



传统的监督学习中,学习器通过大量的有标记样本建立模型,用于预测未知样本的标记。随着数据收集和存储技术的飞速发展,收集大量无标记样本变得相当容易,然而获取大量有标记样本则相对困难,对收集到的样本进行标定通常要花费很多时间和精力。事实上,在监测系统的应用问题中,通常存在大量的无标记样本,但有标记样本则相对较少,尤其在监测分类任务中,如果仅使用有标记样本,问题规模将受到很大的限制。
显然,如果仅使用少量的有标记样本,利用它们训练出的学习系统往往很难具有强泛化能力,同时大量廉价的无标记样本弃之不用,是对数据资源的极大浪费。如何利用大量的无标记数据来改善学习性能已成为当前机器学习研究中最受关注的问题之一。这样的学习方法被称为半监督学习或直推式学习。
半监督学习的基本设置是给定一个来自监测系统分布的有标记示例集L=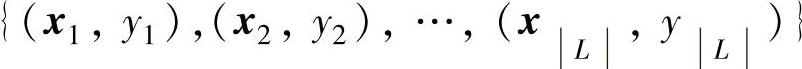 ,以及一个未标记示例集
,以及一个未标记示例集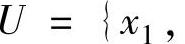
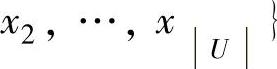 ,期望学得函数f:X→Y可以准确地对样本x预测其标记y。这里xi,xj∈X均为d维向量,yi∈Y为示例xi的标记,L和U分别为L和U的大小,即它们所包含的示例数。
,期望学得函数f:X→Y可以准确地对样本x预测其标记y。这里xi,xj∈X均为d维向量,yi∈Y为示例xi的标记,L和U分别为L和U的大小,即它们所包含的示例数。
在介绍具体的半监督学习技术之前,有必要先探讨一下为什么可以利用未标记示例来改善学习性能。假设所有数据服从于某个由L个高斯分布混合而成的分布,即
其中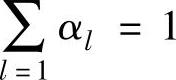 为混合系数,θ={θl}为参数。这样,标记就可视为一个由选定的混合成分mi和特征向量xi以概率P(cixi,mi)决定的随机变量。于是,根据最大后验概率假设,最优分类给出:
为混合系数,θ={θl}为参数。这样,标记就可视为一个由选定的混合成分mi和特征向量xi以概率P(cixi,mi)决定的随机变量。于是,根据最大后验概率假设,最优分类给出:
其中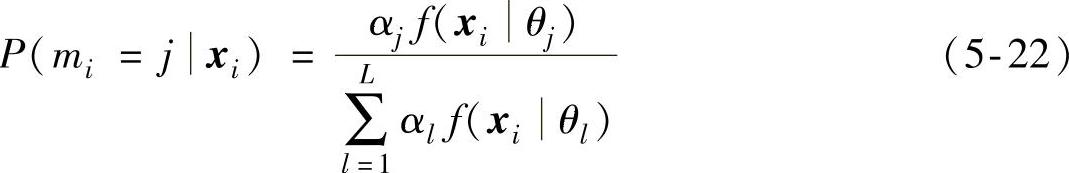
这样,学习目标就变成了利用训练样本来估计P(ci=k|mj=j,xi)和P(mi=j|x)。这两项中的第一项与类别标记有关,而第二项并不依赖于样本的标记,因此,如果有大量的未标记样本可用,则意味着能够用于估计第二项的样本数显著增多,这会使得第二项的估计变得更加准确,从而使得式(5-21)更加准确,也就是说,分类器的泛化能力得以提高。
半监督学习的核心思想,即光滑性假设:
1)距离越近的点越倾向于拥有相同的标记;
2)数据的分布具有某种内在结构(簇或流形)。
目前,利用未标记样本的主流学习技术主要有三大类,即半监督学习(Semi-Supervised Learning)、直推学习(Transductive Learning)和主动学习(Active Learning)。这三类技术都是试图利用大量的未标记样本来辅助对少量有标记样本的学习,但它们的基本思想却有显著的不同。在半监督学习中,学习器试图自行利用未标记样本,即整个学习过程不需要人工干预,仅基于学习器自身对未标记样本进行利用。直推学习与半监督学习的相似之处是它也由学习器自行利用未标记样本,但不同的是,直推学习假定未标记样本就是测试例,即学习的目的就是在这些未标记样本上取得最佳泛化能力。换句话说,半监督学习考虑的是一个“开放世界”,即在进行学习时并不知道要预测的样本是什么,而直推学习考虑的则是一个“封闭世界”,在学习时已经知道了需要预测哪些样本。实际上,直推学习这一思路直接来源于统计学习理论,并被一些学者认为是统计学习理论对机器学习思想的最重要的贡献。
