



基于现代非线性处理技术的建模是利用易测过程信息(辅助变量,它通常是一种随机信号),采用先进的信息处理技术,通过对所获信息的分析处理提取信号特征量,从而实现某一参数的在线检测或过程的状态识别。
这种建模技术的基本思想与基于相关分析的建模技术一致,都是通过信号处理来解决建模问题,所不同的是具体信息处理方法不同。该种建模技术的信息处理方法大多是各种先进的非线性信息处理技术,例如小波分析、混沌和分形技术等,因此能适用于常规的信号处理手段难以适应的复杂工业系统。相对而言,基于现代非线性信息处理技术的建模的发展较晚,研究也还比较分散。该种建模技术目前一般主要应用于系统的故障诊断、状态检测和过失误差侦破等,并常常和人工神经网络或模糊数学等人工智能技术相结合。
在建模过程中,通常需要从实际生产过程中采集建模样本数据。一般来说用于建模的数据分为训练用数据(学习样本)和测试用数据(测试样本),建模过程是指用训练数据不断训练模型结构和参数,使之能更好地拟合训练数据的过程。在建模完成后,用训练数据测试所建的模型的过程称为回想(recall),其误差称为拟合误差;测试样本不参与学习,只用于模型的测试,用测试样本检验模型的过程称为泛化(generalization),其误差称为泛化误差。为判断建模效果的优劣,我们引入计算校验数据集的泛化均方根误差(RMSE)和最大泛化绝对误差(MAXE)。即
式中ρi——组分含量的化验室测量值;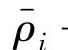 ——组分含量的建模估计值;(https://www.xing528.com)
——组分含量的建模估计值;(https://www.xing528.com)
N——校验数据的个数。
针对具体工业生产过程,根据工艺要求给定建模的泛化均方根误差(RMSE)和最大泛化绝对误差(MAXE)指标。如建立的模型校验指标小于给定指标要求,表明所建立的模型具有较高精度和较强的泛化能力。
上述方法是在建模领域中的主流方法,当然也可采用几种方法互相结合进行建模。上述方法涉及众多领域,无法详细展开,下面主要就模糊建模进行论述。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。