



1.SQL Server标识符说明
一个SQL标识符是指由程序员定义的SQL Server可识别的有意义的字符串。通常用它们来表示服务器名、数据库名、表名、各类数据库对象名、常量、变量和存储过程名等。
在SQL Server中,标识符的命名必须遵守以下规则:
1)标识符的长度范围为1~30个字符。
2)标识符的第一个字符必须为字母、下画线“_”、字符@及#。其中以@为首的标识符表示一个局部变量,以#字符为首的标识符表示一个临时数据库对象。对于表或存储过程,名称前包含一个“#”时表示局部临时对象,而“##”字符则表示为全局临时对象。
3)标识符中第一个字符后面可以是字母、数字、#、$和下画线“_”。
4)默认情况下,标识符内不允许含有空格,也不允许将SQL关键字作为用户自定义的标识符,但可以使用引号来定义特殊标识符。
5)在SQL Server中文版中,汉字也可以作为标识符。
2.SQL运算符
运算符是用来进行列间或者变量之间比较和数学运算的。在SQL Server 2005中,运算符有算术运算符、字符串运算符、关系运算符和逻辑运算符等。
(1)算术运算符
算术运算符可以用在各种列和变量上,列和变量的数据类型可以是int、smallint、tiny-int、float、real、money和smallmoney。算术运算符包括加(+)、减(-)、乘(*)、除(/)和取模(%)。算术运算符见表2-5。
表2-5 算术运算符

(2)字符串运算符
字符串运算符用来实现对字符串的操作,字符串由字母、符号和数字组成。字符串运算符可以操作的有char、varchar和text,以及可以转化成char和varchar的数据类型。
例如,使用下面的字符串运算符实现两个字符串的连接。
(3)关系运算符
关系运算符用来比较两个表达式。在SQL Server 2005中,关系运算符有等于(=)、大于(>)、小于(<)、大于或等于(>=)、小于或等于(<=)、不等于(<>、!=)、不大于(!>)、不小于(!<)、优先级控制符()等。
(4)逻辑运算符
使用逻辑运算符可以把多个条件合并起来。逻辑运算符包括AND、OR和NOT等。在Trans-act-SQL语句中对整数数据进行比较的时候,首先将它们转化成二进制数,然后再进行比较。
AND运算符只有当所有条件都为真的时候才返回真,只要有一个条件为假,便返回假;OR运算符只要有一个条件为真,便返回真;NOT运算符为取反。3个运算符的优先级为:NOT、AND、OR。
(5)运算符优先级
在同一个表达式中,可能会包含多种运算符,这就涉及运算符的优先级问题。运算符的优先级决定了表达式的计算和比较顺序。在SQL Server 2005中,运算符的优先级从高到低如下所示。
●括号:()。
●取反运算符:~。
●乘法、除法、求模运算符:*、/、%。
●加减运算符:+、-。
●“异或”运算符:^。
●“与”运算符:&。
●“或”运算符:|。
●NOT连接。
●AND连接。
●OR连接。
如果优先级相同,则按照从左到右的顺序进行运算。
3.SQL变量
变量是指在程序运行过程中,其值可以发生变化的量,通常用来保存程序运行过程中的输入数据、计算获得的中间结果和最终结果。
●变量的取名规则同标识符,SQL Server对英文字母不区分大小写。
●给变量取名时,为了便于阅读和理解程序,一般都用代表变量值或用途的标识符。
●当程序运行时,每个变量都要占用连续的若干个字节,所占用的字节数由变量的数据类型确定。
●SQL Server语句规定,变量可以是任何一种数据类型。通常把具有某种数据类型的变量叫做该类型变量。
●每个变量在使用前都必须定义,定义的内容之一就是说明其数据类型。
在SQL Server中,变量可分为全局变量和局部变量。
(1)局部变量
在Transact-SQL程序中,局部变量一般出现在批处理、存储过程和触发器中。和其他高级语言一样,要使用局部变量,必须在使用前用DECLARE语句定义。
局部变量仅生存于声明它的批处理、存储过程或触发器中,处理结束后,存储在局部变量中的信息将自动消失。
一般情况下,SQL Server使用SELECT语句或者PRINT语句将变量的值提交给用户。而存储过程则可以返回变量的值。
1)局部变量的定义。
在SQL Server中,局部变量是通过DECLARE语句来定义的,其语法格式如下:
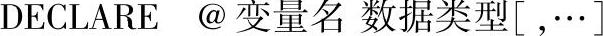
2)局部变量的赋值。
在SQL Server中,用SELECT语句为变量赋值,它的语法与指定字段的语法相似。赋值格式如下:

