



模糊系统已被证明能以任意精度逼近紧集上的任意函数,下面简要回顾用查表法设计模糊系统其主要步骤及需要改进的地方。
步骤1.把输入与输出空间划分为模糊空间。
步骤2.由-个输入-输出数据对产生一条模糊规则。
步骤3.对步骤2中的每条规则赋予一个强度。
步骤4.创建模糊规则库。
步骤5.基于模糊规则库构造模糊逻辑系统。
定义1(完备性):输入变量定义的模糊集所有可能组合的模糊子空间上都有规则分布,称这样的规则库是完备的。
由查表法产生的模糊规则库是不完备的。在步骤1把第i个输入变量xi,划分ki,个模糊集,其中i=l,2,…,n。那么,查表法产生的规则数量受两个数约束:m(输入一输出数据对的数量)和
 (由输入变量定义的模糊集的所有可能组合的数量)。如果m<
(由输入变量定义的模糊集的所有可能组合的数量)。如果m<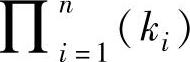 将使规则库产生第一类不完备性,既样本数据过少造成的不完备。此外,如果
将使规则库产生第一类不完备性,既样本数据过少造成的不完备。此外,如果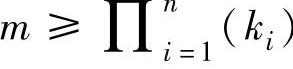 也有可能使规则库产生另一类的不完备性,即某些样本数据分布在同一模糊子空间(对应于同一个格子)从而产生了矛盾规则,由步骤3可知,强度最大的规则被选择。(https://www.xing528.com)
也有可能使规则库产生另一类的不完备性,即某些样本数据分布在同一模糊子空间(对应于同一个格子)从而产生了矛盾规则,由步骤3可知,强度最大的规则被选择。(https://www.xing528.com)
我们考虑有两个输入变量x1,x2,分别被划分成五个和七个模糊集的例子,如图2-3和图2-4所示。假定样本集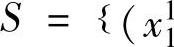 ,
,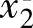 ;y1),…,
;y1),…,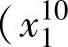 ,
, ;ylo))中包括10对理想输入一输出数据对,从图2-3中可以看,
;ylo))中包括10对理想输入一输出数据对,从图2-3中可以看,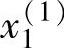 在Bl模糊集上的隶属度值最大,
在Bl模糊集上的隶属度值最大,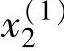 在Sl模糊集上的隶属度值最大,y(1)在CE模糊集上的隶属度值最大。南查表法可以得到下面的IF - THEN模糊规则
在Sl模糊集上的隶属度值最大,y(1)在CE模糊集上的隶属度值最大。南查表法可以得到下面的IF - THEN模糊规则
Rl:If x1is Bl and X2 iS Sl Theny is CE (2-37)也就是在图2-4模糊规则库的模糊子空间填上CE。以此类推,其他数据对产生的规则也相应填充到各自的模糊子空问。但是,规则库的模糊子空间最多有10个被填充,其他模糊子空间为空,所以,对小样本集来说使用查表法产生的规则库是不完备的。当然,对大样本集来说,如果数据对不是均匀分布在由输入变量定义的模糊集所有可能组合的模糊子空间上,也会产生规则库的不完备性。
定义2(鲁棒性):当样本集中混入少量坏的数据对干扰时,由该样本集生成的规则库所确定的模糊模型仍能保证良好的性能,称这样的规则库是鲁棒的。
由查表法产生的模糊规则库不具有良好的鲁棒性。在实际中所得到的样本数据常常混有坏的数据对,如果坏的数据对产生的规则强度大于好的数据对产生的规则强度,那么在规则库中将包含坏规则,从而影响模糊模型的性能。
对于图2-3中的例子来说,假定在原有十对理想输入-输出数据对中增加一个坏的数据对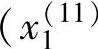 ,
,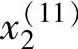 ,y(11)),并假定
,y(11)),并假定 =
=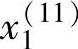 ,
,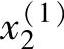 =
=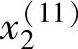 ,y(1)≠y(11),由于y(11)(虚线)在B1模糊集上的隶属度值最大,由后增加的数据对产生下面的IF-THEN模糊规则
,y(1)≠y(11),由于y(11)(虚线)在B1模糊集上的隶属度值最大,由后增加的数据对产生下面的IF-THEN模糊规则
R2:If x1 is B1 and x2 is S1 Then y is B1 (2-38)在相同输入点的情况下,由于y(1)和y(11)的不同从而导致了两条矛盾规则。按照查表法的步骤3强度定义,后一条规则被采纳,从而导致了坏数据产生坏规则的现象。所以说,仅由一个数据对就产生一条模糊规则是不可靠的,产生这种现象的原因在于产生规则的支持度不够。
查表法也考虑了样本数据中可能有不可靠数据问题,该文解决的办法是给每对数据一个可靠度,但是该方法很难实施。首先,人为地判断数据的好坏是很难的;其次,如果样本集过大,对每个样本数据都人为地进行判断也是不现实的。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。