



Spark和Hadoop都是美国Apache软件基金会支持的开源软件项目,用于大规模分布式数据处理。可以认为Spark是Hadoop的升级版本。相比Hadoop,Spark它在性能上比Hadoop要高100倍。Spark提供比Hadoop更上层的API,同样的算法在Spark中实现往往只有Hadoop的1/10或者1/100的长度。
1.Hadoop
现在Hadoop已经发展成为包含多个子项目的集合。虽然其核心内容是MapReduce和Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)。
(1)HDFS
HDFS是一个分布式文件系统。由于HDFS具有高容错性的特点,所以可以设计部署在低廉的硬件上。它可以通过提供高吞吐率来访问应用程序的数据,适合那些有着超大数据集的应用程序。HDFS放宽了可移植操作系统接口(Portable Operating System Interface,POSIX)的要求,这样就可以实现以流的形式访问文件系统中的数据。Hadoop集群示意图如图5-13所示。
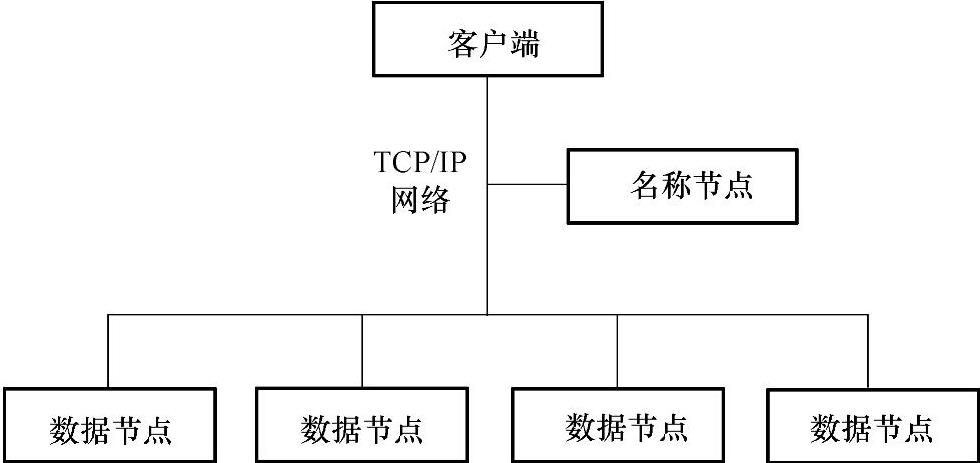
图5-13 Hadoop集群示意图
HDFS采用了主从结构模型,一个HDFS集群是由一个名称节点和若干个数据节点组成的。名称节点是主节点,所有的数据节点都是从节点。存储在HDFS中的文件被分成块,然后将这些块复制到多个计算机中(数据节点)。
(2)HDFS工作过程
1)文件写入
①客户端向名称节点发起文件写入的请求。
②名称节点根据文件大小和文件块配置情况,返回给客户端它所管理部分数据节点的信息。
③客户端将文件划分为多个块,根据数据节点的地址信息,按顺序写入到每一个数据节点块中。
2)文件读取
①客户端向名称节点发起文件读取的请求。
②名称节点返回文件存储的数据节点的信息。
③客户端读取文件信息。
3)文件块复制
①名称节点发现部分文件的块不符合最小复制数或者部分数据节点失效。
②通知数据节点相互复制块。
③数据节点开始直接相互复制(https://www.xing528.com)
2.Spark
(1)简介
Spark是针对超大数据集合的低延迟的集群分布式计算系统,比MapReducer快40倍左右。Spark是Hadoop的升级版本,Hadoop作为第一代产品使用HDFS;第二代加入了缓存来保存中间计算结果,并能适时主动推动Map/Reduce任务;第三代就是Spark倡导的流。Spark兼容Hadoop的API,能够读写Hadoop的HDFS HBASE顺序文件等。Spark架构如图5-14。
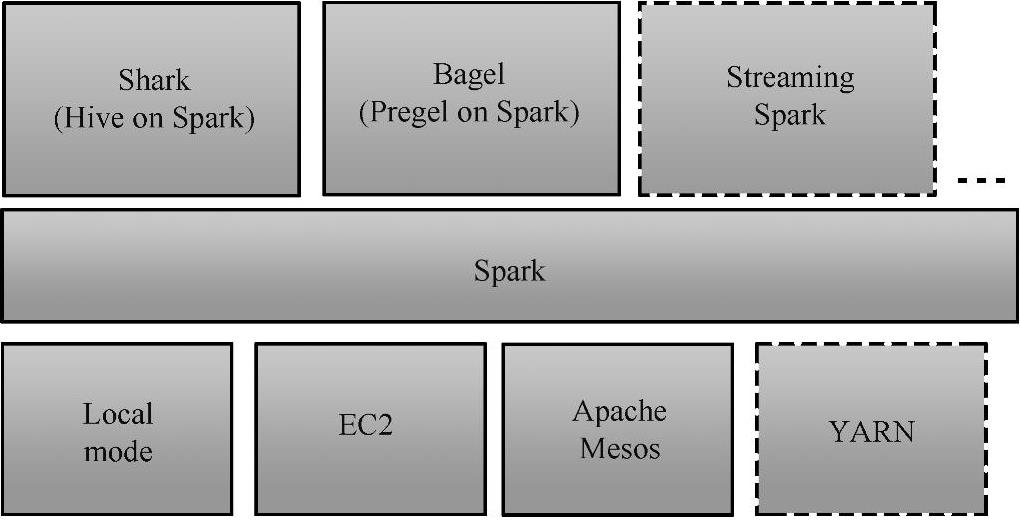
图5-14 Spark架构
尽管Hadoop适合大多数批处理工作负载,而且在大数据时代成为企业的首选技术,但由于以下几个限制,它对一些工作负载并不是最优选择:
•缺少对迭代的支持;
•需要将中间数据存在硬盘上以保持一致性,因此会有比较高的延迟。
传统Hadoop性能较低的原因是磁盘I/O复制和序列化等问题。而在Spark中,使用内存替代了使用HDFS存储中间结果。
(2)Spark的适用场景
Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大;数据量小但是计算密集度较大的场合,受益就相对较小。由于弹性分布式数据集(Resilient Distributed Datasets,RDD)的特性,Spark不适用那种异步细粒度更新状态的应用,如Web服务的存储或者是增量的Web爬虫和索引,就是对于那种增量修改的应用模型不适合。总的来说,Spark的适用面比较广泛且比较通用。
(3)Spark与Hadoop的对比
1)Spark的中间数据放到内存中,迭代运算效率更高。Spark更适合迭代运算比较多的机器学习(Machine Learning,ML)和数据挖掘(Data Mining,DM)运算。因为在Spark里面,有RDD的抽象概念。
2)容错性。在分布式数据集计算时通过“checkpoint”来实现容错,而有两种方式:一种是“checkpoint data”,另一种是“logging the updates”。用户可以控制采用哪种方式来实现容错。
3)可用性。
Spark通过提供丰富的Scala、Java、Python API及交互式“Shell”来提高可用性。
4)Spark比Hadoop更通用
Spark提供的数据集操作类型有很多种,如map、filter、flatMap等多种类型,不像Hadoop只提供了Map和Reduce两种操作。Spark这些操作称为“Transformations”,同时还提供Count、collect、reduce等多重操作。
这些多种多样的数据集操作类型,给开发上层应用的用户提供了方便。各个处理节点之间的通信模型不再像Hadoop那样就是唯一的“Data Shuffle”模式。用户可以命名、物化、控制中间结果的存储、分区等。可以说编程模型比Hadoop更灵活。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。