



显式语义分析(Explicit Semantic Analysis,ESA)算法[16,99−100]是常见的基于知识库的短文本概念化典型算法。为了便于表述,本书将短文本中的词语集合表示为![]() ,将短文本概念化算法得到的最优概念集合表示为
,将短文本概念化算法得到的最优概念集合表示为![]() 。
。
显式语义分析(ESA)算法通常将Wikipedia文章视为概念,旨在构造在维基百科文章全集上的分布来显式地表示短文本的语义[99−100,119]。ESA算法通常使用![]() 来表示词语wi的概念向量。通常,可以将
来表示词语wi的概念向量。通常,可以将![]() 定义为衡量词语wi和候选概念cj共现的函数
定义为衡量词语wi和候选概念cj共现的函数![]() 。原始的ESA算法通常使用词语wi在描述概念cj的维基百科文章页面上的词频−逆文档频率(Term Frequency-Inverse Document Frequency,TF−IDF)值来表示
。原始的ESA算法通常使用词语wi在描述概念cj的维基百科文章页面上的词频−逆文档频率(Term Frequency-Inverse Document Frequency,TF−IDF)值来表示![]() 。另外,本书使用向量
。另外,本书使用向量![]() 来表示描述包含词语集合
来表示描述包含词语集合![]() 的整个短文本的概念分布。因此,ESA算法使用下式计算给定短文本的概念化向量表示:
的整个短文本的概念分布。因此,ESA算法使用下式计算给定短文本的概念化向量表示:
式中,![]() ——词语wi的权重,即词语wi在给定短文本中的TF−IDF值。
——词语wi的权重,即词语wi在给定短文本中的TF−IDF值。
这种概念映射方式的优点在于,概念向量![]() 中的值不局限于共现频率,还可以使用其他方式表示。相较于传统潜在语义分析(Latent Semantic Analysis,LSA)方法[12]和传统潜在狄利克雷分布(Latent Dirichlet Allocation,LDA)方法[13],ESA算法能够提供更多可解释的语义信息。
中的值不局限于共现频率,还可以使用其他方式表示。相较于传统潜在语义分析(Latent Semantic Analysis,LSA)方法[12]和传统潜在狄利克雷分布(Latent Dirichlet Allocation,LDA)方法[13],ESA算法能够提供更多可解释的语义信息。
ESA算法可被视为一个生成式模型,因为该模型将“概念−词语”关系用作产生词语特征的依据,并且使用这些产生的特征来估计生成潜在概念分布。将概率![]() 定义如下:(https://www.xing528.com)
定义如下:(https://www.xing528.com)
式中,![]() 可以视作一个高斯分布,而且具备较强灵活性、无须被进一步分解为
可以视作一个高斯分布,而且具备较强灵活性、无须被进一步分解为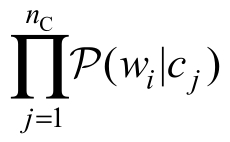 。例如,概念向量
。例如,概念向量![]() 中的元素
中的元素![]() 既可以是概念cj和词语wi在大规模语料库中同一句子(或同一文档)中的共现频数,也可以定义为
既可以是概念cj和词语wi在大规模语料库中同一句子(或同一文档)中的共现频数,也可以定义为![]() 表示为概念cj描述词语wi的概率。
表示为概念cj描述词语wi的概率。
式(7−3)也解释了显式语义分析假设给定短文本中的词语只有一个类簇。为了缓解这个约束,可以采取的直观方法是使用聚类算法来假设存在多个概念类簇。
