



在SQL中,一个SELECT语句查询块可以嵌套在另外一个查询块的WHERE子句中,这种查询称为嵌套查询。
嵌套查询可以用多个简单的查询构成十分复杂的查询,从而增强SQL的查询能力,使SQL的查询非常灵活。其中最上层的查询称为父查询或外层查询,WHERE子句中的查询块称为子查询或内层查询。SQL的结构化含义主要体现在嵌套查询中。
嵌套查询在执行时是由里向外的,即先执行内查询,再执行外查询。
1.简单的嵌套查询
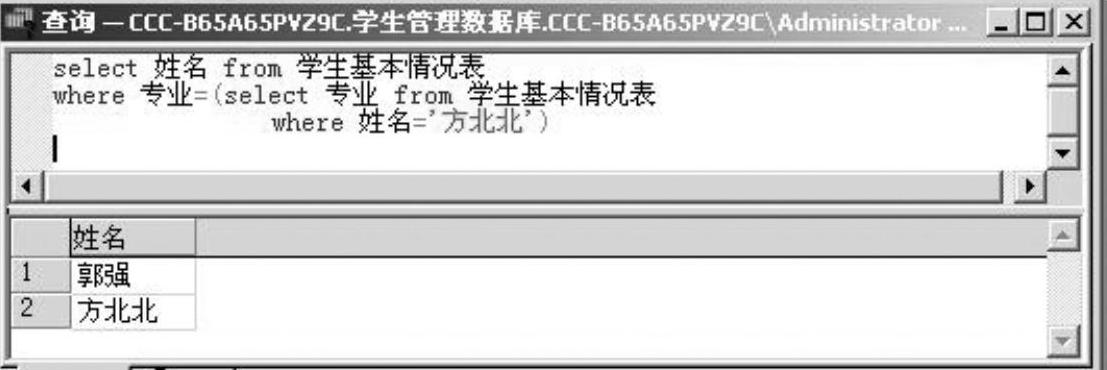
图2-35 例2-30的查询语句及查询结果窗口
2.带IN的子查询
在嵌套查询中,因为一个子查询的结果往往是一个集合,这时就不能用“=”,而需要用到特殊运算符IN。
例2-31 查询选修了“英语”课程的学生名单。
本例学习有关特殊运算符IN的使用,如图2-36所示。
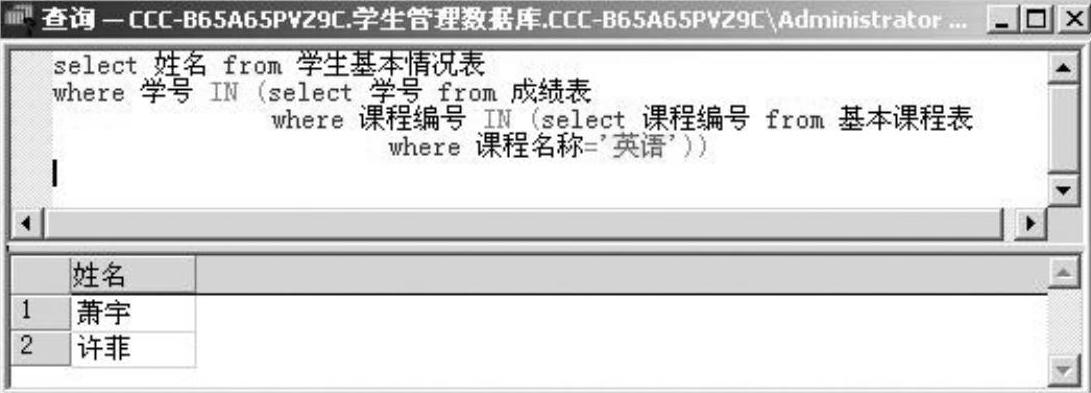
图2-36 例2-31的查询语句及查询结果窗口
3.带ANY或ALL的子查询
当子查询的返回值是一个值时可以使用关系运算符。在SQL中,还提供了两个必须和关系运算符搭配才能使用的运算符ANY和ALL,它们使用时的含义如下。
●>ANY:大于子查询结果中的某一个值。
●>ALL:大于子查询结果中的所有值。
●<ANY:小于子查询结果中的某一个值。
●<ALL:小于子查询结果中的所有值。
●>=ANY:大于或等于子查询结果中的某一个值。
●>=ALL:大于或等于子查询结果中的所有值。
●<=ANY:小于或等于子查询结果中的某一个值。
●<=ALL:小于或等于子查询结果中的所有值。
●=ANY:等于子查询结果中的某一个值。
●=ALL:等于子查询结果中的所有值。
●!=ANY:不等于子查询结果中的某一个值。
●!=ALL:不等于子查询结果中的所有值。
例2-32 列出所有非国际贸易专业中比国际贸易专业中的某个学生年龄大的学生的姓名和年龄。
本例学习有关嵌套查询中ANY运算符的用法,如图2-37所示。
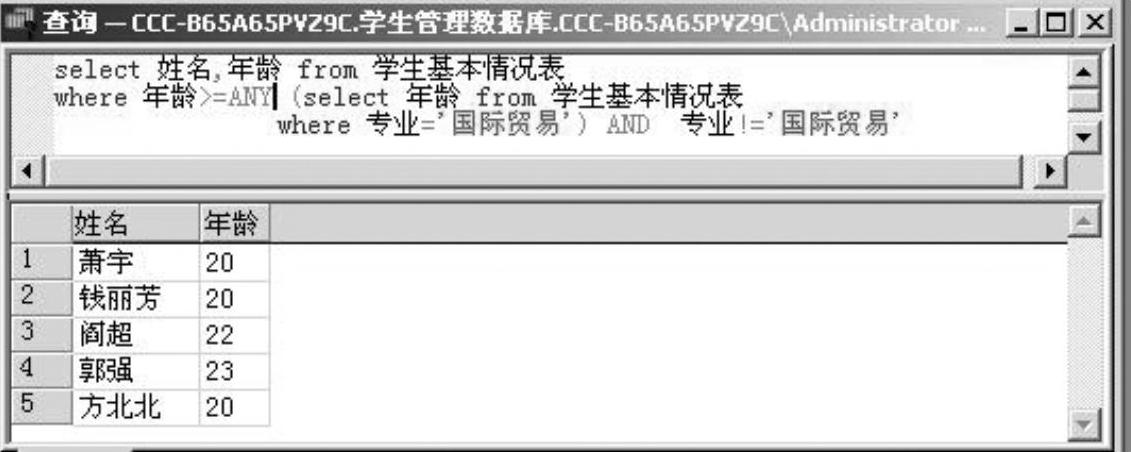
图2-37 例2-32的查询语句及查询结果窗口
例2-33 列出所有非国际贸易专业中比国际贸易专业中的所有学生年龄大的学生的姓名和年龄。
本例学习有关嵌套查询中ALL运算符的用法,如图2-38所示。
