。
(1)IK-Analysis分词器
这里介绍一款比较常用的中文分词器IK-Analysis[18],它是针对ElasticSearch的分词器扩充的中文分词插件。此插件的安装方法可以参考第19章自行安装,这里介绍其用法。使用安装好的IK分词器,再次针对“java程序员”进行分析,IK有两个分析器:ik_smart[19]和ik_max_word[20],这里演示使用ik_smart。分析结果如图15-16所示。
http://39.106.208.144:9200/_analyze?pretty&analyzer=ik_smart&text="java程序员"
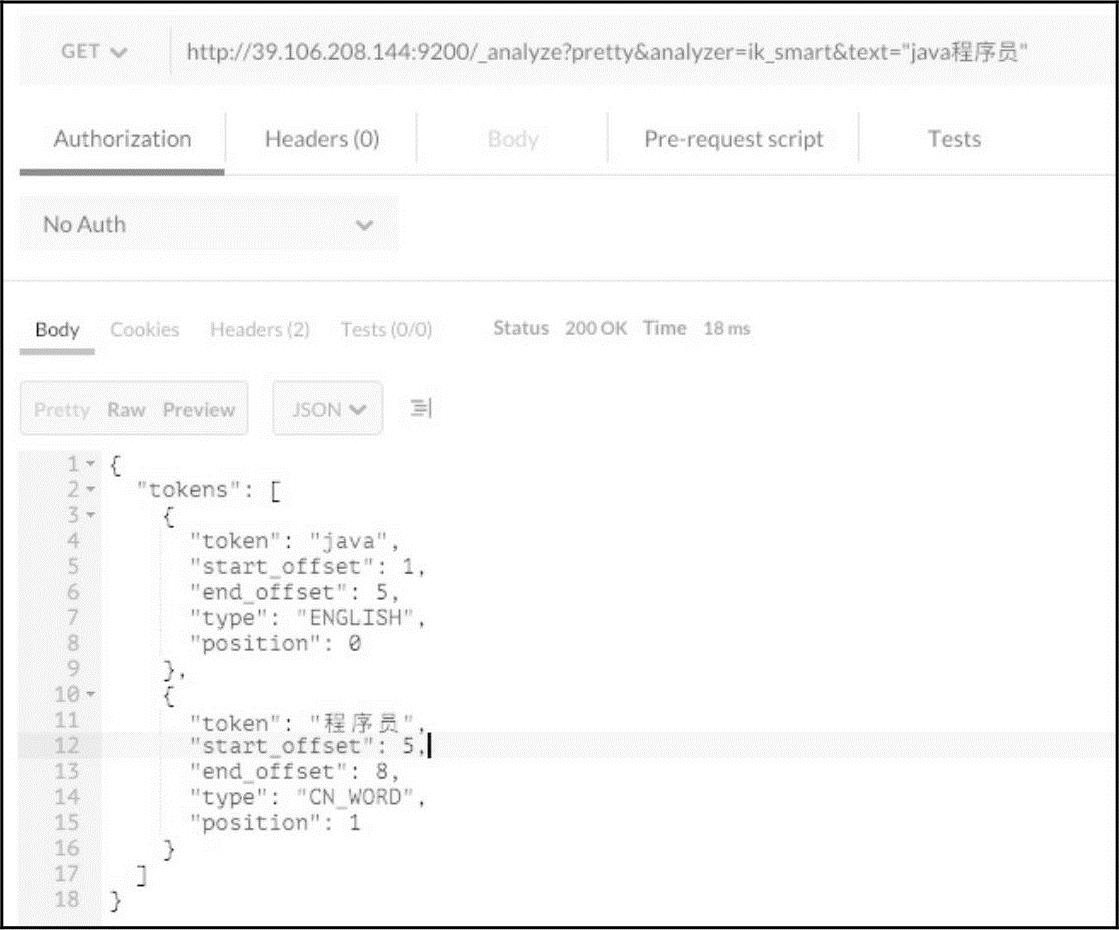
图15-16 IK分词器结果(https://www.xing528.com)
通过输出的效果,可以看到使用IK分词器后,将短语拆分成需要的格式。
(2)自定义扩展词
很多行业都有一些特定的专业术语,网络上也有许多流行语,默认的IK分词器显然没法全面覆盖它们,需要在IK分词器插件中扩展配置自己的词语。