说明:
●一般情况下,使用SELECT语句为变量赋值时,不需要含有FROM子句。
●在局部变量没有被赋值前,它的值是NULL,如果要在程序中使用它,特别是在循环结构中,必须先为其赋值。
(2)全局变量
在SQL Server中,全局变量通常被SQL服务器用来跟踪服务器范围和特定会话期间的信息,不能显式地被赋值或声明。
●全局变量不能由程序员定义。
●全局变量提供了用户当前的会话信息。
●全局变量是不可赋值的,并且在所有的程序中都可以直接使用。
●在某个时刻,各用户的值是互不相同的。
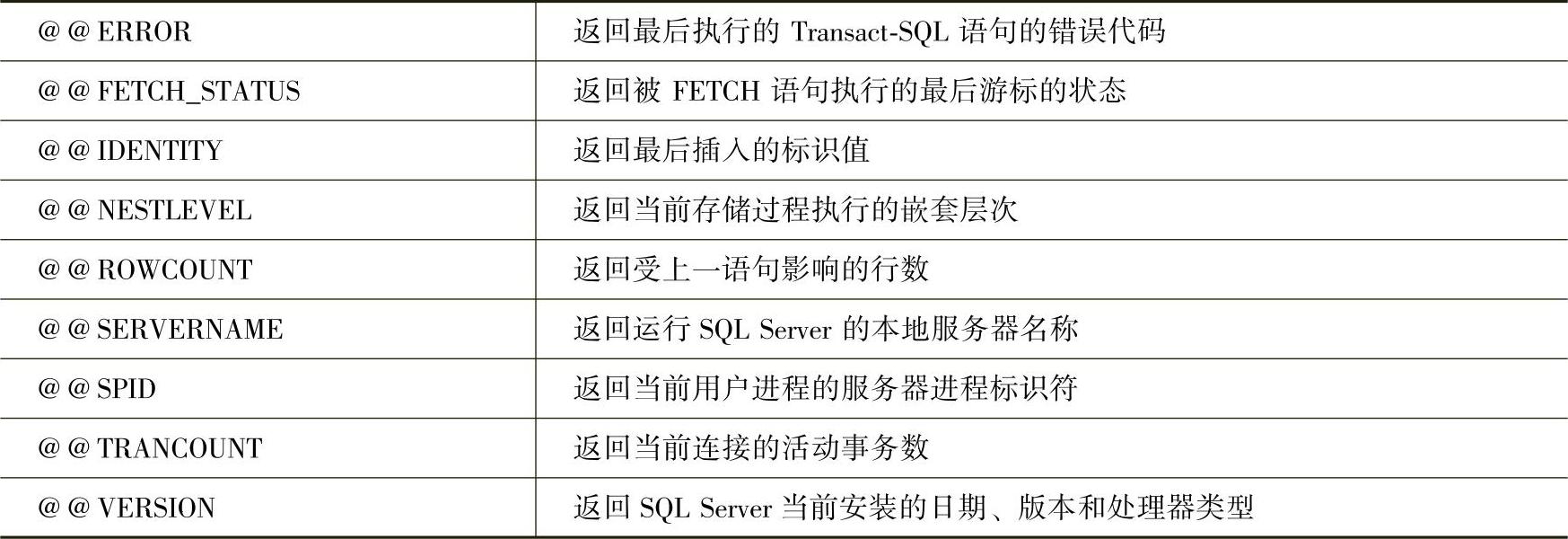
表2-6列出了部分常用的全局变量。
表2-6 SQL Server部分常用的全局变量
4.SQL语句块
使用BEGIN…END语句可以将多条SQL语句封装起来,形成一个语句块,使这些语句作为一个整体执行。
BEGIN…END语句的语法形式如下:

说明:
BEGIN…END用来设定一个程序块,在BEGIN…END内的所有程序将被视为一个单元执行。需要说明两点:
●尽管BEGIN…END几乎可以用在程序中的任何地方,但它最常见的用法是和WHILE或IF…ELSE组合使用。
●在BEGIN…END中可嵌套另外的BEGIN…END来定义另一个程序块。块语句一般不单独使用,而是和判断语句、循环语句配合使用。
5.SQL判断语句
通常,计算机按照顺序依次执行程序中的语句。然而,在许多情况下,语句执行的顺序以及是否被执行都依赖于程序运行的中间结果。在这种情况下,必须根据某个变量或表达式的值来作出判断,以决定执行哪些语句或跳过哪些语句不执行。用户可以利用IF…ELSE语句(条件判断语句)或者CASE语句作出判断。根据表达式的真假,选择执行某个语句或者语句块。
IF…ELSE语句的语法形式如下:

说明:
●在执行过程中,如果条件表达式为真,则执行IF后面的语句或语句块,如果条件为假,则执行ELSE后面的语句或语句块。
●IF和ELSE后面的语句或语句块必须是单一SQL语句或语句块,不能包含多个SQL语句。
例2-58 从SC数据表中求出学号为S1的同学的平均成绩,如果此平均成绩大于或等于60分,则输出“pass”信息。

