



多发射体系结构已提供了一个平台,通过挖掘指令执行的并行性来提高处理机速度。但这并不完全是硬件设计问题,提高指令执行并行性必须要有编译器的底层优化,指令流的重组,通过软件与硬件的配合来达到提高指令执行并行性的目的。这种硬件/软件结合措施的研究,称为指令级并行性(Instruction Level Parallelism,ILP)研究。ILP研究是自20世纪90年代以来提高处理机性能的一个十分重要的研究领域。
指令级并行性开发的关键在于对即将执行的指令进行处理,从中寻找出可以并行执行的指令并将这些指令发射到功能流水线,并尽可能地将功能流水线充满,减少功能流水线中的气泡,从而提高功能流水线的效率和处理机的整体性能,这被称为指令调度技术。指令的调度要依赖于微处理器中一组被称作指令调度器的功能部件,这些功能部件在不同的微处理器中可能会被赋予不同的名称。指令调度器必须能够在尽可能短的时间内找到尽可能多的可以并行执行的指令,并将这些指令发射到合适的功能流水线之中,这对于提高微处理器的并行度,进而提高微处理器的性能至关重要。
指令调度所受到最大的限制就是指令流水执行方式中遇到的相关性问题。这些相关性问题包括:①寄存器相关性,即不同指令使用同一个寄存器引起的相关性,寄存器相关又包括反映指令之间数据流关系的数据相关性和两条指令对同一名字进行读/写却没有数据相关性的名字相关性;②Load/Store相关性,即不同指令存取同一个内存单元引起的相关性,与寄存器相关类似,Load/Store相关也包括上述寄存器相关的两种情况;盂控制相关性,即各种控制指令造成的指令流的不确定性引起的相关性,由于控制指令主要由各种转移指令组成,所以控制相关性又被称为转移相关性。这些相关性造成处理机实际运行中流水线不能充满而出现“气泡”,或者使流水线“断流”,从而使处理机指令执行的并行性减低,实际速度下降。
在ILP研究中,有一个很重要的参数是IPC(Instruction Per Cycle),即每个周期能够执行几条指令。它与前面所述的参数CPI(C)互为倒数。在多发射超标量结构中,如每个周期发射N条指令,则理想情况下,IPC=N。但一般情况下由于种种限制,处理机的实际IPC值都无法达到甚至远远低于N。ILP研究的关键就是提高IPC值,进而提高处理机的性能。20世纪80年代后期以来,实用的商用处理机大量地使用了各种提高指令级并行性的措施。这些措施无一例外地致力于提高同时发射的指令数N和流水线的使用效率,进而提高IPC。
这些措施主要有。
1.增加处理机的功能执行部件和扩大指令发射窗口
这是20世纪90年代初期采用的较直观的办法。功能执行部件(Function Unit)一般分为整数部件(整数流水线)、浮点部件(浮点流水线)、存储指令部件(也称LOAD/STORE部件)和分支处理部件。每种部件可以是一个,也可以有多个,如Pentium Ⅱ和Pentium Ⅲ各有整数流水线二个,浮点流水线一个。指令发射窗口是指在处理机的指令寄存器内安放几条指令能同时发射,一般现代处理机的指令发射窗口可放二条或四条指令甚至更多。相关研究表明,即使功能部件增大到无限,指令窗口增加到很大,指令并行度的最大值将会达到饱和,其饱和值最大为7~8,仿真研究结果和实际结果很接近。这个极限值实际上是受程序本身决定的。换句话说,指令流本身的基本块大小有限,即使进行指令调度,单靠增加发射指令数和增加执行部件是不够的。这种研究引导出的结论是必须设法进一步采用硬/软件结合的办法,扩大基本块,或者说,进行跨基本块的指令调度。