例如“丑橘”这个词,使用默认IK分析“丑橘”,效果如图15-17所示。 http://39.106.208.144:9200/_analyze?pretty&analyzer=ik_smart&text="丑橘"
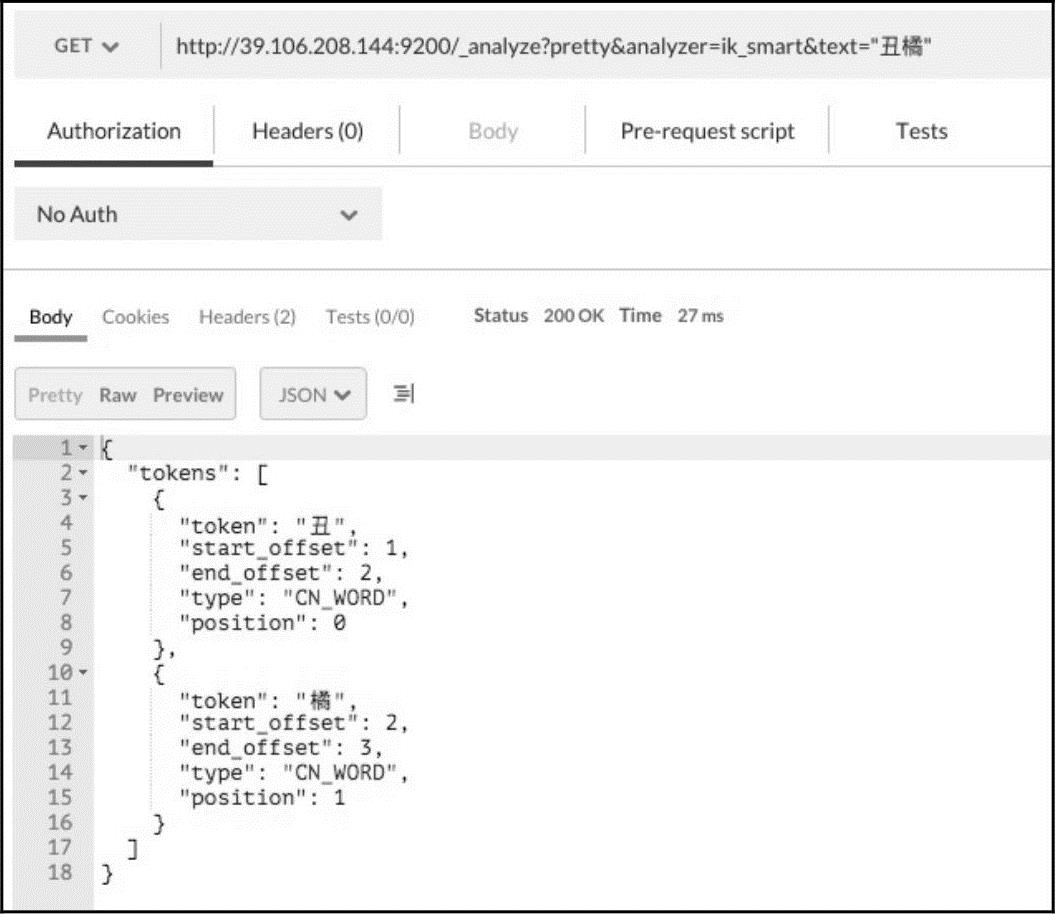
图15-17 不支持的分词
显然IK的词典里面没有“丑橘”这个词,所以它被拆分成单个字。通过查看IK的配置文件{安装路径}/elasticsearch/config/analysis-ik/IKAnalyzer.cfg.xml,找到自定义词语的配置文件。IKAnalyzer.cfg.xml具体内容如下:

根据文件内的提示,需要在custom/mydict.dic文件里面增加自定义词汇,将“丑橘”添加进来。打开mydict.dic文件,添加“丑橘”词语,保存后,重启一下ElasticSearch服务。再次使用IK分析“丑橘”,效果如图15-18所示。
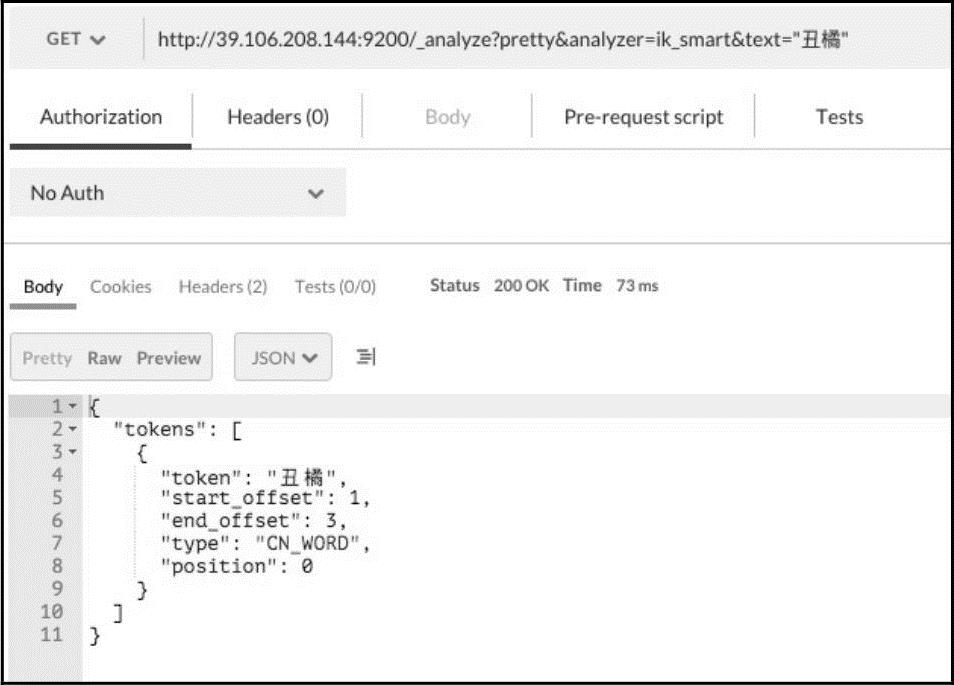
图15-18 自定义后的分词效果
由输出结果可见IK分词器已经匹配到了“丑橘”这个词。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。