



命令grep(global search regular expression and print out the line,全面搜索正则表达式并把行打印出来)是一个过滤器,它可以对一个或者多个文件按照某种字符串模式(pattern)搜索出相应的内容,它的一般格式为:
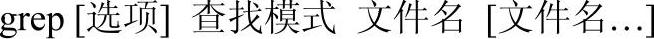
例如,文件name_list.txt有两列,分别是名字和性别:

列出文件中的男孩:
列出文件中的女孩:

grep命令的输入也可以来自管道。例如,要查询都有谁登录了Linux服务器,可以用who命令:
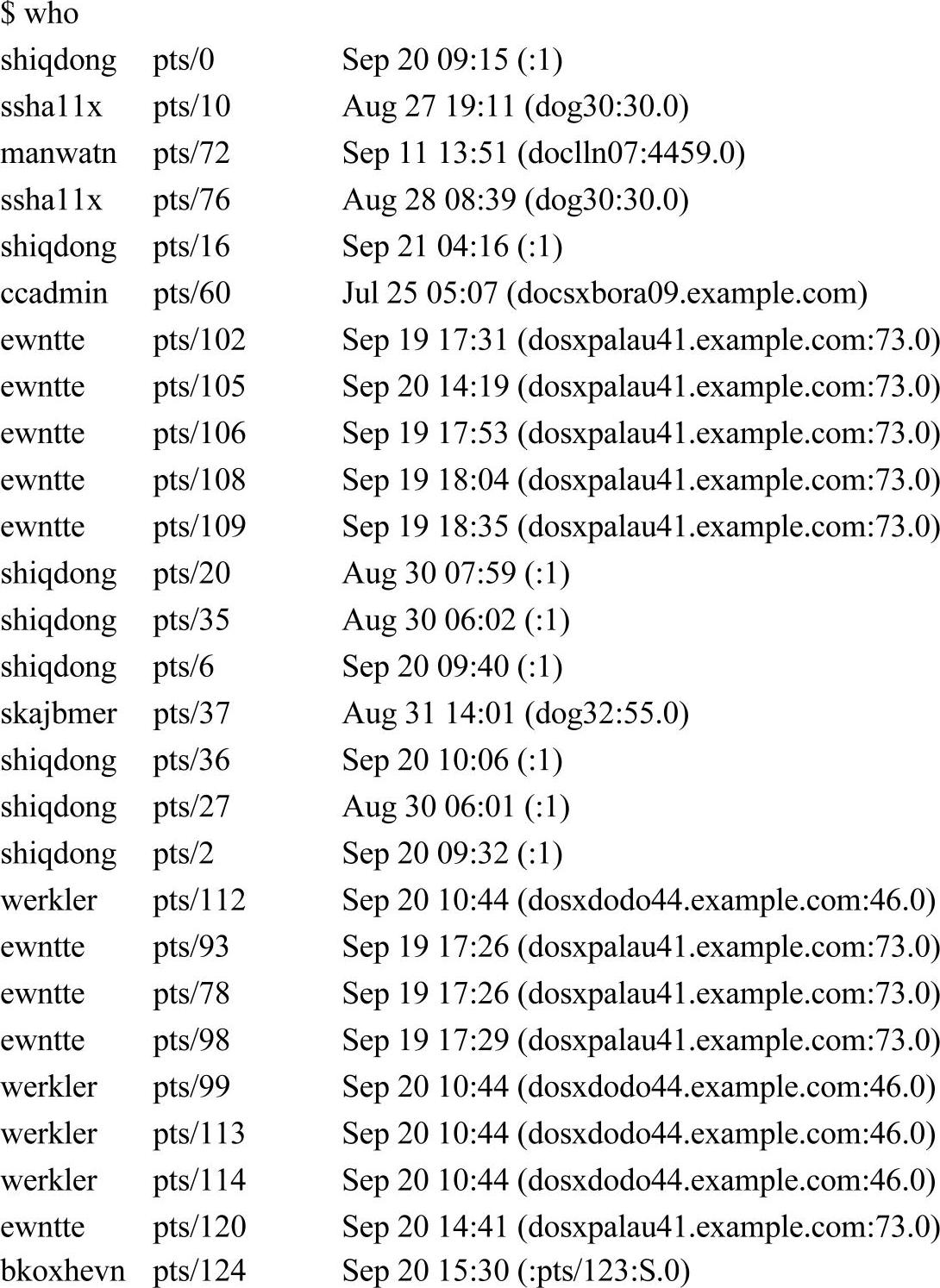
而要查询一下某个账户如werkler登录了没有,在哪里登录的,在长长的名单里用肉眼查找很困难。此时使用grep命令对who命令的输出过滤一下就知道了:

上面的命令是将命令who的输出过滤一下,只显示包含字符串werkler的行。如果只记得账户的前2个字符为we、后2个字符为er,可以这样查找:
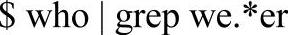

其中“.”表示任何单个字符,“*”表示匹配零次或者多次,“.*”就表示零个或任意多个字符。常用的模式匹配字符及含义见表8-1。
表8-1 模式匹配
下面举例说明表8-1中相关的内容。注意下面的文件一共4行,其中第3行是空行:

因为“.”代表任意一个字符,所以grep.会过滤出非空行:


过滤出包含map的行:

grep的选项-i或者--ignore-case用来忽略字母大小写,过滤出包含map(忽略大小写)的行:

表8-1中的^和$叫做锚。锚指明了正则表达式在一行文本中要匹配的位置,如\b,\<和\>也是锚。下面过滤出以map开头的行:

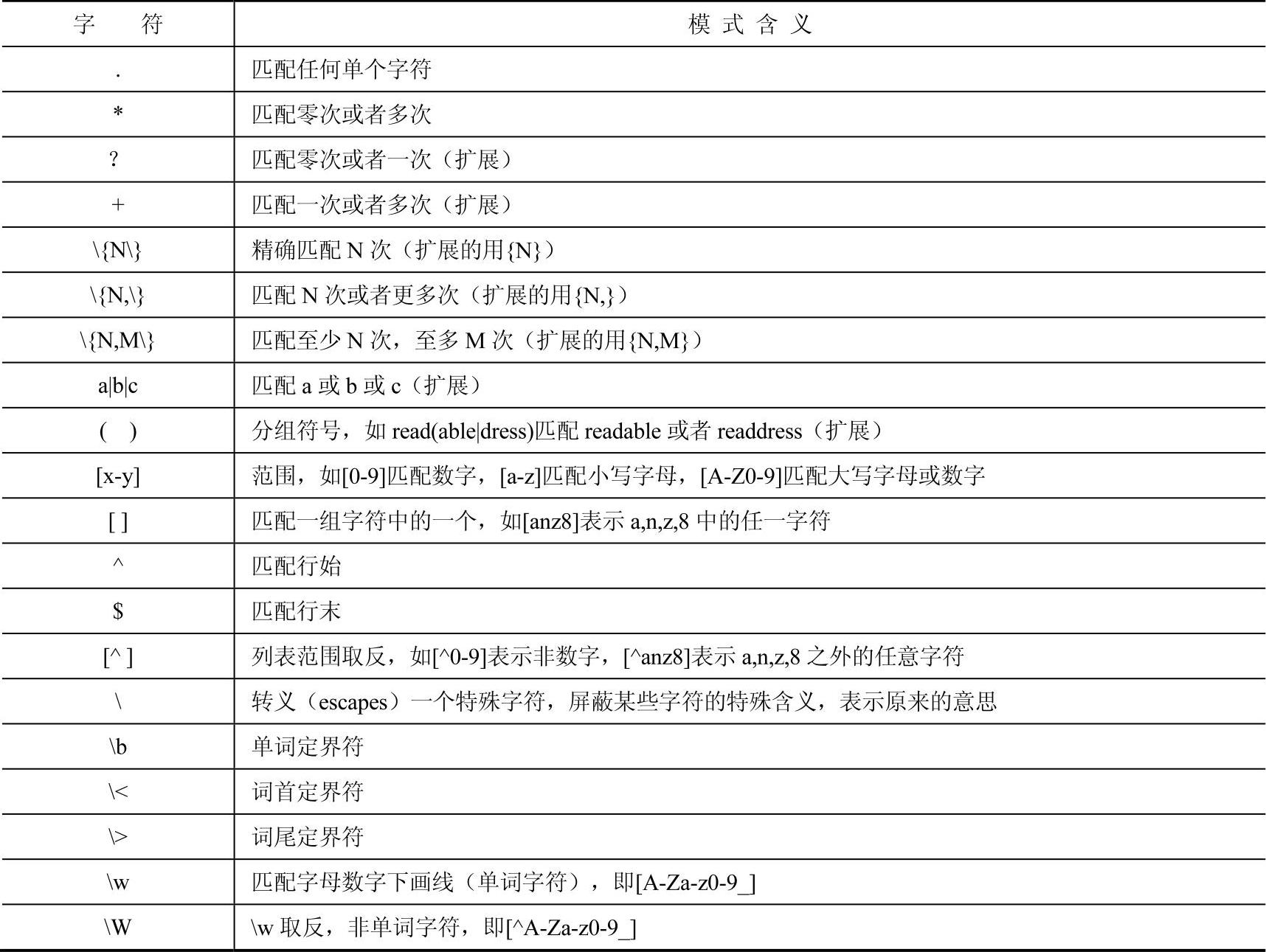
过滤出以book结尾的行:
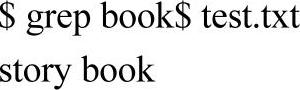
^匹配行始,$匹配行尾,那么^$匹配空行:
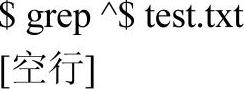
grep的选项-v用来取反(invert)匹配。命令grep-v^$的作用就是匹配非空行:

