



近年来,随着计算机和数据库技术的发展,数据挖掘已成为一个逐渐兴起的研究领域。它是一种基于数据库的自动信息提取技术。大型关系数据库中的数据挖掘是数据库研究的一个新课题,作为数据挖掘的一部分,关联规则的挖掘近年来受到许多人的重视。下面将针对在文献[28-29]中使用的一类多输入单输出模糊逻辑系统,采用数据挖掘方法产生模糊规则。这种方法与WM算法及iWM算法相比,产生的规则库具有良好的完备性和鲁棒性,从而提高了模糊模型的精度。
问题描述:假定通过实验或其他手段得到与文献[29]相同的输入和输出数据对集合
(X(p);y(p),p=1,2…,N (2-46)式中 X=(Xl,…,Xn)TRn;
yER。
我们的问题是如何从这些输入输出数据对中提取模糊规则并用该规则库建立模糊模型。下面给出用数据挖掘方法产生模糊规则库的主要步骤。
步骤1-输入和输出变量的模糊区间划分
首先,设前提输入变量甄与结论输出变量y的域值区间分别为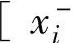 ,
,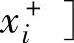 和[y一,y+],i=l,…,n。然后,在每一个变量区间上定义ci个模糊集,用
和[y一,y+],i=l,…,n。然后,在每一个变量区间上定义ci个模糊集,用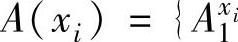 ,…,
,…,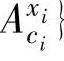 和
和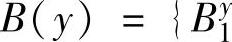 ,…,
,…,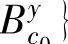 表示对应的模糊集合。最后,给每个模糊集合分配隶属度函数。
表示对应的模糊集合。最后,给每个模糊集合分配隶属度函数。
步骤2.普通记录转化成模糊记录
将步骤1.的输入输出数据对存放到普通型关系数据库表中。简单地说,输入输出数据对在关系数据库中以表的形式被保存,其中行代表一条记录,列代表一条记录的一个属性。如果用L={x1,…,xn。,y}表示属性集合,任一记录(行)tp。表示属性集合L对应的记录值。用下面的TL定义记录集合
TL={t1,…,tN} (2-47)如果用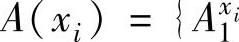 ,…,
,…,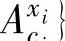 表示前提属性xi。的模糊集合,
表示前提属性xi。的模糊集合,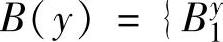 ,…,
,…,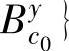 表示结论属性y的模糊集合,可得到集合A={Ui.1.….。4(。)}和B={B(),)}。对于属性F={A U B}.用下面的丁,定义记录在该属性上的集合
表示结论属性y的模糊集合,可得到集合A={Ui.1.….。4(。)}和B={B(),)}。对于属性F={A U B}.用下面的丁,定义记录在该属性上的集合
TF={ /LF( ti),…,/LF(£Ⅳ)} (2-48)通过上面的定义,我们可以将模糊记录保存在另一关系表中。列表示属性F,行表示取值在[0;1]之间的记录。至此完成了普通记录转化为模糊记录的工作。
步骤3.计算模糊规则的支持度
从数据挖掘的角度看,如果一条模糊规则有实际意义,它必须具有足够的支持度。支持度反映了样本记录对该条规则的支持程度,现定义支持度如下
式中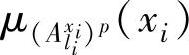 和
和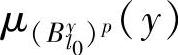 ——别表示记录p的隶属度函数值;
——别表示记录p的隶属度函数值;
N——在TF中的记录总数;
li=1,…,ci。(https://www.xing528.com)
为方便计算,也可采用下面的形式定义支持度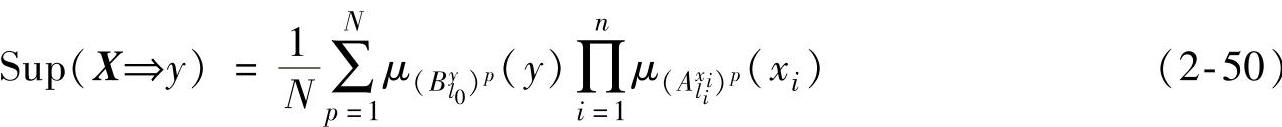 步骤4.创建完备的模糊规则库
步骤4.创建完备的模糊规则库
算法具体描述如下:首先,要保证由前提变量构成的每个模糊子空间都能被遍历;其次,结论变量在模糊子空间选用的最佳模糊集,由规则的最大支持度决定。该算法的实施是比较容易、有规律的,只需多个循环语句就可以完成。
输入.1)样本数据;2)用户指定ci;3)n和N
输出.产生一个具有完备性的模糊规则库
步骤4.1.初始化
定义全局变量j,Max-sup和Max-num
步骤4.2.基于最大支持度获取模糊规则
步骤4.3.遍历X的所有模糊集并计算隶属度值
步骤4.4.遍历y的所有模糊集并计算支持度
Return
步骤5.计算模糊规则的信任度
一个模糊系统就是一个从输入映射到输出If-Then规则的集合,一般规则越多逼近效果越好。但随着输入变量个数和变量的模糊集分割数增多,模糊规则的数目也呈指数增长,那么无疑会产生规则爆炸。上面挖掘方法产生的规则是完备的,当前提变量的个数和变量的模糊集分割数不是过多时,完全可以采用这些完备规则。但当前提变量的个数和变量的模糊集分割数过多时,可以通过下面的规则信任度来约简规则
这种约简所产生的规则库不完备性是在规则库完备性的基础上,为了便于系统实施人为约简那些信任度较低的规则,它与WM算法所产生规则库的不完备性具有本质的不同。
步骤6.增加前提和结论变量的模糊集合数
对于前提和结论变量的模糊集合数的选择,可以采用试探法,给定初始值,然后通过下面的误差值判定是否满足期望的精度要求
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。