



1.对通信的基本要求
创建一个项目(见随书光盘中的例程MPI_UC_5),生成3个站,一个站的CPU为CPU413-2DP,另外两个站的CPU为CPU 315-2DP(见图14-34),在NetPro中将它们连接到MPI网络上,它们的MPI站地址分别为2、3、4(见图14-35)。
要求通信按下述的顺序进行:
1)2号站调用X_PUT写3号站的数据。
2)2号站调用X_GET读3号站的数据。
3)2号站调用X_SEND向3号站发送数据,3号站调用X_RCV接收数据。
4)2号站调用X_ABORT断开与3号站的连接。
5)2号站调用X_SEND向4号站发送数据,4号站调用X_RCV接收数据。
6)2号站调用X_ABORT断开与4号站的连接。
上述通信操作周期性地反复进行。
在通信过程中,应保证2号站同时只能调用一个通信SFC。通信程序用顺序控制设计法来编写,顺序功能图(请参阅参考文献[2]的5.2节)如图14-33所示。
通信SFC执行的时间较长,可以通过通信SFC的输出参数BUSY(M10x.4)的状态来判断通信任务是否结束。BUSY为1状态时,表示通信任务尚未完成,为0状态时表示通信任务结束。因此用SFC的BUSY信号(M10x.4)的下降沿作为相邻步之间的转换条件。顺序功能图中转换条件M10x.4左边的“↓”表示下降沿有效。
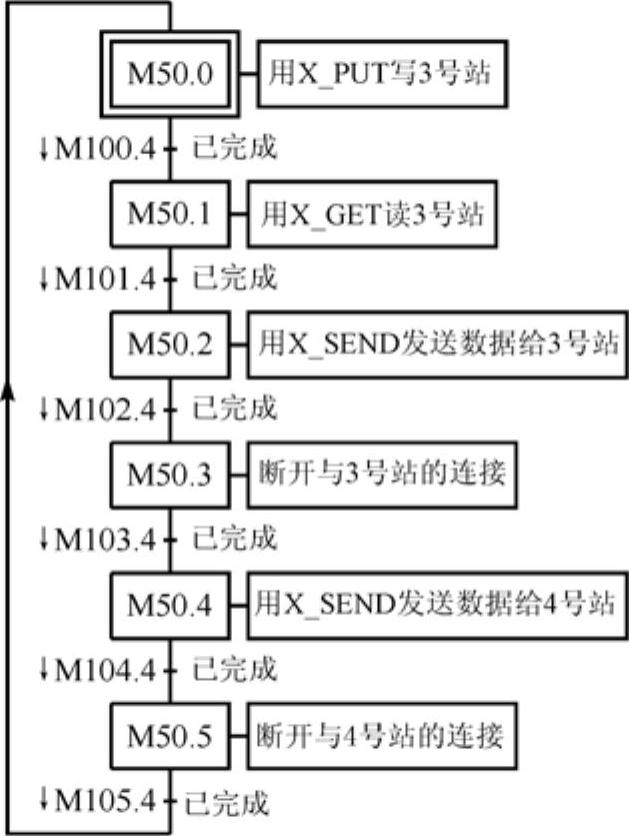
图14-33 2号站的顺序功能图
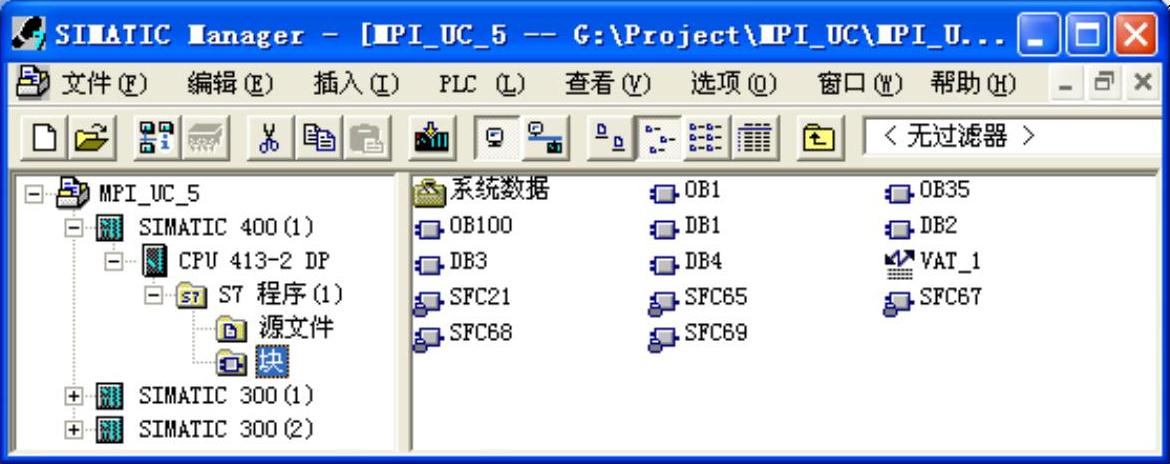
图14-34 SIMATIC管理器
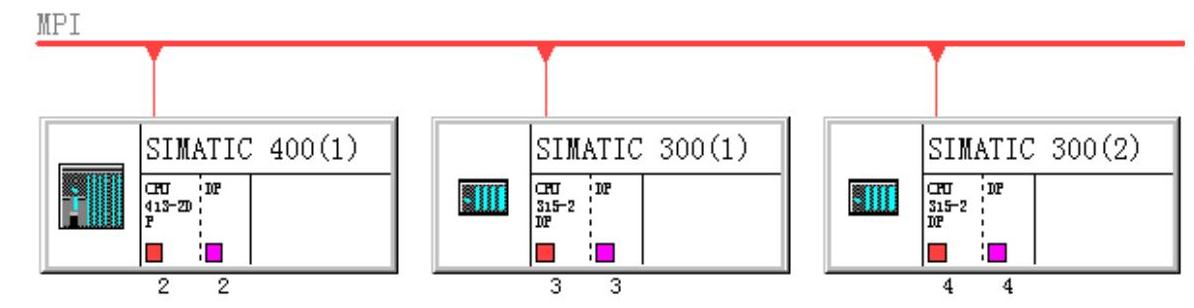
图14-35 MPI网络
2.顺序控制程序
在2号站的初始化程序OB100中,将顺序功能图中初始步对应的M50.0置位为1,将其余各步对应的存储器位复位为0,具体程序如下:
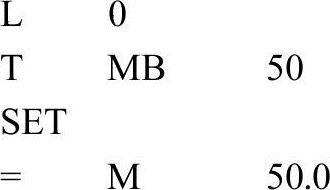
下面是用参考文献[2]的5.4节中的方法编写的2号站的OB1中的顺序控制程序:
程序段1:

程序段2:

程序段3:

程序段4:
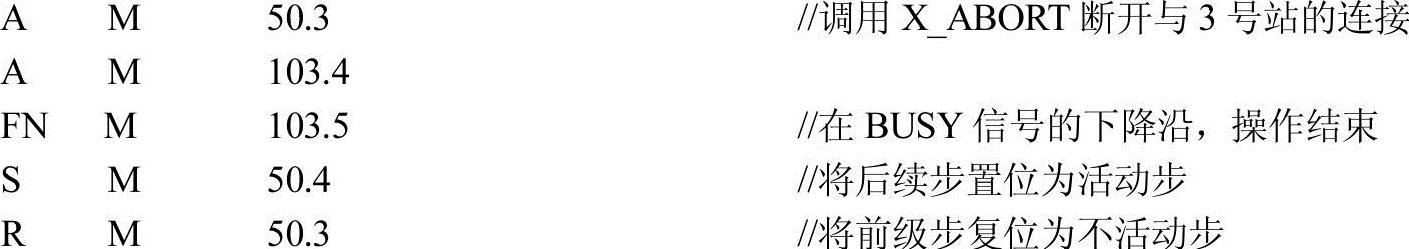
程序段5:

程序段6:
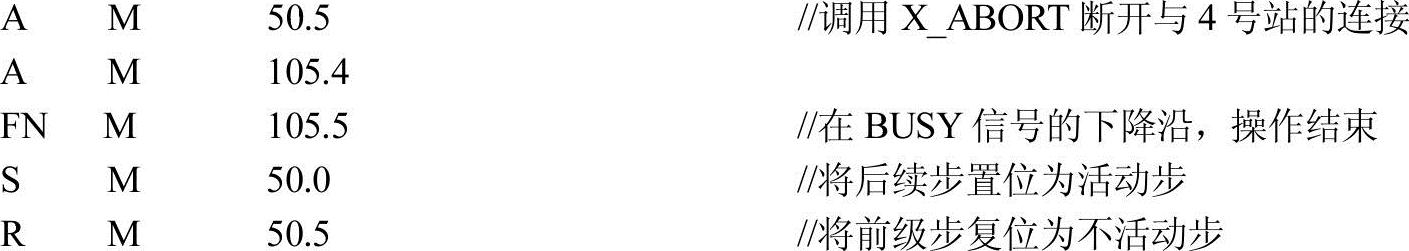
3.2号站的通信程序
为了防止通信块执行的时间间隔过快,在2号站每100ms执行一次的OB35中,用各步对应的存储器位M50.0~M50.5来分别调用对应的通信块。下面是2号站的OB35中的程序:
程序段1:使发送的数据动态变化

程序段2:在第1步调用X_PUT,将数据写入3号站
 (https://www.xing528.com)
(https://www.xing528.com)
程序段3:在第2步调用X_GET,读3号站的数据

