



支持向量机(Support Vector Machine,SVM)是一种从少量样本中提取分类信息的机器学习方法。它是一种新型的机器学习方法,克服了传统神经网络在实际应用中存在网络结构难于确定、过学习或欠学习以及局部极小等问题,在模式识别、图像处理、回归分析等方面得到了广泛应用,在数据挖掘、非线性系统建模和控制等领域中展现出了广泛的应用前景。这一理论基础坚实、数学推导严密,在解决小样本、非线性以及高维模式识别问题中显示了无法比拟的优越性。
SVM分类器的设计包括核函数的选取、分类器的设计、训练过程与测试三个过程。
1)核函数的选取:支持向量机的基本思想是使用简单的线性分类器划分样本空间。对于在当前特征空间中线性不可分的模式,则使用一个核函数把样本映射到一个高维空间中,使得样本能够线性可分,例如磨粒分类问题就属于线性不可分模式。常用的核函数为线性核函数、多项式核函数和高斯径向基函数等。
2)分类器的设计:最基本的支持向量机是用于2类问题分类的。对于多类模式识别,支持向量机通常有2种机制:一是“一对一”策略,即一个分类器只用来区分2类问题,通过若干分类器的组合,完成多类识别;二是“一对多”策略,即一个分类器把每一类样本与其他各类区分开来。
3)训练与测试:SVM分类方法存在着算法复杂难以实现训练、算法速度慢以及在实例测试时运算量大等问题。因此,SVM方法如何高效地进行训练和测试成为该分类方法的关键所在。
支持向量机的理论最初来自对数据分类问题的处理。SVM考虑寻找一个超平面,以使训练集中属于不同分类的点正好位于超平面的不同侧面,并且还要使这些点距离该超平面尽可能远,即寻找一个超平面,使其两侧的空白区域最大。
下面举例来说明:
监测系统的训练样本集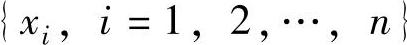 中的每个样本都属于两类(ω1和ω2)中的一个类,相应的标记为yi=±1。线性判别函数可表示为
中的每个样本都属于两类(ω1和ω2)中的一个类,相应的标记为yi=±1。线性判别函数可表示为 (https://www.xing528.com)
(https://www.xing528.com)
决策规则如下:
对于所有的i,若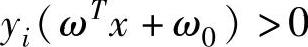 则各训练样本均被正确分类[8]。
则各训练样本均被正确分类[8]。
参考文献[9]将支持向量机应用到油液磨粒的监测系统中。其中,主要是在发动机油液监测系统中,运用支持向量机法对油液中的磨粒进行分类识别。系统主要由磨损模拟部分(摩擦磨损试验机)、油路部分(微量泵、微流控芯片、节流阀、紊流器和过滤器)和图像采集处理部分(显微镜、摄像头图像采集卡、计算机硬件和分析软件)组成。
由于各种磨损形式的磨损机制不同,形成的特征磨粒也不相同。可分为粘着磨损:正常滑动磨粒、严重滑动磨粒;磨料磨损:切削磨粒;疲劳磨损:疲劳剥块、球状磨粒、层状磨粒;腐蚀磨损:红色氧化物微粒、黑色氧化物微粒、亚微米级腐蚀微粒。
利用训练好的支持向量机对磨粒库中的150个测试样本进行磨粒分类。实验结果表明,SVM分类器的推广能力很强。并且,将SVM与最近邻法相结合,可以减少SVM分类器训练的规模,提高分类速度。
随着对SVM研究的不断深入,基于SVM思想的一些模型和方法被广泛应用于各个领域,主要包括:模式识别方面,如人脸识别、字符识别、笔迹鉴别、文本分类、语音鉴别、图像识别、图像分类、图像检索等;回归估计方面,如非线性系统估计、预测预报、建模与控制等;以及网络入侵检测、邮件分类、数据挖掘和知识发现、信号处理、金融预测、生物信息等领域。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。