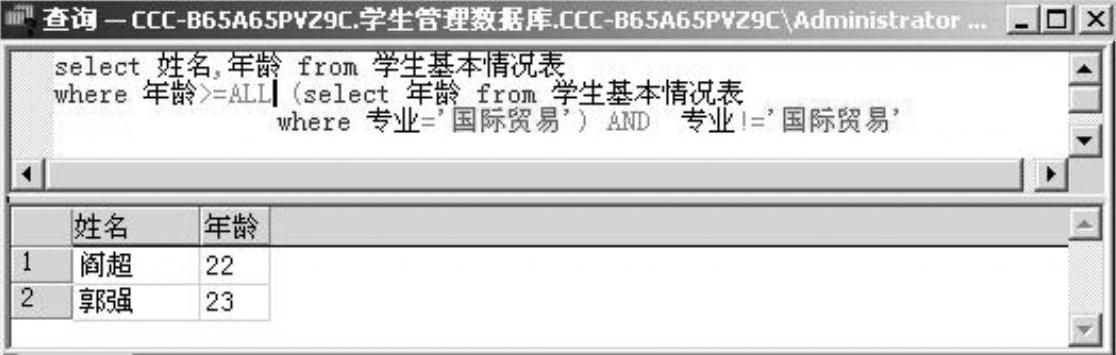
图2-38 例2-33的查询语句及查询结果窗口
4.带EXISTS的子查询
关键字EXISTS表示“存在”的意思,它只查找满足条件的那些记录,一旦找到第一个匹配的记录后,则马上停止查找。其返回的值是逻辑值“真”或“假”,即表示找到或者没找到,而不返回任何记录。
例2-34 列出所有选修了课程“K004”的学生的姓名和学号。
本例学习关键字EXISTS的用法,如图2-39所示。注意,因WHERE子句的结果为真,所以列出所有学生的姓名和学号。
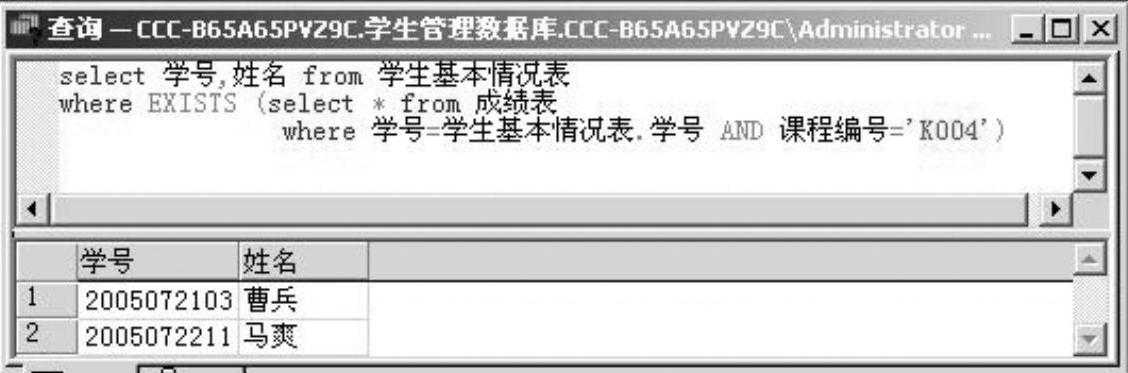
图2-39 例2-34的查询语句及查询结果窗口
5.在WHERE子句中使用集合函数
例2-35 列出年龄最大的学生的信息。
本例学习在WHERE子句中使用集合函数的方法,如图2-40所示。
注意:不能在WHERE子句中直接用集合函数,如果将本例改为“select*from学生基本情况表where年龄=MAX(年龄)”,则会出错。
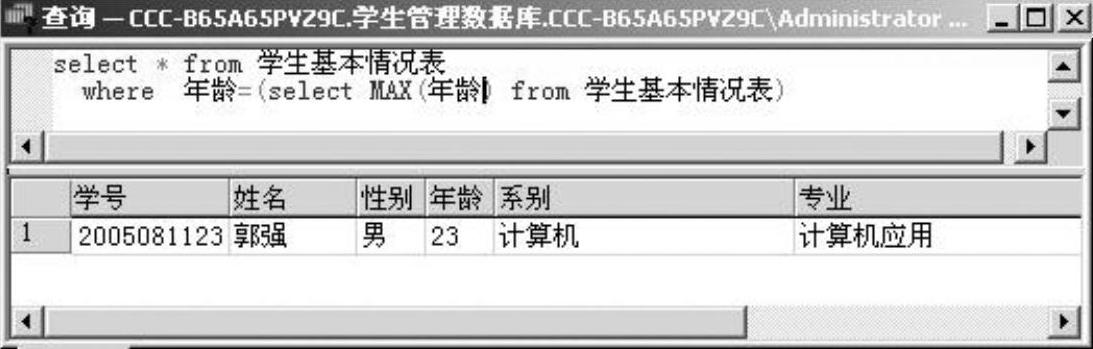
图2-40 例2-35的查询语句及查询结果窗口
6.带子查询的插入语句
记录插入(INSERT)语句与SELECT语句结合起来可以对表进行批量数据插入。进行批量数据插入的新表与原表的字段名可以相同,也可以不同,甚至列数也可以不同,但是要求对应列的类型必须保持一致,否则类型转换会出错。
例2-36 先创建一个与学生基本情况表结构一样的学生基本情况表1,其中存放了一个年龄最大的学生的记录,接下来在学生基本情况表1中批量插入所有学生基本情况表中的女生的信息,最后显示学生基本情况表1中的所有信息,如图2-41所示。
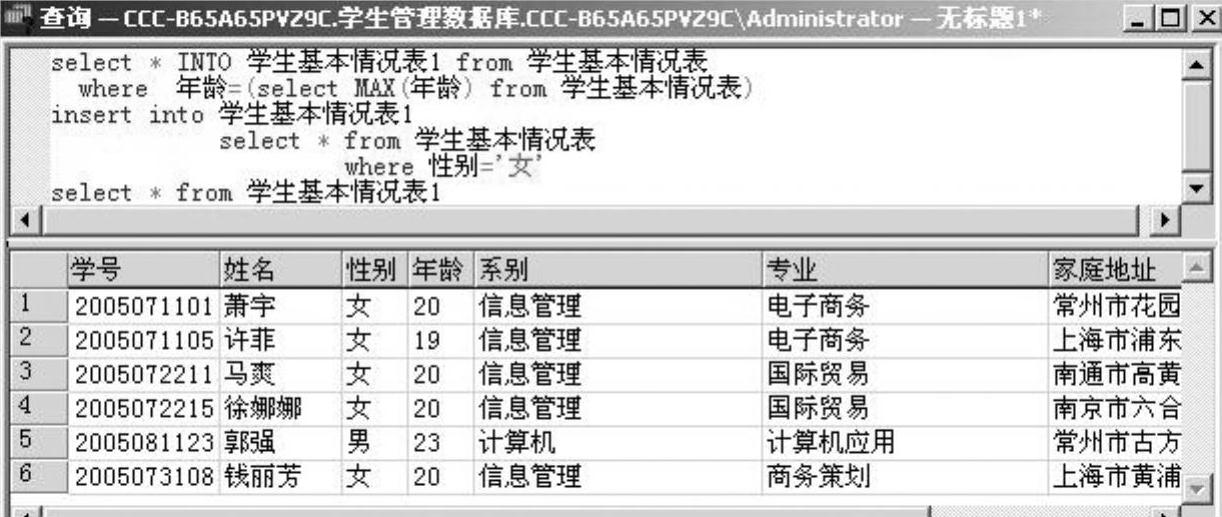
图2-41 例2-36的查询语句及查询结果窗口
7.带子查询的删除语句
记录删除(DELETE)语句与SELECT语句结合起来可以对表中数据进行删除。
例2-37 删除学生基本情况表1中所有“国际贸易”专业的学生信息,如图2-42所示。
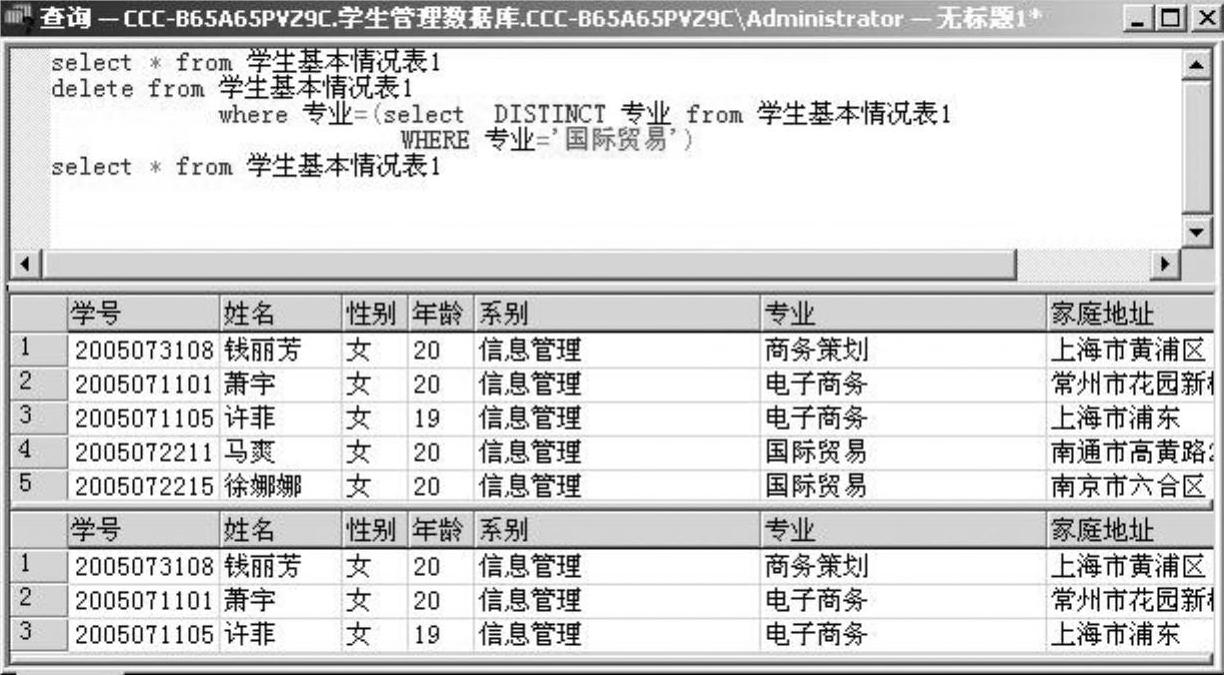
图2-42 例2-37的查询语句及查询结果窗口
8.带子查询的修改语句
修改(UPDATE)语句与SELECT语句结合起来可以对表中数据进行修改。
