



软件是一种固化的思维→思维的固化体现为概念和逻辑的固化→软件开发大多时候需要多人协作→为保证简单性,但凡可封闭的信息要进行封闭→如果达不成这一目标,则误用将增加不必要的逻辑关联。
1.信息隐藏的价值根源
假使我们认同软件的构造是一个复杂的结构,那么管理这种复杂度必然需要一些技巧。而为了找出这些技巧,则需要先考察这种复杂度的基本构成。
软件的构造过程牵涉了两个最为基本的要素:一是软件自身;二是构造软件的人。
假设说存在着一个标准的人,这个人智力水平恒定,创新能力恒定,技能水平恒定。那么软件的复杂度只决定于其自身,比如,软件所需要面对的业务规则、所需要的计算水平等。应对这类复杂度的有效手段是优化方法,好比说快速排序的效率大多时候就是比冒泡排序好。
当我们开始考虑人的可变因素时,复杂度的来源则发生了变化。人是有着许多与生俱来的特质的,比如说,人是会犯错的、人在同一时间可以处理的事情是有限度的等。
因为这些特性,人在应对软件自身所拥有的复杂度的同时,又带来了偶然的,与个人特质相关的复杂度。比如说,人无法同时记住过多的概念,否则容易记忆出错;局部变量的名称可能碰巧和一个全局变量相同,而我们又误把这个局部变量作为全局变量使用了。
信息隐藏则是减少这类偶然性复杂度的一个有效手段。对于方法或函数而言,输入参数,输出参数描述了它的边界。对于类而言,公有属性和公有方法描述了它的边界。边界以内的即是被隐藏掉的信息。这个时候不管内部多么复杂,对外而言只是一个单一概念,这有助于使程序变得更加容易理解。也即是说,信息隐藏可以减少在特定层面上需要暴露的信息块数。
假设说我们用一个名为CustomerManager的类来管理客户的基本信息,但在开放出AddCustomer(),EditCustomer(),DeleteCustomer()这样接口的同时,也开放了内部存放客户信息的集合类。那么使用CustomerManager类的人,很可能直接通过操作集合类来获取客户信息。这个做法虽然可以被编译器所接受,但实际上一旦如此,任何一个人关注CustomerManager时就需要关注4个信息块,而非是3个,如图7-9所示。为了避免这类误用,存放客户信息的集合类应该被隐藏起来,让用的人只看到接口。
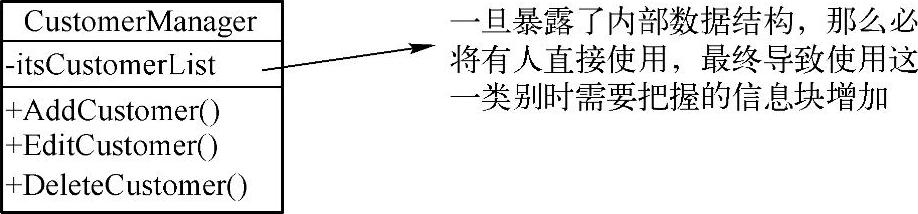
图7-9 信息隐藏不好的例子
2.信息隐藏的归纳
下面我们来对信息隐藏的类别做一些归纳和总结。
●不同手段下,信息隐藏的程度是强弱有别的。
如果外部只能看到接口和基本数据类型,那么信息隐藏得最彻底。这个时候,如果必要,通常就可以在物理上把相关部分分离出来,如创建动态链接文件等。
使用类的各种关键字(如private、public)来控制信息隐藏时,信息隐藏的程度已经弱了一级。因为这个时候类自身所处的状态已经成为一个必须了解的东西,而为了解这些东西,很多时候就必须了解内部的数据和私有函数。这不难理解,公有方法可以操作私有数据,那么理解公有方法就需要了解私有数据。
常说的全局变量信息隐藏程度最差,几乎是不做信息隐藏。
●信息隐藏是抽象数据类型(ADT)、类等之所以存在的一个比较主要的理由。但信息隐藏并不只在使用抽象数据类型和类的时候才有意义。定义接口的时候,甚至实现的时候信息隐藏这一原则同样可以发挥作用。
比如说,实现方法A的时候,实际上只需要类的两个属性,但却把整个类定义成了这个方法的参数,这也是违背信息隐藏原则的。