CASE语句是一种多路分支判断,通常具有两种格式:
●简单CASE函数将某个表达式与一组简单表达式进行比较以确定结果。
●CASE搜索函数计算一组布尔表达式以确定结果。
两种格式都支持可选的ELSE参数。
格式1:

该语句的执行过程是:将CASE后面表达式的值与各WHEN子句中的表达式的值进行比较,如果二者相等,则返回THEN后的表达式的值,然后跳出CASE语句,否则返回ELSE子句中的表达式的值。ELSE子句是可选项。当CASE语句中不包含ELSE子句时,并且如果所有比较都失败时,CASE语句将返回NULL。
例2-59 从学生表S中,选取SNO、SEX,如果SEX为“男”,输出“M”,如果为“女”,则输出“F”。

格式2:

该语句的执行过程是:首先测试WHEN后的表达式的值,如果其值为真,则返回THEN后面的表达式的值,否则测试下一个WHEN子句中的表达式的值,如果所有WHEN子句后的表达式的值都为假,则返回ELSE后的表达式的值,如果在CASE语句中没有ELSE子句,则CASE表达式返回NULL。
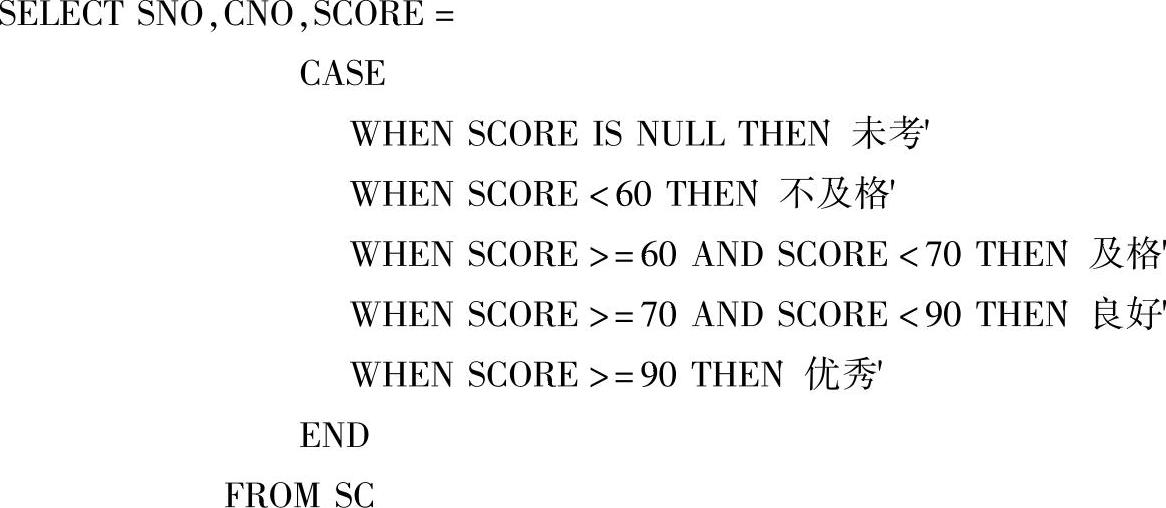
例2-60 从SC表中查询所有同学选课成绩情况,凡成绩为空者输出“未考”、小于60分输出“不及格”、60~70分输出“及格”、70~90分输出“良好”、大于或等于90分时输出“优秀”。
6.SQL循环语句
使用WHILE语句设置一个反复执行的语句块,直到条件不满足为止。
WHILE语句的语法形式如下:


说明:
●WHILE语句在条件表达式成立时,重复执行<SQL命令行或程序块>,直到条件表达式不成立时,结束执行循环。
●在WHILE语句中,还可以使用BREAK和CONTINUE使程序从循环中跳出。BREAK语句从循环中跳出之后,接着执行END后面的第一条语句。CONTINUE语句使程序跳过CONTINUE语句后面的语句,重新判断逻辑条件,如果满足条件,则重新执行循环体内SQL语句。
●WHILE语句可以嵌套使用。
例2-61 用SQL编写程序计算1+2+3+…+100,如果和大于4000则跳出循环结构,将结果输出。