例2-38 将学生基本情况表1中所有“电子商务”专业的学生的年龄加2,如图2-43所示。
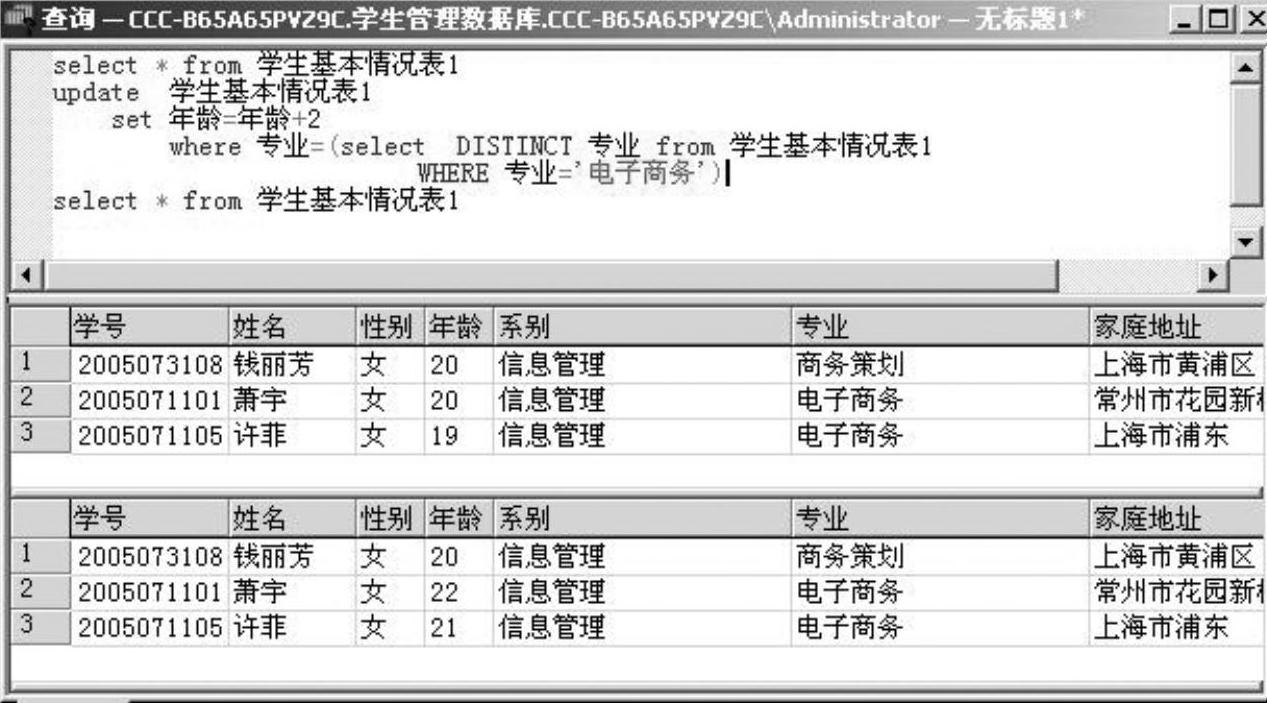
图2-43 例2-38的查询语句及查询结果窗口
读一读
1.SQL的发展过程
SQL是Structured Query Language的缩写,意思为结构化查询语言。SQL的主要功能是同各种数据库建立联系,进行沟通。按照ANSI(美国国家标准协会)的规定,SQL是关系数据库管理系统的标准语言。
SQL最早是为关系数据库管理系统(RDBMS)开发的一种查询语言,它的前身是SQUARE语言。SQL结构简洁,功能强大,简单易学,所以自从IBM公司1981年推出以来,SQL得到了广泛的应用。如今无论是像Oracle、Sybase、informix、SQL Server这些大型的数据库管理系统,还是像Visual Foxpro、Access、PowerBuilder这些微机上常用的数据库开发系统,都支持SQL作为其查询语言。
SQL的发展是从20世纪70年代初开始的,当时E.F.Codd首先提出了关系模型。20世纪70年代中期,IBM公司在研制SYSTEM R关系数据库管理系统中研制了SQL,最早的SQL是于1976年11月公布的。
1979年,Oracle公司首先提供商用的SQL,IBM公司在DB2和SQL/DS数据库系统中也实现了SQL。
1986年10月,ANSI采用SQL作为关系数据库管理系统的标准语言(ANSI X3.132-11986),后国际标准化组织(ISO)采纳SQL为国际标准。
1989年,ANSI采纳在ANSI X3.132-1-1989报告中定义的关系数据库管理系统的SQL标准语言,称为ANSI SQL 89,该标准替代了ANSI X3.132-1-1986版本。
2.SQL的特点
SQL语句可以用来执行各种各样的操作,例如,更新数据库中的数据、从数据库中提取数据等。SQL包含4个部分:
●数据查询语言(SELECT)。
●数据操纵语言(INSERT、UPDATE、DELETE)。
●数据定义语言(CREATE、ALTER、DROP)
●数据控制语言(COMMIT、ROLLBACK)。
目前,所有主要的关系数据库管理系统都支持某种形式的SQL,大部分数据库都遵守ANSI SQL 89标准。