2.VLIW
在讨论扩大指令窗口时,应该提到VLIW。VLIW是“很长指令字(Very Long Instruction Window)”结构的缩写,是由原耶鲁大学Fisher教授提出的。在VLIW中,每条指令包括16~32个并行的操作(这里的操作相当于传统意义上的指令)并由编译器来挖掘操作(指令)之间的并行性。这样,就相当于指令窗口被扩大到了16~32。这么长的指令字,势必已超过基本块的长度。因此,他提出的所谓“路踪调度法”的基本出发点是,在包含很多个转移分支的一段程序中,一定可以在编译期间预测出一条指令执行的顺序通路(称为“路踪”),即“主流”,程序大部分执行时间是花在这条通路上的。指令将在这条跨基本块的通路内进行调度。这个出发点是建立在大量程序(尤其是科学计算程序)分析统计基础上的。
路踪调度法(Trace-Scheduling)可用图2-24a、b和c表示。图2-24a包含有一段程序,其中一个小方块表示一个基本块。基本块之间有很多链接,其中很多是转移分支的链接。根据路踪调度法可以找出一条执行时花费时间最多的路踪,用阴影来表示。图2-24b表示可把这些基本块的链接解开,把有阴影的路踪分离出来。这种重新安排可能使“路踪”和其他基本块指令并行执行,或是可能在“路踪”内进行跨基本块的指令调度,从而可提高指令执行的并行性。或者说,允许同时发射更多条指令。但这只不过是说“可能”,因为原来链接解开以后,指令流最后执行的效果会变得与原来程序的效果不同。所以,还需要重新链接,见图2-24c。在重新链接时,要加入两种指令流模块,分开S(Spit)和重结R(Rejoin)。加上S和R,再用虚线把S与R和原来脱离链接的基本块重新结合起来,从而使总的执行效果和原来程序执行效果相同。

图2-24 路踪调度法
Fisher根据路踪调度法,曾设计过VLIW处理机系列,其指令长度为16、32等,但没有成功。其主要原因是,由于在编译优化时,需要加入的分开S和重结R的指令段太多,以致编译后生成的执行代码太长,其带来的执行时间开销已经超过了增加指令并行性的好处。因此,VLIW处理机至今没有成为通用处理机产品。但是,路踪调度法的思想已包含了在处理转移分支时,采用预测或猜测的方法,在跨基本块的指令调度中提高指令执行并行性的思想。同时,VLIW思想会用在SIMD或MPEG处理机中,在这类处理机中,编译后的执行代码不会因插入S和R而增长很多,而且MPEG处理机本身指令流的并行性很好,对开发VLIW处理机也很有利。另外,同一周期内发出适当长度的指令字(如长度为4或8),即LIW(Long Instruction Word)的处理机结构,也已被Intel所采用而成为其下一代处理机体系结构IA-64的核心而得到进一步发展。
3.转移预测和猜测执行、转移延迟
转移预测(Branch Prediction)和猜测执行(Speculative Execution)是为了扩大基本块,发掘指令级并行性。这两种提高指令执行并行性的方法,都需有硬件支持。
转移预测可在条件转移指令的流水级执行以前,预先取出目标地址指令,从而可使流水线执行效率不致降低。如果预测成功,实际上扩大了基本块,增加了参加调度的指令数量,从而提高了指令调度的效率。如果预测不成功,则要采取措施,弥补因错误预测带来的性能损失。转移预测可分以下几种。
