



通过上一节的例子,我们已经成功地安装了Hadoop,并且使用Hadoop自带的工具对XML文件中的关键字作了排序。但是并没有涉及Hadoop所包含的HDFS以及MapReduce组件。本节将分别介绍。
(1)HDFS
HDFS(Hadoop Distributed File System)是为Hadoop项目开发的分布式文件系统,它采用主/从(master/slave)架构。HDFS由一个NameNode(文件索引服务器)以及众多的DataNode(数据节点)组成。HDFS提供给用户相应的文件命名空间供用户将数据以文件的形式存放。HDFS一般会把这些文件切分为几个文件块,切分后的文件块将被存放在一组数据服务器上。然后由NameNode提供打开、关闭、重命名文件与目录等基本功能,同时负责将文件块映射到DataNode上。再由DataNode负责响应客户端具体文件的读写操作,同时处理由NameNode发起的创建、删除和备份数据块的请求。HDFS的架构如图3-1所示。
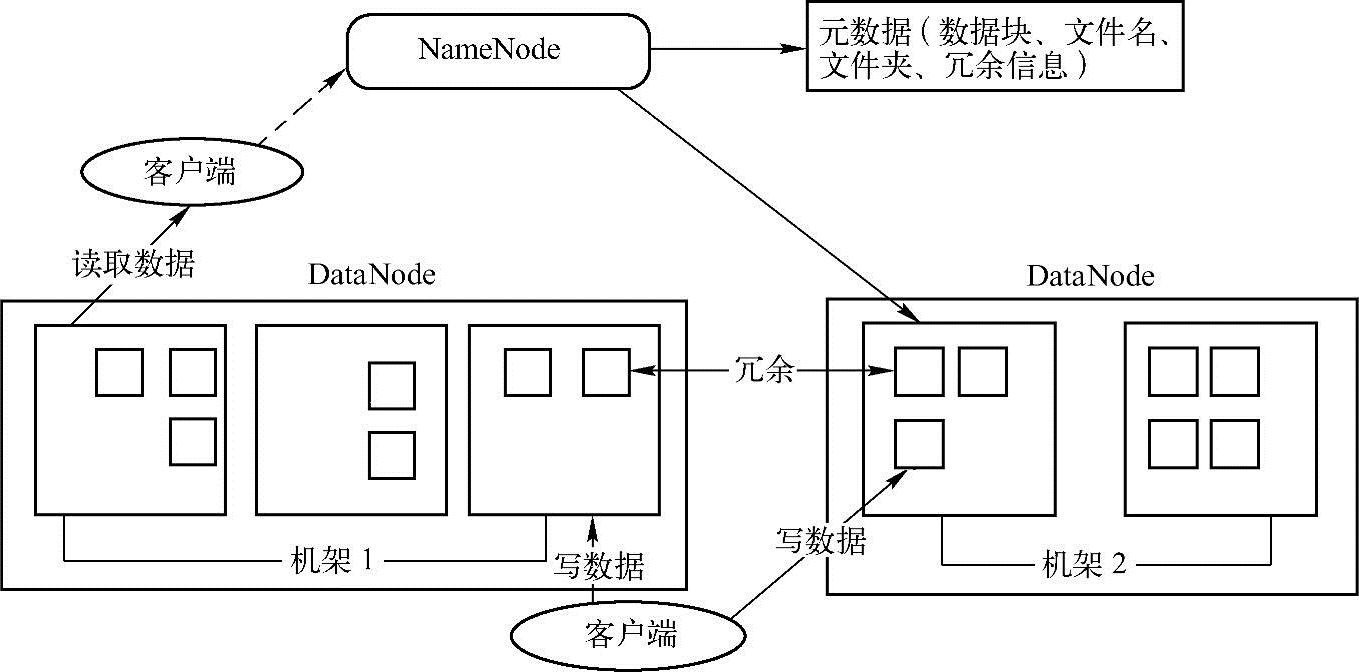
图3-1 HDFS架构
一般而言HDFS在Linux操作系统上运行。由于采用了Java语言,所以理论上任何支持Java语言的操作系统都可以运行NameNode与DataNode。HDFS采用主/从式系统架构,其中的所有元数据都存储在NameNode上,故客户端可以方便地通过NameNode得到全局数据存储状况,但如果出现NameNode死机的情况,用户也将失去访问数据的能力,为此HDFS在新版本中加入了备份NameNode功能,以防止上述故障。
HDFS的好处在于,它支持冗余备份数据,默认情况下,数据会被分成64MB的数据块,这些数据块会被复制到多台DataNode上。此外HDFS支持机架感知技术。具体来说就是用户将机架与主机信息通过脚本的形式提供给Hadoop,Hadoop再把数据在不同机架上进行冗余,这就保证了当一个机架出现故障后,HDFS依然可以正常访问数据。
(2)MapReduce
MapReduce是一种为多台计算机并行处理大量数据而设计的并行计算框架。(https://www.xing528.com)
MapReduce通常将工作的输入数据分割成独立的数据块,分割后的数据一般由多个Map任务并行处理。Mapper从HDFS上取出数据,处理后将结果存储在本地硬盘,Reduc-er在本地硬盘或通过网络方法取得Mapper的输出结果后进一步计算,将结果输出到HDFS。MapReduce框架关注调度任务,并监视任务的执行状况,如果执行失败,将重新执行该任务。
在Hadoop中计算节点通常与存储节点在一起,也就是说HDFS所使用的节点与MapRe- duce所使用的节点相同。这就使得MapReduce框架可以根据数据的存储分布情况来调度任务。
MapReduce框架包含一个独立的主服务器JobTracker(工作分配服务器)及一组与Data-Node安装在一起的从服务器TaskTracker(任务执行服务器)。主服务器负责将任务调度到从服务器上,并监控任务,重新执行失败的任务。
应用程序在HDFS上指定输入与输出位置,并通过实现专门的接口来提供相应的Map和Reduce方法。Hadoop客户端负责发送工作(jar文件或可执行文件等)和配置信息给JobTracker,由JobTracker来分发、调度任务给TaskTracker,并将相应的状态信息反馈给Ha-doop客户端。MapReduce的架构如图3-2所示。

图3-2 MapReduce架构
通过上面的描述,我们对Hadoop的架构有了初步的认识,下面将Hadoop配置到多台计算机上,再次运行刚才在单机Hadoop上运行的查找关键字并按出现次数排序的例子。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。