



笔者认为可以根据数据的使用方式,将应用分为三种:以计算为中心的应用、以数据为中心的应用和需要兼顾数据与计算的应用。
针对上面所提到的不同类型的应用,我们需要选择合适的架构以及技术来实现。
1.以计算为中心的应用
通常见到的大部分应用,计算所需的数据量往往都不是很大,而影响执行效率的通常是计算量。这样的应用包括:统计计算(比如大量用户话费的计算)、模拟计算(随机算法)、图像处理以及信息管理系统等。此类应用由于单个计算所需的数据量较小,数据传输的代价小,故可以将数据集中存放,并根据计算的需要实时发送数据,由多台计算机同时计算,以提高计算速度。
2.以数据为中心的应用
而对于Google和Baidu这样的互联网搜索公司来说,每天都需要从互联网采集海量的数据,并对其进行分析。其应用所需的输入数据往往较大,故它们的数据一般存放于像HDFS这样的分布式文件系统上或类似的集群数据服务器上,这些数据往往以大文件的形式存放,并且不容易被拆分,但这些数据可以供多个应用同时读取。在这样的情况下,一般不会移动数据,而会将任务发送到数据所在的服务器上执行。
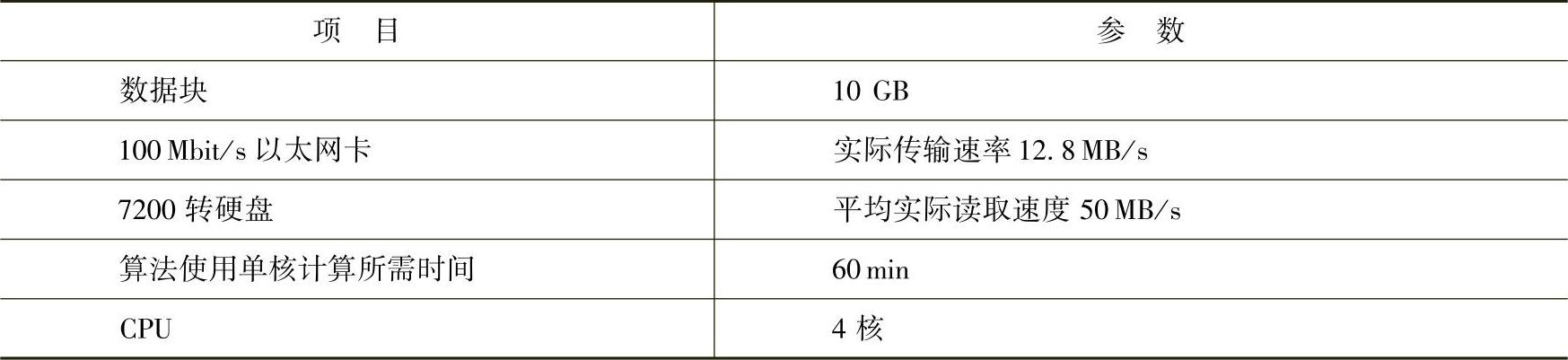
对于开发人员来说,需要先确定所开发应用的类型并结合所能获取的计算资源,综合分析后才能选择合理的架构与技术。下面以常见的百兆网卡,7200转硬盘处理10GB数据为例,将数据分配到多台计算机上计算所花的时间,与利用多核CPU、采用多线程技术在本地计算所花费的时间(业务可使用并行计算)进行比较。详细信息如表5-1所示。
表5-1 常见计算机硬件配置
实际计算时间为:
实际计算时间=单核处理时间/CPU核数+数据传输时间+数据读取时间
利用多核处理器本地计算所需时间为(需要重新看一下本地I/O的计算速度)
实际计算时间=单核处理时间/CPU核数+数据读取时间
=(60min/4)×60+10×1024/50
=900s+204.8s
=1104.8s
=18min
将数据分配到4台4核计算机上同时计算,所需时间为
实际计算时间=单核处理时间/CPU核数+数据传输时间+数据读取时间(https://www.xing528.com)
=60×60/(4×4)+(10×1024/12.8)×4+10×1024/50
=225s+3200s+204.8s
=60min
从上面的分析可以看出,由于数据传输量较大,将数据分发到多台计算机上执行虽然降低了算法本身计算所花的时间,但数据传输的时间显著增大,使得实际计算时间不但没有减少,反而变长。
影响数据传输的主要因素有数据复制的数量以及数据本身的大小。假如输入数据在10MB以内,此时再次计算,则结果为:
实际计算时间=单核处理时间/CPU核数+数据读取时间
=(60min/4)×60+10/50
=900.2s
≈15min
将数据分配到4台4核计算机上同时计算,所需时间为:
实际计算时间=单核处理时间/CPU核数+数据传输时间+数据读取时间
=60×60/(4×4)+(10/12.8)×4+10/50
=230s
≈4min
这个时候采用多台计算机并行计算就可以极大地提升计算速度。类似的应用还有需要进行数据挖掘的应用(比如历史交易分析)、人口统计信息、日志分析等。
3.需要兼顾数据与计算的应用
在实际应用中还存在需要兼顾大数据量与计算量的应用。针对这样的应用,可以采用分而治之的方式,将该应用的不同功能模块根据实际情况采取不同的技术,从而提高计算效率。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。