1)静态转移预测方法
如在执行循环语句时,在条件未满足时,执行完一个循环体的最后一条指令后,要向前返回到循环体的第一条指令去执行其次的一个循环体。因此,如在遇到条件转移指令,其目标地址是返回到前面去的,则可预测转移发生(Taken)。这种简单的静态转移预测的准确率可达70%左右而且硬件比较简单,早期的处理机中有所采用。
2)动态转移预测方法
动态转移预测又可分为历史记录转移预测方法和转移预测缓冲方法。
历史记录转移预测方法的基本原理是根据最近几次转移是否发生来预测下一次转移是否发生。一般情况下,历史记录法都以一个有限状态自动机来表示。在这个自动机中,以最近几次转移是否发生为自动机的内态,以下一转移的方向(向前或向后)为自动机的输入或无输入,以转移预测结果(是否转移)为自动机的输出。不同的转移预测算法对应于不同的有限状态自动机。图2-25所显示的就是一种典型的转移预测自动机,如最近两次的转移指令在实际上都“发生”了,那么这次预测转移指令也会发生。如本次预测失败了,那么,在下次预测时的“可信度”就要下降。当然,各种历史记录预测方法各有差异,其转移预测自动机也有所不同。历史记录的内容越丰富,则预测的成功率越高,但其自动机表达和硬件实现也越复杂。
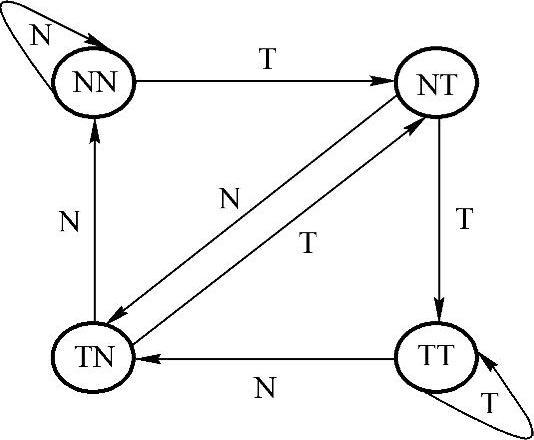
图2-25 典型的转移预测自动机

转移预测缓冲(Branch Target Buffer,BTB)方法是另外一种提高转移预测成功率的常用手段,它实际上是一个全相联Cache,每个入口对应于一行,每行分两部分。前面部分是过去发生过转移的指令的地址,后面部分是其转移目标指令以及其随后的一串指令(共N条)。这种转移预测的思想是,如果过去某单元地址中的转移指令在实际执行时发生了转移,而当前又碰到了这个单元地址中的转移指令,那么,这次转移可以预测会“发生”。此外,根据程序的局部性,一旦取出一条转移目标地址处的指令,其后的一连串指令也一定会执行。因此,如果当前转移指令的地址与BTB中某一行入口地址在全相联搜索过程中发生匹配,则表示该当前条件转移指令会发生转移,同时把该Cache行中的N条指令一起取出,放入处理机的预取指令队列中去。这种方法实际上是历史记录方法和程序局部性的结合。
在大多数现代的处理机中,为了提高转移预测的成功率,减少转移相关带来的性能损失,根据历史记录的转移预测和BTB经常被同时使用。成功的转移预测可以大大增大调度基本块,使程序执行过程中转移相关对系统性能的影响得到最大限度的降低。
在转移预测的同时,延迟转移也被用来减小转移带来的性能损失。延迟转移的思想就是将条件转移指令的执行加以提前,用一条或几条与条件转移指令不相关的指令来填充条件转移指令后的延迟槽,而这些延迟槽中的指令在处理过程中是不受条件转移指令影响的。通过这种方式,转移指令带来的流水线“气泡”和“断流”将会得到很大的改善。包括MIPS R10000和PowerPC在内的大量现代处理机都使用了这种技术。
但是,延迟转移也不是万能的。在很多情况,尤其是在指令流水线很长的情况(如In-tel Pentium 4的20级流水线)下,找到足够的与条件转移不相关的指令是很困难甚至不可能的。这时延迟转移槽中只能填充一些空指令(即NOP指令),延迟转移的优势也无法得到发挥,转移预测的成功与否对处理机性能的影响也就越发显得重要了。
4.乱序执行和重排序缓冲器