●目的是信息隐藏,但实际上却违背了信息隐藏原则的情形。
比如说,类的方法中常常会使用到成员变量。有时候和类自身关联不是很紧密的属性也会被添加为成员变量。表征数据库的类(如DataBase)大多时候并不需要和获取数据的类(如传感器的类Sensor)直接关联,但有时候Sensor的实例却会被添加为DataBase的私有成员变量。
●对外是信息隐藏,但对内却完全不隐藏的情形。大多时候类中的方法并不会把成员变量作为自身的参数,而是会直接使用,比如说,由于Sensor的实例是DataBase的私有成员变量,那么DataBase::GatherData()在用到Sensor实例的时候会直接使用,而不会把接口定义为.DataBase::GatherData(Sensor&sensor)。这种用法与成员变量过度膨胀的趋势撞在一起后,有意思的事情发生了。
从外部看,传感器这样的成员变量是私有的,达到了信息隐藏的目的。但对于方法而言,结果却完全相反。
每多使用一个成员变量,其自身的信息隐藏就被破坏一点。极端情形下,如果整个程序只有一个类,那事实上等于没有信息隐藏。(https://www.xing528.com)
如果在同一方法中,用到5、6个成员变量,那么这个方法会变得非常难懂。因为对于类中的方法而言,这些成员变量自身的变化是完全不被隐藏的,每个都有自己独立的脉络,比如说,DataBase::SetInterval()方法中可能会调整Sensor实例的状态,进而对Sensor::GatherData()产生影响。这会导致方法的边界不清晰。不清晰,也就不可能紧凑。不紧凑意味着阅读的时候,一个方法所需要的信息不能立刻获取。最终会导致程序难读、难改、难维护。
这类实例提醒我们,并非把很多操作和数据成员都放到类里面就达成了信息隐藏的目的。
事实上这对每个类的可能规模提出了限制。极端的情况下,如果一个类很大,有2000SLOC,那么所有这2000SLOC代码就等于通过成员变量联结在一起,这和过度使用全局变量在一定程度上等价。
从信息隐藏的程度上来看,对方法而言,局部变量最佳,类的成员或属性稍差,全局变量最差。
局部变量把信息隐藏在方法之内,成员或属性把信息隐藏在类之内,而全局变量等于不做信息隐藏。
3.一点总结
信息隐藏和前面提到的层次问题并不能分割开来。从基本趋势来看,信息隐藏做得越彻底,层次也必然就会越多,而前面曾经提及过层级自身是有副作用的。
从最小化层次的副作用的角度来看,使用函数或方法来隐藏数据,使用类似抽象数据类型(ADT)的方法来把数据封装到类之中,代价非常微小,几乎总是对的。但在类A中包含B,类B中包含C,类C中包含D这类的方式则福祸难料。诚然B、C、D被隐藏了,但绝不是毫无代价。
抽象数据类型(ADT:Abstract Data Type)
谈及封装的话,很多人立刻就会想到面向对象,但事实上封装的历史要比面向对象还要长一些。从抽象数据类型(ADT)开始,人们已经开始使用封装这一思想。
抽象数据类型(ADT)更像是类的前身,本身并不是复杂的概念。
当有一组数据以及与其捆绑在一起的一组操作,就有了一个抽象数据类型(ADT)。
《代码大全》中列了如下一些典型的抽象数据类型。
油罐
填充油罐
排空油罐
获取油罐容积
获取油罐状态
列表
初始化列表
向列表中插入条目
从列表中删除条目
读取列表中的下一个条目
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。