



一、语义文本文件管理
众包版《纳书楹曲谱》文本语料库的文件命名规则是“Txt_Original_NS_P????”,其中Txt表示文本文件,Original表示原始输入文件,NS表示《纳书楹曲谱》,P表示页码,????表示四个数字格式的页码如,“Txt_Original_NS_P0033.txt”表示第33页的文本内容。
在众包版《纳书楹曲谱》文本语料库中,由于众多人员对文件进行过创建和修改等操作,所以文件管理面临如下的问题:①创建时使用中文文件名或中文目录名,如文件名“纳书楹曲谱P1864.txt”或目录名“201102356完整版”等,导致在某些编程语言(如Matlab)下无法打开类似的带有中文的文件名或目录,也就无法进行后期的文本数据分析;②有些文件在不同目录下重复出现多次,或不同目录下出现同样的文件名或仅页码相同的文件名列表,里面的内容有些一样,有些不一样;③文件名命名随意;④文本文件所在的目录层数不统一。
针对这些错误问题,要采用不同的应对方法来消除和校正。对于问题①和问题③,一般采用手动修改与利用DOS命令ren批量修改相结合的方法;对于问题②,采用人工打开对内容进行比较,结合文件产生时间晚的文件优先的删选方式;对于问题④则利用编程语言Matlab的copyfile命令把不同子目录下的文件复制到一个目录下。
问题④的解决步骤分四步,第一步是用DOS命令dir获取主目录下的所有TXT文件的列表,并将其存入到一个TXT文件中;第二步是对获取的TXT文件进行人工检查,删除一些不是众包版《纳书楹曲谱》文本的文本文件;第三步是把所有不同层数的子目录下的TXT文件复制到一个目录下;第四步是对文件名进行统一,手动修改不规范的文件命名。
第一步,先进入命令行窗口,然后利用DOS的“CD”命令来改变当前目录,进入众包版《纳书楹曲谱》文本语料库文本文件所在的主目录(这里是C:\MATLAB7\work),主目录作为当前目录,然后利用如下的DOS命令获取主目录及其各层子目录下的所有TXT文件的列表到一个文件,DOS命令如下:
Dir*. txt/s/b>NsyAllTxtList.txt
这时,在当前目录下出现了文件NsyAllTxtList.txt,打开NsyAllTxtList.txt,可以看到如下的内容(节选):
显然,当前目录下的各子目录的层次都不相同,人工检查NsyAllTxtList文件中是否包含有不是《纳书楹曲谱》文本内容的文本文件,删除相应的文件名,如必须删除刚产生的NsyAllTxtList这个文件名。
第二步,把不同层次的子目录下的《纳书楹曲谱》文本文件复制到同一目录下,实现算法流程如下:
具体的Matlab代码见附录【代码5-1】,运行【代码5-1】就可以把在文件NsyAllTxtList.txt内的所有文件名的文件复制到同一新目录下。复制完之后,人工检查新目录下的所有文件,对不符合文件命名规范的文件进行文件名修改,对页码相同但文件名不同的文件进行内容审核,留下内容完整性和正确性高的文件。检查完毕后,利用DOS的显示文件列表的命令来获取新目录下所有文件的文件名到一个新的文本文件下,命令行命令格式为:Dir*.txt/s/b>all.txt,这样就得到了一个文本文件all.txt,文件内容包括了所有的《纳书楹曲谱》的语义文本语料库的文本文件名。
二、格式审查
以下的每种审查都需要遍历众包版《纳书楹曲谱》文本语料库的每个文本文件,对每个文本文件的格式和内容进行审查。假设包含众包版《纳书楹曲谱》的文本语料库的文本文件名的文本文件为all.txt,通过读取文本文件all.txt中的每一行文件名,来逐一处理每个文本文件。算法流程如下:
以上算法流程的具体的Matlab代码,见附录【代码5-2】,注意:这里对txt的预处理主要是把它包含的字符转换为汉字字符,用native2unicode函数来处理,其中如果传递给此函数的参数是单回车符,则在Matlab环境下运行时会出现“One dimension must be unary.”的错误提示,所以在【代码5-2】中有对单回车符的处理程序。