SQL使全部用户,包括应用程序员、数据库管理员和终端用户受益匪浅。SQL得以广泛地被采用主要是得益于它具有以下优点。(https://www.xing528.com)
●非过程化语言:SQL是一个非过程化的语言,因为它一次处理一个记录,对数据提供自动导航。SQL允许用户在高层的数据结构上工作,而不对单个记录进行操作,可操作整个记录集,所有SQL语句接受集合作为输入,返回集合作为输出。SQL的集合特性允许一条SQL语句的结果作为另一条SQL语句的输入。另外SQL不要求用户指定对数据的存放方法,这种特性使用户更易集中精力于要得到的结果。所有SQL语句使用查询优化器,它是RDBMS的一部分,由它决定对指定数据存取的最快速度的手段,查询优化器知道存在什么索引,在哪儿使用索引合适,而用户则从不需要知道表是否有索引、有什么类型的索引。
●统一的语言:SQL可用于所有用户的数据库活动,包括系统管理员、数据库管理员、应用程序员、决策支持系统人员及许多其他类型的终端用户。基本的SQL命令只需很少时间就能学会,最高级的命令也可在短时间内掌握。SQL提供的命令包括:查询数据,在表中插入、修改和删除记录,建立、修改和删除数据对象,控制对数据和数据对象的存取,保证数据库一致性和完整性等。
●是所有关系数据库的公共语言:由于所有主要的关系数据库管理系统都支持SQL,用户可将使用SQL的技能从一个RDBMS转到另一个,所有用SQL编写的程序都是可以移植的。
可执行的SQL语句的种类数目非常多。使用SQL,可以执行任何功能,从一个简单的表查询,到创建表和存储过程,再到设定用户权限。常见的SQL语句有SELCET、INSERT、UPDATE、DELETE、CREATE、DROP等。
3.查询的含义
在关系数据库中,查询是指采用一定的方法从数据库中获取所需数据的过程。当对一个数据库执行查询时,其执行的结果是从数据库中寻找所需的信息并返回给用户。另外查询也可以直接操纵数据,如使用查询可以插入、更新和删除表中的数据等。
查询功能是SQL中最主要、最核心的功能,这从SQL的含义中就可以看出。对于数据库用户来说,任何时候使用SQL语句与SQL Server中的数据进行交互时,都是在执行一个查询,并且查询可以保存起来,以便以后多次重复执行,这给用户的使用带来了很大的方便。
4.SQL查询语句SELECT
在SQL Server中,SQL语句主要是在“查询分析器”中执行的,并且采用的是Transact-SQL,其功能比标准的SQL有所扩充。在SQL中,查询语句SELECT的完整语法较复杂,但是其主要的子句可归纳如下:

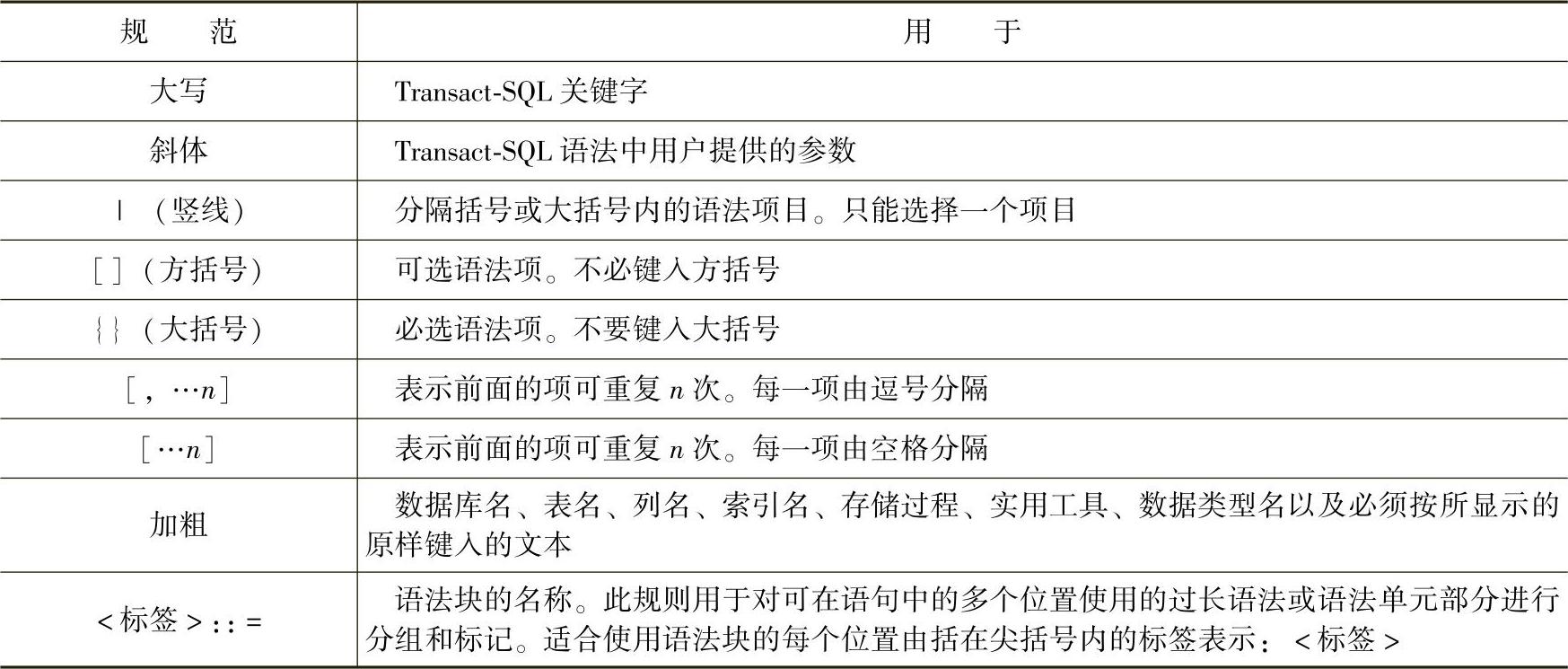
还可以在查询之间使用UNION运算符,以将查询的结果组合成单个结果集。Transact-SQL的语法使用了表2-4中的书写规则。
表2-4 书写规则
下面分别对SELECT子句进行说明。
1)SELECT子句:指定由查询返回的列,语法格式如下。

其中的参数含义如下。
ALL:指定在结果集中可以显示重复行。ALL是默认设置。
DISTINCT:指定在结果集中只能显示唯一行。为了DISTINCT关键字的用途,空值被认为相等。
TOP n[PERCENT]:指定只从查询结果集中输出前n行。n是0~4294967295之间的整数。如果还指定了PERCENT,则只从结果集中输出前n%行。当指定时带PERCENT时,n必须是0~100之间的整数。如果查询包含ORDER BY子句,将输出由ORDER BY子句排序的前n行(或前n%行)。如果查询没有ORDER BY子句,行的顺序将任意。
WITH TIES:指定从基本结果集中返回附加的行,这些行包含与出现在TOP n[PER-CENT]行最后的ORDER BY列中的值相同的值。如果指定了ORDER BY子句,则只能指定TOP…WITH TIES。
<select_list>:为结果集选择的列。选择列表是以逗号分隔的一系列表达式。
*:指定在FROM子句内返回所有表和视图内的所有列。列按FROM子句所指定的由表或视图返回,并按它们在表或视图中的顺序返回。
table_name|view_name|table_alias.*:将*的作用域限制为指定的表或视图。
column_name:要返回的列名。限定column_name以避免二义性引用,当FROM子句中的两个表内有包含重复名的列时会出现这种情况。
expression:是列名、常量、函数以及由运算符连接的列名、常量和函数的任意组合,或者是子查询。
IDENTITYCOL:返回标识列。有关更多信息,可参见IDENTITY(属性)、ALTER TA-BLE和CREATE TABLE。如果FROM子句中的多个表内有包含IDENTITY属性的列,则必须用特定的表名(如T1.IDENTITYCOL)限定IDENTITYCOL。
