



虽然Zipkin的数据不像业务服务数据一样需要永久保存,但是有时确实希望能够保留一段时间内的跟踪数据,而不是Zipkin服务重启后数据就全部丢失了。在这个前提下,可以使用MySQL或ElasticSearch[58]两种存储组件。Zipkin的存储配置相对简单,只要准备好相应存储组件并且进行如下配置即可完成Zipkin数据的存储。
(1)MySQL存储
在Zipkin服务中添加如下依赖:

在配置文件中添加如下配置:

在对应的MySQL中建立springcloudzipkin数据库。
经过以上几步,就完成了Zipkin的MySQL数据库存储。
(2)ElasticSearch存储
在Zipkin服务中添加如下依赖,这里需要注意的是引入的依赖版本号要能适配ElasticSearch,否则Zipkin无法收集链路信息。

在配置文件中添加如下配置:
zipkin:

经过如上配置,即完成了Zipkin通过ElasticSearch存储。
至此,本章已经完成了Spring Cloud大部分组件的讲解。下面查看Eureka页面,来看看整个服务集群的运行情况,如图9-44所示,一个健全的集群系统已经搭建好了。
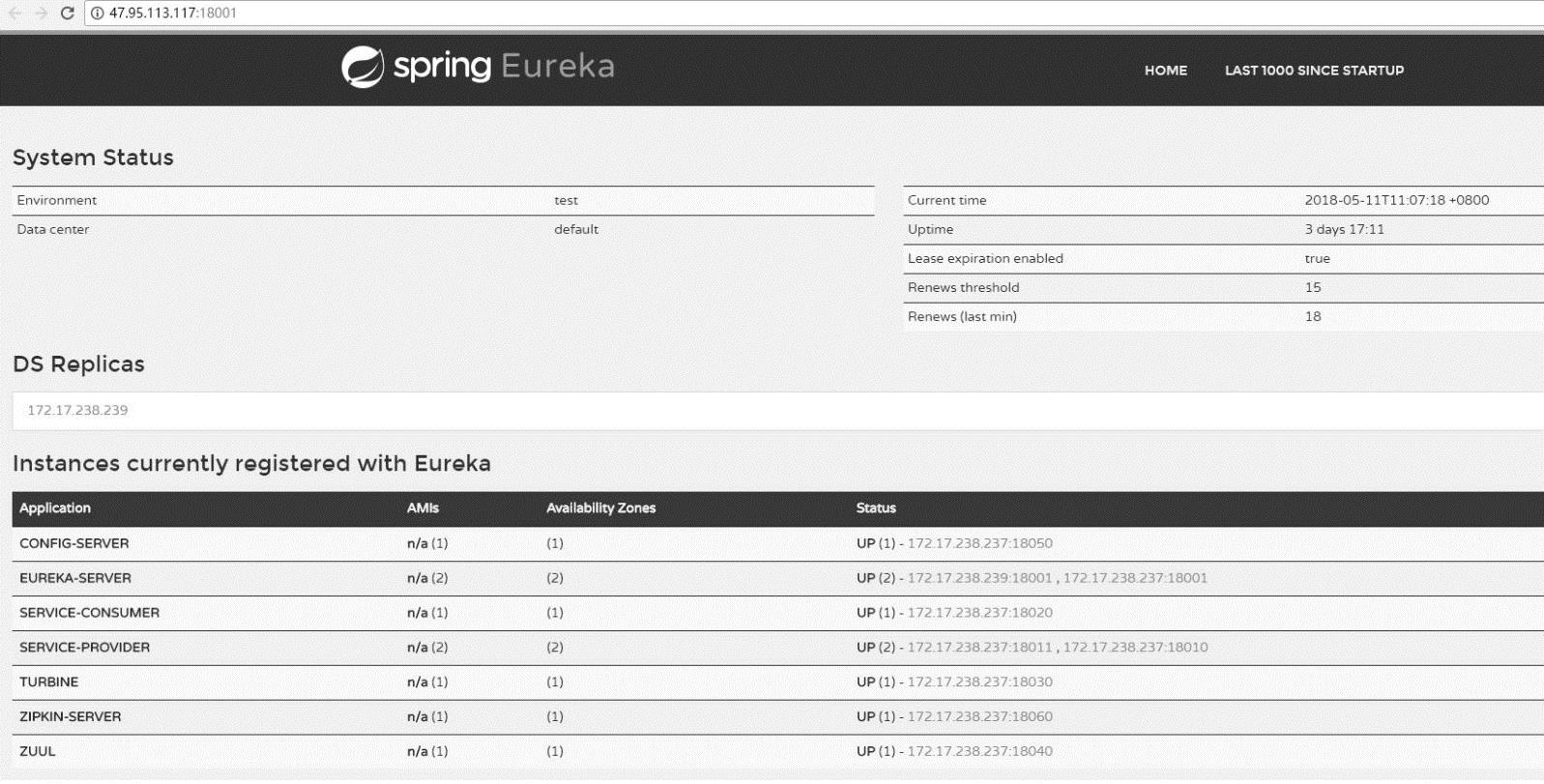
图9-44 Spring Cloud服务集群
[1]虽然作者认为错误都是人造成的,框架不应该承担这些责任,但是如果能够通过框架降低人为犯错的概率也是个不错的选择。
[2]Spring官网是http://spring.io。
[3]框架:提供了一些基础功能,简化开发,让研发人员更加专注业务逻辑的组件集合。
[4]本章用Bean表示类实例,bean表示配置文件中的配置。
[5]单例模式,是一种常用的软件设计模式。在它的核心结构中只包含一个被称为单例的特殊类。通过单例模式可以保证系统中应用该模式的类只有一个实例。
[6]原型模式:每次注入或通过上下文获取时都会创建一个新实例。
[7]AbstractApplicationContext抽象类,Spring中所有ApplicationContext的父类,实现了一些比较核心的方法。
[8]这里仅作为prototype演示,实际使用中这个类一般都为单例模式。
[9]默认使用JDK动态代理来创建AOP代理,可以为任何接口实例创建代理,当需要代理的类不是代理接口的时候,Spring会切换为使用CGLib代理,也可强制使用CGLib。
[10]代理模式:为其他对象提供一种代理以控制对这个对象的访问。在某些情况下,一个对象不适合或者不能直接引用另一个对象,而代理对象可以在客户端和目标对象之间起到中介的作用。
[11]Logback官网是http://logback.qos.ch。
[12]Mybatis-Spring的官网是http://www.mybatis.org/spring/zh/index.html。
[13]druid是目前比较优秀的数据库连接池,在功能、性能、扩展性方面表现良好。
[14]CGI是Web服务器运行时外部程序的规范,按CGI编写的程序可以扩展服务器功能。
[15]前端控制器模式提供了一个集中的请求处理机制,所有的请求都将由一个单一的处理程序处理。该处理程序可以做认证/授权/记录日志,或者跟踪请求,然后把请求传给相应的处理程序。
[16]这里为了演示方便,在Controller中直接使用了Mapper,而在实际业务中,应该在Controller中注入Service,在Service中注入DAO,在DAO中使用Mapper。
[17]Postman是一款功能强大的网页调试与发送网页HTTP请求的Chrome插件。
[18]此处记录时间戳,是使用ThreadLocal记录开始时间,然后在同一线程内,和结束时间进行相减,从而计算出来的。
[19]Internet Media Type,有时在一些协议的消息头中叫作“Content-Type”。它使用两部分标识符来确定一个类型。