上述代码中,“具体业务处理代码”部分可以完成上述的审查工作,这些代码包括如下:
1.括号审查
括号审查主要检查括号的大小写是否有错,左右括号是否配对这两个错误。括号的大小写审查的算法流程如下:
上述算法的自动替换方法的Matlab代码见附录【代码5-3】,运行【代码5-3】可以把文本txt中所有的大写括号自动替换为小写的,只要把替换后的结果保存,即可完成大写括号的审查过程。
在众包版《纳书楹曲谱》的文本语料库中,主要引用了左右方括号和左右圆括号来分别标记谱字和板眼。左右括号是需要配对出现的,但是在录入人员的输入过程中,可能会出现左右括号不配对的现象,这是需要审查和定位不配对的地方,及时修改,以免影响后期处理。配对审查主要审查方括号和圆括号的左右出现的次数是否相同,是否存在无效的左右括号(即左右括号之间无任何内容),有没有出现嵌套的左右括号这三种情况。审查的算法流程如下:
上述算法流程的Matlab代码见附录【代码5-4】。运行【代码5-3】和【代码5-4】,对众包版《纳书楹曲谱》的文本语料库的输入文本进行错误挖掘,一共挖掘出613个不同类型的括号错误,它们的统计信息和举例见表5-1。
表5-1 对众包版《纳书楹曲谱》的文本语料库的括号错误挖掘统计
括号审查可以检查出大小写混用错误,如第728页第3行存在一个大小写问题,一个右括号“)”是大写,应该是小写;缺少配对的括号问题,如第2132页的第2行、第2190页的第4行、第2222页的第3行和第2226页的第1行都少了个右括号;多余的括号问题,在第2133页的第2行的曲词前多加了一个左括号。
对挖掘出的和括号相关的错误所在的文本文件进行人工检查和修改,并直接对修改结果进行保存。
2.行列审查
《纳书楹曲谱》纸质书籍有近三千页,每页谱面的曲谱信息都一列一列按右到左的顺序显示,每列由若干个曲词构成,每个曲词右边依附着若干个谱字和板眼。就曲词的呈现方式而言,在《纳书楹曲谱》的页面谱面上,一页谱面包含6列曲词列,每列包含18个曲词。如图5-4所示的《纳书楹曲谱》谱例中,包含有6列曲词,每列包含的曲词个数分别是24、6、19、18、10、18,右边第一列的数量为24,其中不仅有曲词还有曲谱说明;第三列数量为19,其中有曲词和曲调(仙吕)、曲牌(拨柞弹)等;还有两列是曲牌结束列,所有数量不满18个。
图5-4 《纳书楹曲谱》谱例
众包版《纳书楹曲谱》的语料库文本的行列录入方式,要求按纸质书籍的谱面规则来进行,即纸质书籍的一列对应语义文本的一行。而在实际录入过程中,可能会出现一些不符的现象,如纸质书籍的一列在输入时被分成多行、纸质书籍的连续多列在输入时被合并成一行等。
(1)列审查。列审查的目的就是在众包版《纳书楹曲谱》的文本语料库中找出所有列数大于6的文本文件,然后逐一进行人工审查,对不符合要求的文本进行校正。审查的算法流程是:
上述算法的Matlab代码见附录【代码5-5】,运行此代码可以得到众包版《纳书楹曲谱》的部分文本语料库所有谱面页包含的曲词列数的统计数量,如表5-2所示为不同列数的页码总数。
表5-2 众包版《纳书楹曲谱》部分文本语料库的不同列数的页码统计
很显然,曲词列数为6的曲谱页最多,在校正前,列数大于6的页数有74个,逐一对这些页面进行人工审查。审查发现这些超过6列的页码,有47个页面是曲谱目录,13个页面是目录后的第一个曲谱,带有卷数说明,1个页面是题跋,有1个页面包含着曲谱说明;还有8个错误页面是把一行文本拆分成二行,另外4个页面的文本第一行加了无用的信息,曲词列错误总数占比不到总数的0.65%。
(2)行审查。为了找出多列曲词输入成一行文本的错误现象,对众包版《纳书楹曲谱》的文本语料库的每行包含的曲词数量进行统计,然后对曲词个数大于18的文件进行人工审查。每行曲词统计的算法流程如下:
上述算法的Matlab代码见附录【代码5-6】,运行此代码可以得到众包版《纳书楹曲谱》的文本语料库所有行包含的曲词个数的统计数量。
表5-3为众包版《纳书楹曲谱》文本语料库的不同曲词数量的曲词行的统计,其中校正后是指对校正前曲词行行内曲词个数大于22的38行曲词行进行一一人工审查并修改后重新统计的结果(总行数:校正前为10259行,校正后为10249行)。