ROWGUIDCOL:返回行全局唯一标识列。如果在FROM子句中有多个表具有ROWGUIDCOL属性,则必须用特定的表名(如T1.ROWGUIDCOL)限定ROWGUIDCOL。
column_alias:查询结果集内替换列名的可选名。
2)INTO子句:创建新表并将结果行从查询插入新表中,语法格式如下。
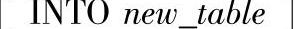
其中的参数含义如下。
new_table:根据选择列表中的列和WHERE子句选择的行,指定要创建的新表名。new_table的格式通过对选择列表中的表达式进行取值来确定。new_table中的列按选择列表指定的顺序创建。new_table中的每列有与选择列表中的相应表达式相同的名称、数据类型和值。
当选择列表中包含计算列时,新表中的相应列不是计算列。新列中的值是在执行SE-LECT…INTO时计算出的。
3)FROM子句:指定从其中检索行的表。需要FROM子句,除非选择列表只包含常量、变量和算术表达式(没有列名),语法格式如下。

其中的参数含义如下。
<table_source>:指定用于SELECT语句的表、视图、派生表和联接表。
4)WHERE子句:指定用于限制返回的行的搜索条件,语法格式如下。
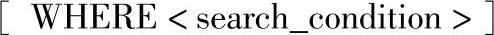
其中的参数含义如下。
<search_condition>:通过使用谓词限制结果集内返回的行。对搜索条件中可以包含的谓词数量没有限制。
5)GROUP BY子句:指定用来放置输出行的组,并且如果SELECT子句<select list>中包含聚合函数,则计算每组的汇总值。指定GROUP BY时,选择列表中任一非聚合表达式内的所有列都应包含在GROUP BY列表中,或者GROUP BY表达式必须与选择列表表达式完全匹配。如果未指定ORDER BY子句,则使用GROUP BY子句不按任何特定的顺序返回组。建议始终使用ORDER BY子句指定具体的数据顺序。语法格式如下:
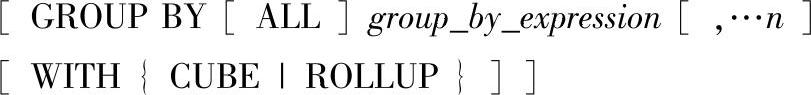
其中的参数含义如下。
ALL:包含所有组和结果集,甚至包含那些任何行都不满足WHERE子句指定的搜索条件的组和结果集。如果指定了ALL,将对组中不满足搜索条件的汇总列返回空值。不能用CUBE或ROLLUP运算符指定ALL。
如果访问远程表的查询中有WHERE子句,则不支持GROUP BY ALL操作。