[20]FastDFS是一个开源的高性能分布式文件系统,它的主要功能包括:文件存储、文件同步和文件访问,具备了大容量和负载均衡的能力。
[21]OSS:阿里云对象存储服务(Object Storage Service,简称OSS),是阿里云提供的海量、安全、低成本、高可靠的云存储服务。(https://www.xing528.com)
[22]在后面的演示中选择Maven进行工程管理,使用Java作为开发语言,Spring Boot版本使用1.5.10+。
[23]手动分别引入依赖时可能会发生版本冲突的问题,使用起步依赖会保证所引入的依赖版本之间的可用性。
[24]它由以下几个注解组成:@SpringBootConfiguration、@EnableAutoConfiguration、@ComponentScan,这三个合起来形成了Spring Boot的扫描、自动配置等能力。
[25]记得去掉之前在Arguments中设置的端口号,否则配置文件中的值会被覆盖。
[26]在调试程序时,可能针对某些修改要重启程序,这会对研发速度造成一定的影响,可以通过引入spring-boot-devtools依赖从而实现动态更新程序的目的,而不必不断手动启动服务。
[27]ORM即对象关系映射(英语:Object Relational Mapping,简称ORM,或O/RM,或O/R mapping),是一种程序技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换。
[28]JPA是Java Persistence API的简称,中文名为Java持久层API,通过JDK 5.0注解或XML描述“对象-关系表”的映射关系,并将运行期的实体对象持久化到数据库中。
[29]这里不考虑其他情况,例如从某些产品来讲,希望获取用户的门槛越低越好,尽管用户输入了一个不合理数据也期望用户能够使用业务。
[30]hibernate validator不需要单独引用,Web起步依赖已经集成。
[31]缓存的读写能力强于数据库,可以把一些经常访问的数据放入缓存中,以降低数据库的压力。本地缓存也是提高性能的好办法,只是同步问题需要解决。
[32]本章介绍的组件,大部分是通过Dalston.SR4版本进行编写,之后又升级到Edgware.SR2版本的,所以在这两个版本中,程序实现基本是通用的。但是由于Spring Cloud版本更新很快,如果读者拿到本书时使用的Spring Cloud版本不是这两个,可能会发生不适配的情况。
[33]业务服务从Eureka获取到的服务列表信息会自己进行缓存,而不是每次调用都要请求Eureka获取列表。
[34]本章用到的新依赖包和注解较多,使用注解时一般都需要import相应的资源。由于本书使用顺序的方式讲述每个知识点,所以import导入的内容和当时讲解的组件一般都有关系,当添加注解时如果书中没有明确说明引入的资源包,一般IDE默认提示的资源包都可以使用,但大家还要多注意分辨。
[35]Region表示区域,这里设定的区域为javadevmap;map_eureka表示集群分组。在这里仅仅作为演示的写法,效果和defaultZone是同样的。当然region还有其他含义,只是这里没有使用。
[36]Eureka中已注册的服务信息的移除在极端情况下的反应时间会非常长,例如使用kill命令杀掉业务服务节点,Eureka可能没有那么快地更新业务服务状态变化,eureka.server.enable-self-preservation=false配置项可以关闭Eureka的数据缓存保护,但是仍存在延迟时间,所以应尽量使用shutdown端口等方式正常关闭业务服务,因为正常关闭会有移除服务节点逻辑执行。
[37]当有多个服务提供者时,负载均衡会通过其负载策略,调用多台服务提供者的实例,而不是仅仅调用其中的一台。
[38]移植过程中注意修改对应的包名,否则无法编译或程序运行出现错误。