表5-3 众包版《纳书楹曲谱》文本语料库的不同曲词数量的行数统计
观察表5-3可知,一行内曲词数量为18的行数最多,而大于18的曲词也有一千多行。对表5-3的行内曲词数量大于22的38行曲词行进行一一审查,发现了三类错误现象,一是把多行曲词行并为一行曲词,共有6行曲词行存在此错误现象;二是谱字在方括号外,导致运行算法时被统计入曲词个数中,共有3行曲词行存在此错误现象;其余29行曲词行因为包含了曲牌或曲谱说明,所以导致整行字数大于22。(https://www.xing528.com)
利用列审查和行审查的信息对语料库进行校正,校正前后的曲词总行数不同,这不仅是因为把校正前的合并的行拆分成两行或多行,增加了总行数,也有些是一行拆分成二行或多行,这些都影响到了总行数。
3.逗号审查
逗号在众包版《纳书楹曲谱》的文本语料库中,主要加在曲调名称、曲牌名称、曲谱转向说明等的后面,用于和其他曲词区分。在语料库录入过程中,可能会出现逗号使用不当的情况,如出现大写逗号、逗号不使用或多使用的现象。
逗号审查的算法流程如下:
上述算法的Matlab代码见附录【代码5-7】,运行此代码可以得到众包版《纳书楹曲谱》的文本语料库所有行包含的逗号个数的统计数量,如表5-4所示为众包版《纳书楹曲谱》文本语料库的不同逗号数量的曲词行的统计。
表5-4 众包版《纳书楹曲谱》文本语料库的不同逗号数量的行数统计
观察表5-4可知,包含1个逗号的曲词行最多,对逗号数量大于4个的曲词行进行人工审查,发现要么是输入了多余的逗号,要么是把曲谱的音乐转向说明的顺序输入错误,如把“普天樂五至末”输入为“譜五,天至,樂末”等,对发现的错误逐一进行了校正。校正后统计的不同逗号数量的行数有所变化,逗号数下降,但行数合计并没变。
三、《纳书楹曲谱》文本语料库的内容审核
1.谱字审查
谱字审查主要审查在左右方括号内是否存在非谱字符号,方括号外是否存在谱字符号。《纳书楹曲谱》最常见的十七个谱字,即“合四一上尺工凡六五乙仩伬仜仉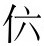 伍亿”,同时对于模糊不清的谱字用问号“?”表示,因此,如果在左右方括号内有这些谱字或问号以外的字符,那么就是谱字输入错误。在方括号外,字符主要由标题、曲词和曲牌名等汉字组成,而常见的十三个谱字中,前十个谱字作为汉字在方括号外普遍存在,所以,只需审查是否在方括号外存在“仩伬仜仉伍亿”这七个谱字即可。
伍亿”,同时对于模糊不清的谱字用问号“?”表示,因此,如果在左右方括号内有这些谱字或问号以外的字符,那么就是谱字输入错误。在方括号外,字符主要由标题、曲词和曲牌名等汉字组成,而常见的十三个谱字中,前十个谱字作为汉字在方括号外普遍存在,所以,只需审查是否在方括号外存在“仩伬仜仉伍亿”这七个谱字即可。
算法先获取当前文本内容中的左右方括号和左右圆括号的位置,然后删除每对圆括号和圆括号内的文本内容,接着把余下的文本内容分割成两个部分,一部分是方括号文本内容,另一部分是非方括号文本内容,在非方括号内容中查找《纳书楹曲谱》出现的三个谱字,在方括号内容中查找十七个谱字以外的字符。
谱字审查的算法流程如下:
上述算法的Matlab代码见附录【代码5-8】,运行此代码,对众包版《纳书楹曲谱》的文本语料库的输入文本进行错误挖掘,一共挖掘出157个不同类型的谱字错误,它们的统计信息和举例如表5-5所示。
表5-5 众包版《纳书楹曲谱》的文本语料库的谱字错误挖掘统计
典型的谱字错误有把谱字“乙”输入为“乚”等。由于挖掘出的和谱字相关的错误数量较多,所以采用设计程序修改和人工修改相结合的方式,提高修改效率。其中空格问题利用程序进行自动修复,对于其他的错误,则采用逐一进行人工检查和修改的方法。
针对方括号内存在空格的现象,采用设计程序进行自动修改的校正策略,实现用的算法流程如下:
上述算法的具体Matlab代码见附录【代码5-9】,运行此代码,在《纳书楹曲谱》的语义文本语料库的文本文件中有90个空格被删除。然后利用新建的文件替换原有的文件,实现对空格的校正操作。