7.关于错误处理
一般情况下,SQL Server可以自动为用户处理绝大多数程序所出现的错误,然后向用户发送一条消息,用以告诉用户程序所出现的问题。但是,在实际工作中,用户通常需要自己在存储过程和复杂的批处理中,返回并识别引用过程或批处理中产生的出错条件,此时,就可以使用RAISERROR语句来使用户自己处理这些错误。特别是用户在触发器中遇到错误并且必须调用ROLLBACK语句时,这一点就显得尤为重要。
(1)关于SQL Server的错误信息
在SQL Server中,错误信息包括以下4项内容。
●错误号:一个特殊的整数值,每种错误都有唯一的错误号。
●错误严重性:用以描述错误的基本类型。
●状态:用以描述错误的“调用状态”,它是1~127之间的整数值。
●消息:报告给用户的关于错误信息的文本,它不超过255个字符。
服务器和应用程序将利用错误消息或部分错误信息,通知用户或管理员,以便得出合理的处理策略。
(2)管理SQL Server错误信息
SQL Server提供了很多与预定义的事件相关的内在的错误消息,而这些事件包含在分析、优化以及执行子系统中。
错误信息存储在系统表sysmessages中,用户可以在sysmessages表中加入自定义的消息,并可利用RAISEEROR语句访问这些消息。
当出现错误时,用户可以发送一条错误消息和一个直接由SQL程序产生的数字,或者引用自己预定义的消息。
SQL Server提供了3个存储过程来帮助用户管理自己的错误消息,用户可以使用这些存储过程来开发脚本程序向多个服务器发布错误表。
●向系统错误表中添加消息时,可使用sp_addmessage存储过程。
●存储过程sp_altermessage将改变消息的登录行为。
●存储过程sp_dropmessage将从表中删除一条错误消息。
(3)RAISERROR语句
RAISERROR语句返回用户自定义的错误信息并设置系统标志,记录发生的错误。
通过RAISERROR语句,客户端可以从sysmessages表中检索条目,或者使用用户指定的严重度和状态信息动态地生成一条消息。这条消息在定义后就作为服务器错误信息返回给客户端。RAISERROR语法格式如下:
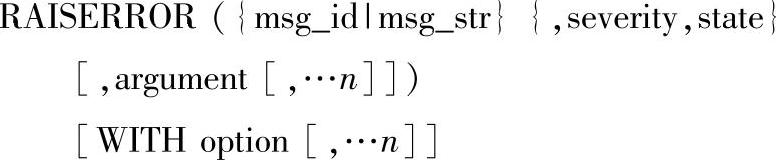
说明如下。
●msg_id:存储于sysmessages表中的用户自定义的错误信息。用户自定义错误信息的错误号应大于50000。由特殊消息产生的错误是第50000号。
●msg_str:是一条特殊消息,其格式与C语言中使用的PRINTF格式样式相似。此错误信息最多可包含400个字符。如果该信息包含的字符超过400个,则只能显示前397个并将添加一个省略号以表示该信息已被截断。所有特定消息的标准消息号是14000。
●severity:用户自定义的与消息关联的严重级别。用户可以使用0~18之间的级别。19~25之间的级别只能由sysadmin固定服务器角色成员使用。若要使用19~25之间的级别,必须选择WITH LOG选项。
●state:1~127的任意整数,表示有关错误调用状态的信息。state的默认值为1。
●argument:是用于取代在msg_str中定义的变量或取代对应于msg_id的消息的参数。可以有零或更多个替代参数;然而,替代参数的总数不能超过20个。每个替代参数可以是局部变量,其数据类型为int1、int2、int4、char、varchar、binary或varbinary,不支持其他数据类型。
例2-62 添加一条错误消息,编号为50007,严重级别为6,出错提示信息为xxxxxx,显示语言为英语,然后在屏幕显示该错误信息。
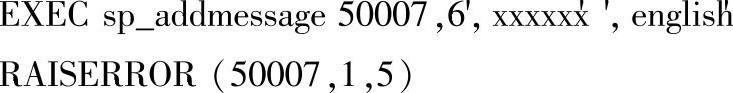
读一读
1.Transact-SQL的特点
SQL与第3代语言(如C语言、Pascal语言等)相比,更加简练、易读、易维护和易扩充。与第3代语言相比,SQL具有如下特点。
●SQL的语句更能代表一个有意义的工作过程,一个语句可以实现一个完整的功能。
●SQL的语句对数据操作时不必知道数据的物理位置,服务器会自动将逻辑名转换成与数据相关的物理位置。
●SQL的语句不必再设计查找或索引的优化策略,SQL服务器已经为查找数据提供了最有效的方法。
●ANSI SQL主要是作为查询语言出现的,它不是一个全能的编程语言。Transact-SQL为了扩展SQL,增加了以下功能:
①加入了程序控制结构(如IF、WHILE语句等)。
②加入了局部变量、全局变量等一些功能。
2.SQL语句的构成
按照SQL语法约定:任何一条Transact-SQL语句至少需要包含一个命令,即一个表明动作含义的动词。例如,SELECT动词请求SQL服务器检索出若干记录行,UPDATE动词要求SQL服务器修改特定记录中的字段值。
1)SQL中的命令动词是一种对SQL服务器有特定意义的关键字,而其他关键字则只是在SQL语句中引入了其他的限制条件。
例如,对于SELECT…FROM…WHERE语句:
●SELECT命令请求SQL服务器检索出若干记录行。
●FROM关键字用来告诉SQL服务器本次检索所用到的表的名字。
●WHERE关键字告诉SQL服务器,在FROM所指定的表中,对哪些记录进行操作,即条件限制。
2)用户或者应用程序向服务器提交Transact-SQL语句均采用批处理的形式。
●一个批处理是指一次发送给服务器一组语句。
●每个SQL Server应用程序都设有一种机制,用来告诉服务器执行一个批处理中的所有语句。
3.SQL语句的语法格式
1)CREATE DATABASE语句的语法格式如下:
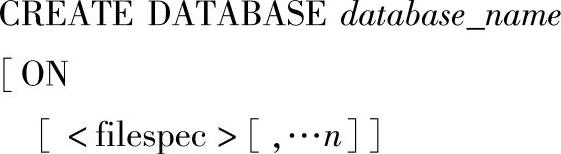