[39]在实际项目中,把此工程名改为带有User标记的工程名更为合适,因为那样更能直观地表达这个服务提供者负责的模块是什么。这里没有修改工程名是因为本章不会出现其他能力的服务提供者,并且用消费者和提供者作为工程名,对于新手更加直观。
[40]模板化返回和请求的切面日志记录需要添加进工程,以后的Spring Boot业务服务都默认这些已经添加进工程。
[41]可以使用IP端口的方式进行调用,即把例子中的服务名改为IP和端口,这里就不再赘述。
[42]在你无法对程序进行断点跟踪的时候,日志会帮你的大忙。
[43]如果你的服务器够多,就不用这么麻烦地配置多环境,只要在另一台服务器上启动一个实例即可。
[44]这里仅为了演示,所以没有修改返回的错误码。实际业务中,应根据希望达到的效果正确使用fallback。
[45]如果感兴趣,可以直接访问http://ip:18020/hystrix.stream地址,观察页面的原始数据。另外注意服务的地址,由于演示工程的服务已经部署到外网上,所以前面页面请求的地址是一个外网地址,但是此处输入的是127.0.0.1,是由于此服务是自我数据的访问,所以输入自己的本机地址即可。但是如果想用浏览器访问外网的hystrix.stream,还是应该使用外网地址。
[46]这里为了演示的连贯性,没有删除getUserFromProvider方法的熔断器代码,但是此方法和Feign接口类监控的是同一个调用,所以在实际工作中应该避免这种浪费性能的重复。
[47]在实际项目中,不要盲目扩大线程数,线程数的配置要和服务器每秒承载的请求数、单个请求的执行时间、服务器的资源情况等因素良好地配合。
[48]本处演示完后,会删除getUserFromProvider方法的熔断器配置。
[49]这里作者翻阅了较多的资料,大部分资料是介绍Hystrix原理和使用方法的,但是使用在何处却论述较少。通常的用法是在服务调用时使用,但是作者认为在Controller的接口上使用Hystrix限流也是个不错的办法。这样可以在调用之初就避免接口向后的服务压力。毕竟Hystrix要避免程序执行过程中的故障,程序调用的源头也是属于执行流程之内的。
[50]这里消息队列使用RabbitMQ,后面的章节会包含一个简单的RabbitMQ的安装方法,这里就不再介绍其安装。
[51]对于不针对服务,仅对单独IP端口的路由,可以不配置Eureka,仅配置接口路径和地址映射即可。具体格式后面会有简单介绍。
[52]为了演示方便,后面的例子中放开了对Provider服务的屏蔽。
[53]在此演示的服务实现仅仅是一个鉴权服务的主要思路,并非真正的鉴权服务,这个示例还需扩充能力,例如生成的token应该缓存起来,token应该具备时效性,不同的账号会有不同的权限等,大家可以自己丰富鉴权服务的实现或者使用一些开源的鉴权组件。
[54]此Auth服务可以加入微服务集群中,这样就需要在获取token时,在用户鉴权Filter中对路径进行特殊处理,不进行token验证,否则用户在没有token的情况下永远无法获取token。可以使用判断HttpServletRequest中请求路径的方法,若发现是获取token的请求,则不进行token验证。
[55]Message Digest Algorithm MD5(中文名为消息摘要算法第5版)为计算机安全领域广泛使用的一种散列函数,用以提供消息的完整性保护。
[56]这里使用此风格是为了便于横向书写,项目代码中采用的是yaml形式的书写方式。
[57]这里需要保证Zuul与Turbine的数据采集方式统一,默认情况下Zuul不是通过消息队列采集的,如果Turbine想通过消息队列采集,那么Zuul上也要配置消息队列;如果Zuul不想使用消息队列,那么两者都要改为非消息队列的采集方式。
[58]ElasticSearch是一个分布式的、基于RESTful接口的搜索和分析引擎。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。