显式语义分析算法存在如下缺陷:得到的概念向量的噪声可能比较大。以短文本“microsoft unveils office for apple’s ipad”为例。显然,词语“apple”在当前语境中不应当属于概念FRUIT(水果),但是简单地将词语wi的概念向量![]() 加权求和,导致引入概念FRUIT来表示这个文本。这种计算方式背后存在一个假设,即认为这个短文本中只表述了单一的概念(即仅存在一个语义类簇),使用概念向量的加权求和来表示文本,而忽略了词语的语义及关联关系。特别地,语义歧义现象在诸如微博文本和搜索引擎查询等短文本中是很严重的,因为可用的词语越多,一词多义现象的负面影响就会被降得越低,但是短文本受限于篇幅,无法提供更多的上下文语境词语。此外,不同于传统主题模型方法使用词袋表示主题,ESA算法使用维基百科文章集合上的分布表示主题,这种分布与人类精神世界中的概念还是存在较大差距的。
加权求和,导致引入概念FRUIT来表示这个文本。这种计算方式背后存在一个假设,即认为这个短文本中只表述了单一的概念(即仅存在一个语义类簇),使用概念向量的加权求和来表示文本,而忽略了词语的语义及关联关系。特别地,语义歧义现象在诸如微博文本和搜索引擎查询等短文本中是很严重的,因为可用的词语越多,一词多义现象的负面影响就会被降得越低,但是短文本受限于篇幅,无法提供更多的上下文语境词语。此外,不同于传统主题模型方法使用词袋表示主题,ESA算法使用维基百科文章集合上的分布表示主题,这种分布与人类精神世界中的概念还是存在较大差距的。
从另一个角度,在模型选择层面,短文本概念化研究及相关理论方法可以分为三个方向:描述式模型(Descriptive Model)、生成式模型(Generative Model)和判别式模型(Discriminative Model)[10]。同上,词语集合表示为![]()
![]() ,将短文本概念化算法得到的最优概念集合表示为
,将短文本概念化算法得到的最优概念集合表示为![]()
![]() 。那么,描述式模型和生成式模型旨在建模概率
。那么,描述式模型和生成式模型旨在建模概率![]()
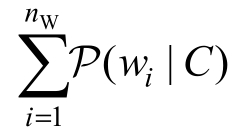 ,判别式模型则直接建模概率P(C|W)。但是,以往上述三个模型在 应用于概念化研究时,往往都存在词语独立假设:在描述式模型中,概率概念化可以被视为一个因果马尔可夫模型(Causal Markov Model),因为描述式模型强调概念−词语关系的概率的局部顺序;ESA算法是典型的生成式模型,因此其使用概念−词语关系作为词语特征的生成依据,并估计生成这些特征的潜在概念分布;实现概念化的另一个途径是将短文本分类到预先定义的类目中,“分类”(Classification)可以被认为是一个判别式模型,直接对概率P(C|W)进行建模来估计得到最优概念集合C,但是通常当候选概念数量比较大的时候,判别式模型的计算开销是非常高昂的。例如,可以学习得到一组投射向量
,判别式模型则直接建模概率P(C|W)。但是,以往上述三个模型在 应用于概念化研究时,往往都存在词语独立假设:在描述式模型中,概率概念化可以被视为一个因果马尔可夫模型(Causal Markov Model),因为描述式模型强调概念−词语关系的概率的局部顺序;ESA算法是典型的生成式模型,因此其使用概念−词语关系作为词语特征的生成依据,并估计生成这些特征的潜在概念分布;实现概念化的另一个途径是将短文本分类到预先定义的类目中,“分类”(Classification)可以被认为是一个判别式模型,直接对概率P(C|W)进行建模来估计得到最优概念集合C,但是通常当候选概念数量比较大的时候,判别式模型的计算开销是非常高昂的。例如,可以学习得到一组投射向量![]() 使
使![]() 最大化,其中Ω表示配分函数,
最大化,其中Ω表示配分函数,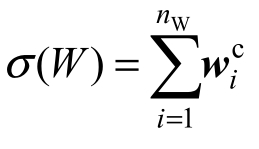 ,在这种情况下,概念向量被视为用于生成给定短文本全局表示的特征向量。
,在这种情况下,概念向量被视为用于生成给定短文本全局表示的特征向量。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。