其中的参数含义如下。
●database_name:新数据库的名称。数据库名称在服务器中必须唯一,并且符合标识符的规则。
●ON:指定显式定义用来存储数据库数据部分的磁盘文件(数据文件)。
●n:占位符,表示可以为新数据库指定多个文件。
●LOG ON:指定显式定义用来存储数据库日志的磁盘文件(日志文件)。
●collation_name:指定数据库的默认排序规则。
●PRIMARY:指定关联的<filespec>列表定义主文件。主文件组包含所有数据库系统表,还包含所有未指派给用户文件组的对象。
●NAME:为由<filespec>定义的文件指定逻辑名称。
●logical_file_name:用来在创建数据库后执行的Transact-SQL语句中引用文件的名称。
●FILENAME:为<filespec>定义的文件指定操作系统文件名。
●′os_file_name′:操作系统创建<filespec>定义的物理文件时使用的路径名和文件名。
●SIZE:指定<filespec>中定义的文件的大小。
●size:<filespec>中定义的文件的初始大小。
●MAXSIZE:指定<filespec>中定义的文件大小可以增长到的最大值。
●max_size:<filespec>中定义的文件大小可以增长到的最大值。
●UNLIMITED:指定<filespec>中定义的文件大小将增长到磁盘变满为止。
●FILEGROWTH:指定<filespec>中定义的文件大小的增长量。
●growth_increment:每次需要新的空间时为文件添加的空间大小。
2)创建CREATE TABLE语句的语法格式如下:



其中的参数说明如下。
●database_name:是要在其中创建表的数据库名称。
●Owner:新表所有者的用户ID。
●table_name:新表的名称。表名必须符合标识符规则。数据库中的owner.table_name组合必须唯一。
●column_name:表中的列名。列名必须符合标识符规则,并且在表内唯一。
●computed_column_expression:定义计算列值的表达式。
●ON{filegroup|DEFAULT}:指定存储表的文件组。
●TEXTIMAGE_ON:表示text、ntext和image列存储在指定文件组中的关键字。
●data_type:指定列的数据类型。
●DEFAULT:如果在插入过程中未显式提供值,则指定为列提供的值。
●constant_expression:用作列的默认值的常量、NULL或系统函数。
●IDENTITY:表示新列是标识列。
●seed:装入表的第一行所使用的值。
●increment:添加到前一行的标识值的增量值。
●NOT FOR REPLICATION:表示当复制向表中插入数据时,不强制IDENTITY属性。
●ROWGUIDCOL:表示新列是行的全局唯一标识符列。
●collation_name:指定列的排序规则。
●CONSTRAINT:是可选关键字,表示PRIMARY KEY、NOT NULL、UNIQUE、FOR-EIGN KEY或CHECK约束定义的开始。
●constrain_name:约束的名称。约束名在数据库内必须是唯一的。
●NULL|NOT NULL:确定列中是否允许空值的关键字。
●PRIMARY KEY:通过唯一索引对给定的一列或多列强制实体完整性的约束。对于每个表只能创建一个PRIMARY KEY约束。
●UNIQUE:通过唯一索引为给定的一列或多列提供实体完整性的约束。一个表可以有多个UNIQUE约束。
●CLUSTERED|NONCLUSTERED:表示为PRIMARY KEY或UNIQUE约束创建聚集或非聚集索引的关键字。
●[WITH FILLFACTOR=fillfactor]:指定SQL Server存储索引数据时每个索引页的充满程度。
●FOREIGN KEY…REFERENCES:为列中的数据提供引用完整性的约束。
●ref_table:FOREIGN KEY约束所引用的表名。
●(ref_column[,…n]):FOREIGN KEY约束所引用的表中的一列或多列。(https://www.xing528.com)
●ON DELETE{CASCADE|NO ACTION}:指定当要创建的表中的行具有引用关系,并且指定从父表中删除该行所引用的行时,要对该行采取的操作。
●ON UPDATE{CASCADE|NO ACTION}:指定当要创建的表中的行具有引用关系,并且指定在父表中更新该行所引用的行时,要对该行采取的操作。
●CHECK:通过限制可输入到一列或多列中的可能值强制域完整性的约束。
●NOT FOR REPLICATION:用于防止在复制所使用的分发过程中强制CHECK约束的关键字。
●logical_expression:返回TRUE或FALSE的逻辑表达式。
●column:是用括号括起来的一列或多列,在表约束中表示这些列用在约束定义中。
●[ASC|DESC]:指定加入到表约束中的一列或多列的排序次序。默认设置为ASC。
●n:表示前面的项可重复n次的占位符。
3)创建索引CREATE INDEX语句的语法格式如下:

其中的参数说明如下。
●UNIQUE:为表或视图创建唯一索引。
●CLUSTERED:创建一个对象,其中行的物理排序与索引排序相同,并且聚集索引的最低一级包含实际的数据行。
●NONCLUSTERED:创建一个指定表的逻辑排序的对象。
●index_name:索引名。索引名在表或视图中必须唯一,索引名必须遵循标识符规则。
●table:包含要创建索引的列的表。
●view:要建立索引的视图的名称。
●column:应用索引的列。
●[ASC|DESC]:确定具体某个索引列的升序或降序排序方向。
●n:表示可以为特定索引指定多个column的占位符。
●PAD_INDEX:指定索引中间级中每个页(节点)上保持开放的空间。
●FILLFACTOR=fillfactor:指定在SQL Server创建索引的过程中,各索引页的填满程度。
●IGNORE_DUP_KEY:控制当尝试向属于唯一聚集索引的列插入重复的键值时所发生的情况。
●DROP_EXISTING:指定应除去并重建已命名的先前存在的聚集索引或非聚集索引。
●STATISTICS_NORECOMPUTE:指定过期的索引统计不会自动重新计算。
●SORT_IN_TEMPDB:指定用于生成索引的中间排序结果将存储在tempdb数据库中。
●ONfilegroup:在给定的filegroup上创建指定的索引。
4)创建视图CREATE VIEW语句的语法格式如下:

其中的参数说明如下。
●view_name:视图的名称,视图名称必须符合标识符规则。
●column:视图中的列名。
●n:表示可以指定多列的占位符。
●AS:视图要执行的操作。
●select_statement:定义视图的SELECT语句。
●WITH CHECK OPTION:强制视图上执行的所有数据修改语句都必须符合由select_statement设置的准则。
●ENCRYPTION:表示SQL Server加密包含CREATE VIEW语句文本的系统表列。
●SCHEMABINDING:将视图绑定到架构上。
●VIEW_METADATA:指定为引用视图的查询请求浏览模式的元数据时,SQL Server将向DBLIB、ODBC和OLE DB API返回有关视图的元数据信息,而不是返回基表或表。
5)修改数据库ALTER DATABASE语句的语法格式如下:

其中的参数说明如下。
●database:要更改的数据库的名称。
●ADD FILE:指定要添加的文件。
●TO FILEGROUP:将指定文件添加到的文件组。
●filegroup_name:文件组名称。
●ADD LOG FILE:指定将日志文件添加到指定的数据库中。
●REMOVE FILE:从数据库系统表中删除文件描述并删除物理文件。
●ADD FILEGROUP:指定要添加的文件组。
●REMOVE FILEGROUP:从数据库中删除文件组并删除该文件组中的所有文件。
●MODIFY FILE:指定要更改给定的文件。
●MODIFY NAME=new_dbname:重命名数据库。
●MODIFY FILEGROUP filegroup_name{filegroup_property|NAME=new_filegroup_name}:指定要修改的文件组和所需的改动。
●WITH<termination>:指定当数据库从一种状态转换到另一种状态时,何时回滚未完成的事务。
●COLLATE<collation_name>:指定数据库的排序规则。
●<filespec>:控制文件属性。
6)修改表ALTER TABLE语句的语法格式如下:


其中的参数说明如下。
●table:要更改的表的名称。
●ALTER COLUMN:指定要更改的给定列。
●column_name:要更改、添加或除去的列的名称。
●new_data_type:要更改的列的新数据类型。
●precision:指定数据类型的精度。
●scale:指定数据类型的小数位数。
●COLLATE<collation_name>:为更改列指定新的排序规则。
●NULL|NOT NULL:指定该列是否可接受空值。
●[{ADD|DROP}ROWGUIDCOL]:指定在指定列上添加或除去ROWGUIDCOL属性。
●ADD:指定要添加一个或多个列定义、计算列定义或者表约束。
●computed_column_expression:是一个定义计算列的值的表达式。
●n:表示前面的项可重复n次的占位符。
●WITH CHECK|WITH NOCHECK:指定表中的数据是否用新添加的或重新启用的FOREIGN KEY或CHECK约束进行验证。
●DROP{[CONSTRAINT]constraint_name|COLUMN column_name}:指定从表中删除constraint_name或者column_name。
●{CHECK|NOCHECK}CONSTRAINT:指定启用或禁用constraint_name。
●ALL:指定所有对象。
●{ENABLE|DISABLE}TRIGGER:指定启用或禁用trigger_name。
●trigger_name:指定要启用或禁用的触发器名称。
●column_namedata_type:新列的数据类型。
●DEFAULT:指定列默认值的关键字。
●IDENTITY:指定新列是标识列。
●seed:用于表中所装载的第一行的值。
●increment:添加到前一行的标识值的增量值。
●NOT FOR REPLICATION:指定当复制向表中插入数据时,不强制IDENTITY属性。
●CONSTRAINT:指定PRIMARY KEY、UNIQUE、FOREIGN KEY或CHECK约束的开始,或者指定DEFAULT定义的开始。
●constrain_name:新约束。约束的名称必须符合标识符规则。
●PRIMARY KEY:通过唯一索引对给定的一列或多列强制实体完整性的约束。
●UNIQUE:通过唯一索引为给定的一列或多列提供实体完整性的约束。
●CLUSTERED|NONCLUSTERED:指定为PRIMARY KEY或UNIQUE约束创建聚集或非聚集索引。
●WITH FILLFACTOR=fillfactor:指定SQL Server存储索引数据时每个索引页的充满程度。
●ON{filegroup|DEFAULT}:指定为约束创建的索引的存储位置。
●FOREIGN KEY…REFERENCES:为列中数据提供引用完整性的约束。
●ref_table:FOREIGN KEY约束所引用的表。
●ref_column:新FOREIGN KEY约束所引用的一列或多列(置于括号中)。
●ON DELETE{CASCADE|NO ACTION}:指定当表中被更改的行具有引用关系,并且该行所引用的行从父表中删除时,要对被更改行采取的操作。
●ON UPDATE{CASCADE|NO ACTION}:指定当表中被更改的行具有引用关系,并且该行所引用的行在父表中更新时,要对被更改行采取的操作。
●WITH VALUES:指定在添加到现有行的新列中存储DEFAULT constant_expression中所给定的值。
●column[,…n]:是新约束所用的一列或多列。
●constant_expression:用作列的默认值的字面值、NULL或者系统函数。
●FOR column:指定与表级DEFAULT定义相关联的列。
●CHECK:通过限制可输入到一列或多列中的可能值强制域完整性的约束。
●logical_expression:用于CHECK约束的返回TRUE或FALSE的逻辑表达式。
7)修改视图ALTER VIEW语句的语法格式如下:

其中的参数说明如下。
●view_name:要更改的视图。
●column:一列或多列的名称,用逗号分开,将成为给定视图的一部分。
●n:表示column可重复n次的占位符。
●ENCRYPTION:加密syscomments表中包含ALTER VIEW语句文本的条目。
●SCHEMABINDING:将视图绑定到架构上。
●VIEW_METADATA:在为引用视图的查询请求浏览模式元数据时,指定SQL Server将向DBLIB、ODBC和OLE DB API返回有关视图的元数据信息,而不是返回基表或表。
●AS:视图要执行的操作。
●select_statement:定义视图的SELECT语句。
●WITH CHECK OPTION:强制视图上执行的所有数据修改语句都必须符合由定义视图的select_statement设置的准则。
8)删除数据库DROP DATABASE语句的语法格式如下:
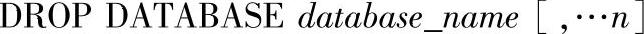
其中的参数说明如下。
●database_name:指定要删除的数据库名称。从master数据库中执行sp_helpdb以查看数据库列表。
9)删除表DROP TABLE语句的语法格式如下:
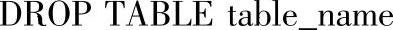
其中的参数说明如下。
●table_name:要删除的表的表名。
10)删除索引DROP INDEX语句的语法格式如下:
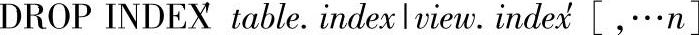
其中的参数说明如下。
●table|view:索引列所在的表或索引视图。若要查看在表或视图上存在的索引列表,可使用sp_helpindex并指定表名或视图名称。表名和视图名称必须符合标识符规则。
●Index:要除去的索引的名称。索引名必须符合标识符的规则。
●n:表示可以指定多个索引的占位符。
11)删除视图DROP VIEW语句的语法格式如下:
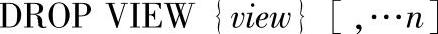
其中的参数说明如下。
●view:要删除的视图名称。视图名称必须符合标识符规则。
●n:表示可以指定多个视图的占位符。
12)INSERT语句的语法格式如下:

其中的参数说明如下。
●[INTO]:一个可选的关键字,可以将它用在INSERT和目标表之间。
●table_name:将要接收数据的表或table变量的名称。
●WITH(<table_hint_limited>[,…n]):指定目标表所允许的一个或多个表提示。
●view_name:视图的名称及可选的别名。
●rowset_function_limited:OPENQUERY或OPENROWSET函数。
●(column_list):要在其中插入数据的一列或多列的列表。
●VALUES:引入要插入的数据值的列表。
●DEFAULT:强制SQL Server装载为列定义的默认值。
●expression:一个常量、变量或表达式。
●derived_table:任何有效的SELECT语句,它返回将装载到表中的数据行。
●execute_statement:任何有效的EXECUTE语句,它使用SELECT或READTEXT语句返回数据。
●DEFAULT VALUES:强制新行包含为每个列所定义的默认值。
13)DELETE语句的语法格式如下:

其中的参数说明如下。
●FROM:可选的关键字,可用在DELETE关键字与目标table_name、view_name或rowset_function_limited之间。
●table_name:是要从其中删除行的表的名称。
●WITH(<table_hint_limited>[,…n]):指定目标表所允许的一个或多个表提示。
●view_name:视图名称。
●rowset_function_limited:OPENQUERY或OPENROWSET函数,视提供程序功能而定。
●FROM<table_source>:指定附加的FROM子句。
●WHERE:指定用于限制删除行数的条件。
●<search_condition>:指定删除行的限定条件。
●CURRENT OF:指定在指定游标的当前位置完成DELETE命令。
●GLOBAL:指定cursor_name是全局游标。
●cursor_name:是从其中进行提取的打开游标的名称。
●cursor_variable_name:游标变量的名称。
●OPTION(<query_hint>[,…n]):表示使用优化程序提示自定义SQL Server的语句处理的关键字。
14)数据的更新UPDATE语句的基本语法格式如下:

其中的参数含义如下。
●table_name:需要更新的表的名称。
●WITH(<table_hint_limited>[,…n]):指定目标表所允许的一个或多个表提示。
●view_name:要更新的视图的名称。
●rowset_function_limited:OPENQUERY或OPENROWSET函数,视提供程序功能而定。
●SET:指定要更新的列或变量名称的列表。
●column_name:含有要更改数据的列的名称。
●expression:变量、字面值、表达式或加上括号的返回单个值的subSELECT语句。
●DEFAULT:指定使用对列定义的默认值替换列中的现有值。
●@variable:已声明的变量,该变量将设置为expression所返回的值。
●FROM{<table_source>}:指定用表来为更新操作提供准则。
●WHERE:指定条件来限定所更新的行。
●<search_condition>:为要更新行指定需满足的条件。
●CURRENT OF:指定更新在指定游标的当前位置进行。
●GLOBAL:指定cursor_name是全局游标。
●cursor_name:要从中进行提取的开放游标的名称。
●cursor_variable_name:游标变量的名称。
●OPTION(<query_hint>[,…n]):指定优化程序提示用于自定义SQL Server的语句处理。
15)PRINT语句的语法格式如下:
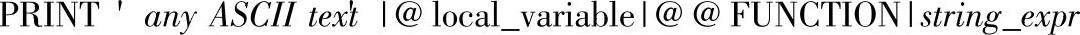
其中的参数说明如下。
●′anyASCIItex′t:一个文本字符串。
●@local_variable:任意有效的字符数据类型变量。@local_variable必须是char或var-char,或者能够隐式转换为这些数据类型。
●@@FUNCTION:返回字符串结果的函数。@@FUNCTION必须是char或varchar,或者能够隐式转换为这些数据类型。
●string_expr:返回字符串的表达式。可包含串联的字面值和变量。消息字符串最长可达8000个字符,超过8000个的任何字符均被截断。
16)DECLARE语句的语法格式如下:

其中的参数说明如下。
●@local_variable:变量的名称。变量名必须以at符(@)开头。局部变量名必须符合标识符规则。
●data_type:是任何由系统提供的或用户自定义的数据类型。
●@cursor_variable_name:游标变量的名称。
●CURSOR:指定变量是局部游标变量。
●table_type_definition:定义表数据类型。表声明包括列定义、名称、数据类型和约束。允许的约束类型只包括PRIMARY KEY、UNIQUE KEY、NULL和CHECK。
●n:表示可以指定多个变量并对变量赋值的占位符。当声明表变量时,表变量必须是DECLARE语句中正在声明的唯一变量。
17)RETURN语句的语法格式如下:
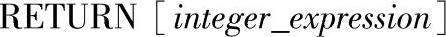
其中的参数说明如下。
●integer_expression:返回的整型值。存储过程可以给调用过程或应用程序返回整型值。
18)WAITFOR语句的语法格式如下:
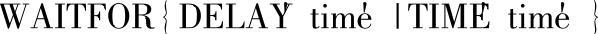
其中,DELAY指定时间间隔,TIME指定某一时刻。TIME参数的数据类型为datetime,格式为“hh:mm:ss”。归纳总结
通过这次任务的实践,了解了SQL语句的语法结构和用法,了解了SQL的数据类型,掌握了程序的基本结构和设计程序规范,基本可以独立地编写简单的Transact-SQL程序,为后面存储过程和触发器的设计打下了良好的基础。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。