对于半监督学习算法的分类,不同的分类方式会产生不同的分类结果。现有的半监督学习方法通常分为五类:生成式模型(generative model),自训练(self-training),协同训练(co-training),低密度区域分割(avoiding changes in dense regions),基于图的半监督学习方法(graph-based methods)。根据半监督学习的学习方式,可以将半监督学习分成四类,即生成式模型算法、基于图正则化框架的半监督学习算法、协同训练算法以及其他算法。其他算法中主要包括多视图方法和最小化熵方法等。根据半监督学习算法的目的,大致将半监督学习算法分为三类:半监督聚类、半监督分类和半监督回归,其中半监督聚类和半监督分类是目前研究的热点。(https://www.xing528.com)
此外,根据半监督学习算法的发展历程,可以分为以下三个大类:
第一类是从聚类算法发展而来的基于限制条件的半监督聚类算法,该类算法在聚类过程中利用已标注的数据来引导聚类。例如,将已标注数据的类别信息转化为限制条件在聚类过程中遵循,或者利用已标注数据初始化聚类参数并对聚类过程进行约束。
第二类是从经典监督学习中演进而来的,典型代表是自学习算法。该算法在对标记样本进行学习之后,首先处理那些有较高置信度的未标记样本,然后迭代地把这些估计加入到标记样本集中,在经过有限次的迭代后算法生成所有未标记样本的类别标记。
第三类是基于图的算法。该类算法将数据看作图上的节点,将数据间的(已知的)相似性看作节点间的初始边长(权重),应用图的理论对数据进行聚类[18]。
典型的半监督算法包括:将约束条件加入聚类目标函数的算法;强制满足连接约束条件的COP-K均值算法;基于隐马尔可夫随机域模型的HMRF-K均值算法;Generative模型结合EM理论支持的Seeded-K均值和Constrained-K均值算法。其中,Seeded-K均值和Constrained-K均值算法是基于seeds集的,它们用少量带标记数据形成seeds集来改善K均值聚类的初始化效果,进而提高整个数据集上的聚类性能[19]。
在监测系统的实际应用中,随着数据采集技术和存储技术的发展,获取大量的无标记样本已变得非常容易,而获取有标记样本通常需要付出很大的代价。因而,相对于大量的无标记样本,有标记的样本通常会很少。传统的无监督学习只能利用无标记样本学习,监督学习则只利用少量的有标记样本学习,而半监督学习的优越性体现在能够同时利用大量的无标记样本和少量的有标记样本进行学习。
半监督分类法在实际工业中有很重要的意义,参考文献[20]就利用了半监督方法进行行为建模和异常检测。主要步骤包括:
1)通过基于动态时间归整(DTW)的谱聚类方法获取适量的正常行为样本,对正常行为的隐马尔可夫模型(HMM)进行初始化;
2)通过迭代学习的方法在大样本下进一步训练这些隐马尔可夫模型参数;
3)以监督的方式,利用最大后验(MAP)自适应方法估计异常行为的隐马尔可夫模型参数;
4)建立行为的隐马尔可夫拓扑结构模型,用于异常检测。利用半监督分类法可以使得检测系统在大样本的情况下自动地选择正常行为模式的种类和样本来建立正常行为模型,能够在少样本的情况下避免学习问题,建立可靠的异常行为模型,具有很重要的现实意义。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。