假设文件test.txt现在变为如下内容:(https://www.xing528.com)

显示包含阿拉伯数字的行:

显示包含非阿拉伯数字的行:

不显示包含阿拉伯数字的行,其他行都显示:

正则表达式里面的“^”和grep命令的选项-v,都有取反的功能,但是具体作用是不一样的。细细比较并体会前面的两个例子就清楚了。
下面显示出包含2个连续字母o的行:
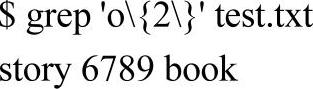
下面显示出包含至少5个连续的阿拉伯数字的行:
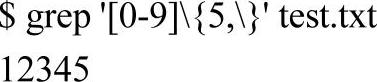
如果想在当前目录下的所有文件中搜索book,运行grepbook*,*被替换为当前目录下的所有文件:
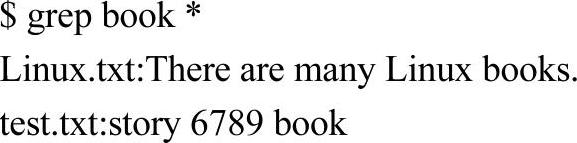
上面的输出表示文件Linux.txt和test.txt包含book,相应的整行内容也显示出来了。如果只想知道哪些文件包含book,用选项-l:

选项-n的作用是显示匹配行在文件中的行号:

上面的输出表示文件Linux.txt的第3行和test.txt的第3行包含book,相应的整行内容也显示出来了。
在匹配.和*等特殊字符本身的时候需要注意,要用反斜杠屏蔽其特殊的含义。先看一个文件:

要想过滤出包含*的行,直接运行grep*star.txt是不行的,因为,在命令行中,*被替换为当前目录下的所有文件,在*前面加反斜杠(或者在*的两边加单引号或双引号)才可以过滤出包含*的行:

grep命令的选项-c或者--count的作用是显示匹配的次数。文件star.txt中包含*的行有两行,所以下面命令的结果为2:

过滤出包含.的行:
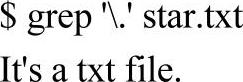
直接运行grep.star.txt是不行的,感兴趣的话,可以试试。
下面是关于单词定界符的例子,文件man.txt的内容及相关例子如下:

过滤出包含以t开头、以e结尾、中间有两个字符的单词的行:
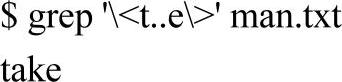
过滤出包含以t开头、以e结尾、中间有任意个字符的单词的行:
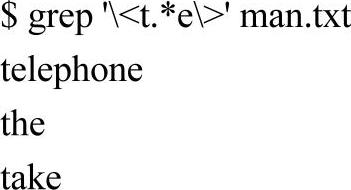
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。