2.板眼审查
由于在设计昆曲语义文本格式时,要求所有的板眼符号都放在小写的左右圆括号(“()”)内,并规定了每个板眼的符号,如对于《纳书楹曲谱》而言,这些板眼符号分别是“头板(丶)、腰中眼(△)、头赠板(╳)、中眼(〇)、底板(━)、腰赠板(|╳)、腰板(∟)”,其他符号都不能出现,但是在实际输入中,往往会出现把一些错误的符号放入圆括号(“()”)内的现象,或把板眼符号放在圆括号之外。
板眼审查主要是检查在左右圆括号之间是否存在有非板眼符号,以及在左右圆括号外是否存在板眼符号。由于问号(“?”)是模糊不清的板眼的替代,所以在圆括号内出现问号字符是符合规则的。板眼审查先获取当前文本内容中的左右圆括号的位置,接着把文本内容分割成两个部分,一个部分是圆括号文本内容,一个是非圆括号文本内容,在非圆括号内容中查找《纳书楹曲谱》出现的七个板眼,在圆括号内容中删除《纳书楹曲谱》出现的七个谱字,最后根据实际情况进行人工修改。算法流程如下:
上述算法的Matlab代码见附录【代码5-10】,运行此代码,可以发现在《纳书楹曲谱》的语义文本语料库的文本文件中圆括号内有85个非板眼符号,圆括号外存在83个板眼符号,共156个需要人工审查和校正的符号。它们的举例如表5-6所示。
表5-6 《纳书楹曲谱》的输入语义文本语料库的板眼错误挖掘统计
一些典型的板眼错误符号包括:把底板符号“(━)”输入为“(一)”,把中眼符号(〇)输入为方中眼“(□)”或小圆中眼“(〇)”,把腰赠板“(|╳)”输入为另一符号“(丨╳)”等,也包括在圆括号内出现汉字的,如“(南西廂)、(西樓記)、(紅梨記)、(夜樂)”等,或者在圆括号内出现谱字符号的现象,如“(∟工尺上)、(〇五)、(〇五)、(〇五)、(〇工)”等。
3.问号审查
由于古籍《纳书楹曲谱》纸质书籍的年代久远,一些有效的信息已经模糊不清、无法分辨准确,由于问号在中国古代文献中尚未被使用,在语义文本格式设计时,利用标点符号问号“?”来表示这些模糊不清的字符,如标题、曲牌、曲词、谱字或板眼等字符,因此在《纳书楹曲谱》的文本语料库中,任何位置都可能出现问号字符。
问号审查的目的是查找《纳书楹曲谱》的文本语料库中出现的问号是否都是小写字符,如果出现大写字符,那么进行人工修改。查找大写问号字符的算法流程如下:
上述算法的实现代码见附录【代码5-11】,运行此代码,可以查找到40个大写的问号出现在《纳书楹曲谱》的文本语料库中,分别人工进行进一步的检查和校正。
《纳书楹曲谱》的文本语料库的文本文件中,问号字符可能表示的是板眼符号或谱字符号或其他符号,统计不同含义的问号,以及定位问号的位置,对人工校正曲谱具有很好的参考意义。问号数量统计的算法流程如下:
上述算法流程的具体代码见附录【代码5-12】,运行此代码,可以统计出问号谱字字符有1606个,问号板眼字符有162个,其他问号字符有1805个。以上利用昆曲的语义文本的构建规则,对众包版《纳书楹曲谱》的文本语料库的文本文件中包含的错误和模糊字符进行了挖掘,这些字符占整个语料库的字符数相对较少。
4.曲牌审查
《纳书楹曲谱》的每个折子戏由若干个乐段组成,大多数的乐段由曲牌组成并在曲谱开始处注明了所使用的曲牌,可以利用这个规律对众包版《纳书楹曲谱》的文本语料库进行审查,发现不符合此规律的现象。具体算法流程如下:
上述算法流程的具体代码见附录【代码5-13】,运行此代码,可以统计众包版《纳书楹曲谱》的文本语料库中漏输曲词情况和其他现象,如表5-7所示,在曲词列中出现叠词,或者曲词列的最后一个词,往往会发生曲词漏输入现象。
表5-7 众包版《纳书楹曲谱》的文本语料库的无曲牌乐段和曲词漏输情况
曲牌在众包录入过程中,由于曲牌名为繁体字或字体模糊等原因,会发生录入错误现象,如把曲牌名“解三酲”录入成“解三醒”,把“鬭鵪鶉”录入成“鬭鵪鵓”或“鬪鹌鹑”等。利用上述算法可以得到所有曲牌名,然后人工对这些曲牌名进行审查并及时修改文本语料库。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。