程序段4:在第3步调用X_SEND,向3号站发送数据


程序段5:在第4步调用X_ABORT断开与3号站的连接

程序段6:在第5步调用X_SEND,向4号站发送数据

程序段7:在第6步调用X_ABORT断开与4号站的连接

4.3号站和4号站的程序
下面是3号站的OB1接收数据的程序:
程序段1:接收2号站发送的数据


下面是4号站的OB1中接收数据的程序:
程序段1:接收2号站发送的数据

3号站和4号站的OB35每100ms将DB1.DBW0加1,程序如下:
程序段1:使发送的数据动态变化
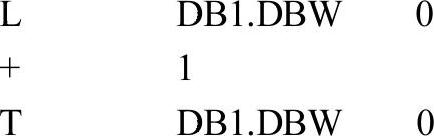
5.通信数据区的初始化
1)2号站的初始化组织块OB100调用SFC 21,将X_PUT的源数据区DB1的各个字预置为W#16#4001,将写入3号站和4号站的DB3和DB4的各个字分别预置为W#16#4003和W#16#4004。将存放用X_GET读取的数据的DB 2的各个字清零。
2)3号站的初始化组织块OB100将CPU 413-2DP用X_GET读取的DB 1中的字预置为W#16#3001,将CPU 413-2DP用X_PUT和X_SEND写入数据的DB2和DB3的各个字清零。
3)4号站的初始化组织块OB100将用于接收CPU 413-2DP用X_SEND发送的数据的DB3的各个字清零。
6.下载与监控
将组态信息和程序分别下载到各CPU,然后用PROFIBUS电缆连接编程用的计算机和3台PLC的MPI接口,将各CPU切换到RUN模式。
在运行时同时打开3个站的变量表(见图14-36~图14-38),用变量表监视各个站接收到的数据的第一个字DBW0和最后一个字DBW74,以及本站的ID0和QD0(或QD4)。
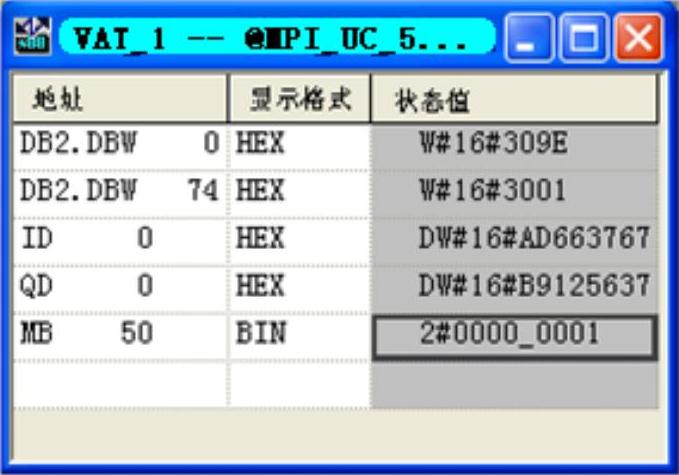
图14-36 CPU 413-2DP的变量表
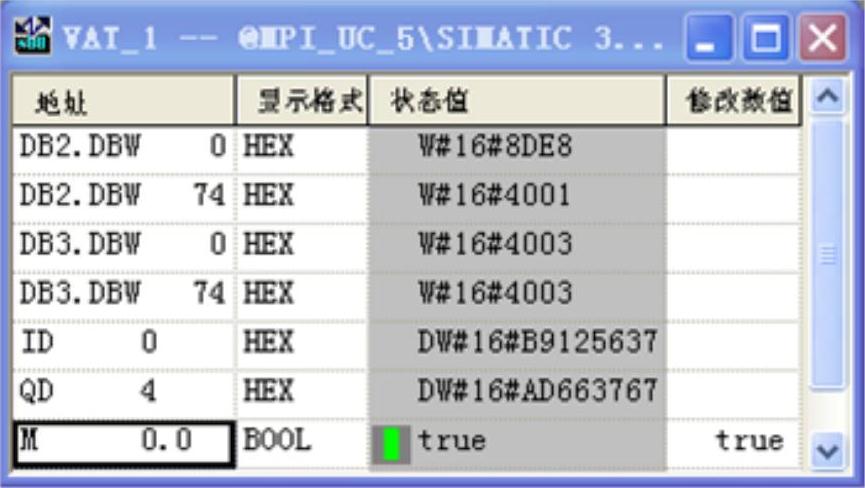
图14-37 3号站的变量表
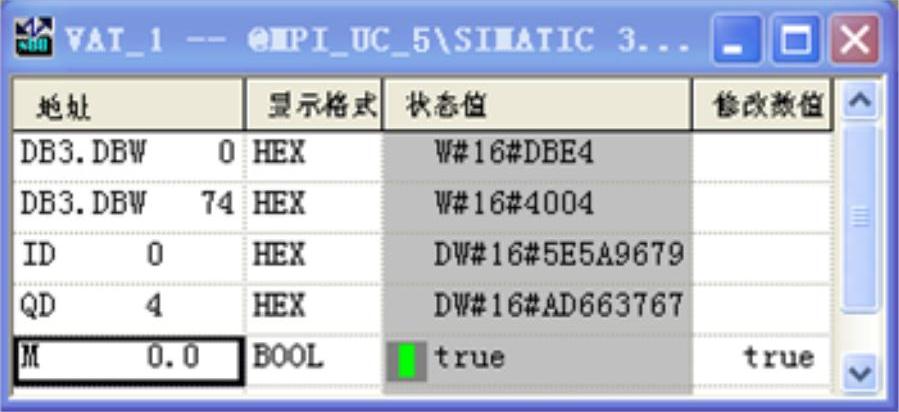
图14-38 4号站的变量表
2号站的DB2用来存放用X_GET读取的3号站的数据。3号站的DB 2存放的是2号站用X_PUT写入的数据。
3号站和4号站的DB3是用X_RCV接收到的2号站用X_SEND发送的数据。3号站和4号站的变量表中的M0.0是X_RCV的接收使能位,用它来控制是否接收数据。
因为用2号站的ID0控制3号站和4号站的QD4,从变量表可以看出,三者的状态完全相同。在控制通信过程的顺序控制程序正常运行时,可以看到2号站的变量表中的MB50的第0~5位(对应于图14-33中的各步)在同一时刻只有一位为一,并且这6位循环左移,依次轮流变为1状态。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。