group_by_expression:是对其执行分组的表达式。group_by_expression也称为分组列,可以是列或引用列的非聚合表达式。在选择列表内定义的列的别名不能用于指定分组列。
说明:text、ntext和image类型的列不能用于group_by_expression。
对于不包含CUBE或ROLLUP的GROUP BY子句,group_by_expression的项数受查询所涉及的GROUP BY列的大小、聚合列和聚合值的限制。该限制从8060 B的限制开始,对保存中间查询结果所需的中间级工作表有8060 B的限制。如果指定了CUBE或ROLLUP,则最多只能有10个分组表达式。
CUBE:指定在结果集内不仅包含由GROUP BY提供的正常行,还包含汇总行。在结果集内返回每个可能的组和子组组合的GROUP BY汇总行。GROUP BY汇总行在结果中显示为NULL,但可用来表示所有值。使用GROUPING函数确定结果集内的空值是否为GROUP BY汇总值。
结果集内的汇总行数取决于GROUP BY子句内包含的列数。GROUP BY子句中的每个操作数(列)绑定在分组NULL下,并且分组适用于所有其他操作数(列)。由于CUBE返回每个可能的组和子组组合,因此不论指定分组列时所使用的是什么顺序,行数都相同。
ROLLUP:指定在结果集内不仅包含由GROUP BY提供的正常行,还包含汇总行。按层次结构顺序,从组内的最低级别到最高级别汇总组。组的层次结构取决于指定分组列时所使用的顺序。更改分组列的顺序会影响在结果集内生成的行数。
6)HAVING子句:指定组或聚合的搜索条件。HAVING通常与GROUP BY子句一起使用。如果不使用GROUP BY子句,HAVING的行与WHERE子句一样。语法格式如下:
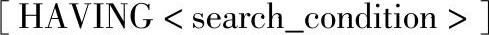
其中的参数含义如下。
<search_condition>:指定组或聚合应满足的搜索条件。当HAVING与GROUP BY ALL一起使用时,HAVING子句替代ALL。在HAVING子句中不能使用text、image和ntext数据类型。在SELECT语句中使用HAVING子句不影响CUBE运算符分组结果集和返回汇总聚合行的方式。
7)UNION运算符:将两个或更多查询的结果组合为单个结果集,该结果集包含联合查询中的所有查询的全部行。这与使用联接组合两个表中的列不同。
