



与使用层次化Softmax的目的一样,负采样技术的引入也是为了降低计算时间复杂度。负采样是噪声对比评估(Noise Contrastive Estimation,NCE)的一个变体。NCE最初被用于加速训练统计语言模型[32,43,46−49],并证明一个性能良好的模型应该能够通过逻辑回归(Logistic Regression,LR)方法很好地将数据从噪声中区分,这一点类似于C&W模型[45]在噪声上对数据进行排序来训练模型。与层次化Softmax算法相比,负采样算法不再使用复杂的哈夫曼树,而使用相对简单的随机负采样,进而大幅度提高性能。负采样算法可以作为层次化Softmax算法的一种替代。
在CBOW模型和Skip-Gram模型中,训练的最终目标是快速学习得到高质量的词向量,因此可以将NCE方法进行简化,得到负采样算法,其优化的目标如下:
式中,wi,wo——输入词语、输出词语;
wi——词语wi的向量;
 ——噪声词语,即负例,
——噪声词语,即负例,![]() ;
;
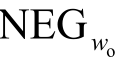 ——词语wo的负例集合;
——词语wo的负例集合;
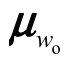 ——词语wo对应的负采样参数向量;(https://www.xing528.com)
——词语wo对应的负采样参数向量;(https://www.xing528.com)
σ(x)——Sigmoid函数。
通过最大化L(wo|wi)来训练以词语wi为输入、以词语wo为输出的逻辑回归模型,能够将目标词语wo从噪声中区分。负采样算法在CBOW模型和Skip-Gram模型中的成功应用,已经证明其可以显著提升训练效率和训练结果质量[50]。负采样算法与NCE算法的最大区别在于:NCE算法不仅需要噪声分布的样本,还需要噪声分布的数值概率值,而负采样算法仅需要样本即可;NCE算法近似最大化Softmax的对数概率,而负采样算法无须这样处理。在NCE算法和负采样算法中,噪声分布是一个自由参数,以阶数为3/4的一元分布为例,其效果通常优于均匀分布以及阶数为1的一元分布,其概率形式定义如下:
式中,n(w)——词语w在语料中出现的次数;
U(w)——词语w在语料中的一元概率,即词语w在语料中的出现概率;
Z——归一化项,确保![]() 。
。
此外,以往研究发现,高频词语在训练时会被训练多次,然而这些高频词语相较于一些低频词语而言所提供的信息较少,例如,“the”“a”“in”等高频词语会耗时很多,但对模型质量的影响不大;此外,这些词语也几乎与其他词语都存在共现关系。因此,通常采用如下方式处理高频词语。在训练过程中,每个词语w都有概率PIGN(w)被忽略而不被训练,![]() ,阈值参数 ξ 通常取值为10−5。由上述定义可知,出现频率越高的词语越有可能被忽略而不被训练。
,阈值参数 ξ 通常取值为10−5。由上述定义可知,出现频率越高的词语越有可能被忽略而不被训练。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。