使用UNION组合两个查询的结果集的两个基本规则:所有查询中的列数和列的顺序必须相同;数据类型必须兼容。语法格式如下:

其中的参数含义如下。
<query_specification>|(<query_expression>):查询规范或表达式,用以返回与另一个查询规范或查询表达式所返回的数据组合的数据。作为UNION运算一部分的列定义可以不相同,但它们必须通过隐性转换实现兼容。
UNION:指定组合多个结果集并将其作为单个结果集返回。
ALL:在结果中包含所有的行,包括重复行。如果没有指定,则删除重复行。
8)ORDER BY子句:指定结果集的排序。除非同时指定了TOP,否则ORDER BY子句在视图、内嵌函数、派生表和子查询中无效。语法格式如下:
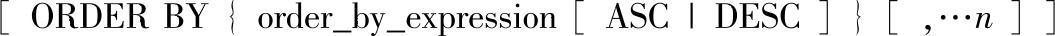
其中的参数含义如下。
order_by_expression:指定要排序的列。可以将排序列指定为列名或列的别名(可由表名或视图名限定)和表达式,或者指定为代表选择列表内的名称、别名或表达式的位置的负整数。
可指定多个排序列。ORDER BY子句中的排序列序列定义排序结果集的结构。
ORDER BY子句可包括未出现在此选择列表中的项目。然而,如果指定SELECT DIS-TINCT,或者如果SELECT语句包含UNION运算符,则排序列必定出现在选择列表中。
此外,当SELECT语句包含UNION运算符时,列名或列的别名必须是在第一选择列表内指定的列名或列的别名。
在ORDER BY子句中不能使用ntext、text和image列。
ASC:指定按递增顺序,从最低值到最高值对指定列中的值进行排序。
DESC:指定按递减顺序,从最高值到最低值对指定列中的值进行排序。
空值被视为最低的可能值。对ORDER BY子句中的项目数没有限制。然而,对于排序操作所需的中间级工作表的大小有8060 B的限制。这限制了在ORDER BY子句中指定的列的合计大小。
归纳总结
通过这次任务的实践,熟悉了查询分析器的使用,掌握了查询语句的语法规则和基本应用,了解了数据查询的作用和数据库的基本应用,对数据库有了进一步的理解,为数据库的数据处理打下了良好的基础。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。