在传统的处理机中,指令是按照其在程序中的动态顺序来执行的,而这种顺序执行方式(In-Order-Execution)经常会引起一条指令的阻塞造成其后大量指令的阻塞现象。在现代处理机中,一般采用乱序执行(Out-Order-Execution)的方式来解决这个问题。
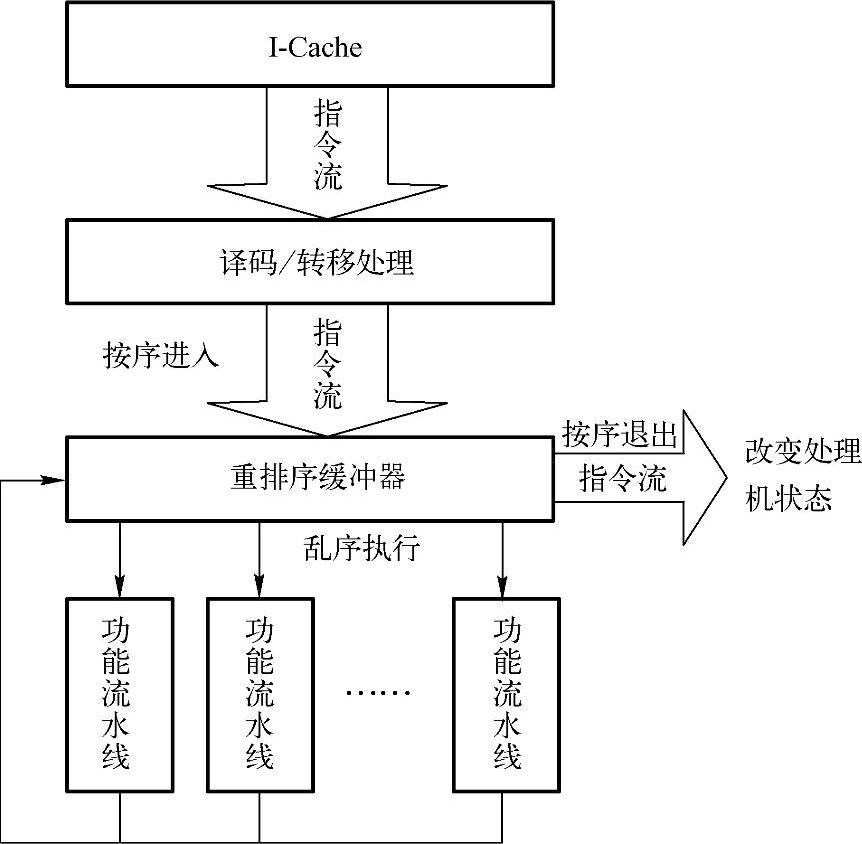
乱序执行的实现主要依赖于处理机中的重排序缓冲器(Re-Order Buffer)。在程序的执行过程中,指令首先按照其顺序进入处理机的重排序缓冲器中并记录其顺序。然后在重排序缓冲器中等待其相关指令的运行结束(以满足指令之间的相关关系)和指令所需的相关资源(尤其是功能流水线)的空闲可用。一旦上述要求得到满足,指令将被从重排序缓冲器中发射到功能流水线以完成其运行。当指令运行结束后,指令的执行结果并不直接对处理机状态进行改变,而是暂时存储在重排序缓冲器中,直到重排序缓冲器中所有在该指令之前进入重排序缓冲器的所有指令都已经退出重排序缓冲器之后,该指令才退出重排序缓冲器并实际改变处理机状态(这个过程被称为“退休”)。上面的过程被总结为“按序进入,乱序执行,按序退出”(见图2-26)。
需要注意到的是,在现代处理机中,绝大多数处理机都使用了以重排序缓冲器为基础的乱序执行方式来提高程序执行的指令级并行性。Intel X86系列处理器的Pentium Pro之后的处理器都采用了乱序执行方式。在很多处理机的微体系结构中把重排序缓冲器的功能分别由多个部件来实现,这些部件一般包括:重排序缓冲器Re-Order Buffer、预约站Reserve Sta-tion、退休部件Retire Unit、已执行指令缓冲器Executed Instruction Buffer等。
在现代的乱序执行处理机中,重排序缓冲器的规模对处理机的性能影响很大,重排序缓冲器越大,能够容纳的指令越多,则乱序执行时功能流水线的利用率也就越高。但是由于重排序缓冲器中的各指令项不是遵循FIFO的顺序而是需要随机并行访问,大规模的重排序缓冲器的实现也比较困难。例如,在Intel Pentium Pro中重排序缓冲器的项目数只有40/20项(重排序缓冲40项,预约站20项)。
 (https://www.xing528.com)
(https://www.xing528.com)
图2-26 重排序缓冲器的结构和指令的执行过程
5.处理寄存器名字相关的寄存器重命名
在指令相关中有时会出现一种被称为名字相关的假相关现象,即两条指令之间实际上数据并不相关,但由于它们使用了同一个寄存器来暂存或存储数据而使处理机在指令调度的过程中将它们判断为相关。这种假相关现象一般来自于寄存器数量的不足。在早期的微处理器中,由于受限于芯片的集成度,寄存器的数量一般比较少,而且寄存器大都具有独特的不可替代的用途,这就带来了微处理器中寄存器的争用现象。在早期的微处理器中,由于性能上要求不高,而且指令之间的重叠与并行执行也没有得到广泛应用,所以这种寄存器的争用还可以依靠程序员或者编译程序对程序中的指令次序的优化来解决。随着微处理器性能的不断提高,指令执行的并行度,也就是IPC的值也不断提高,寄存器争用现象越来越严重,而从指令集的向下兼容出发,微处理器中的架构寄存器(也就是能够在指令中直接引用的寄存器)的数量很难得到大幅度的增加,这就要求微处理器的设计者必须使用其他的方式来解决这个问题。其中在现代处理机中使用最广泛的就是寄存器重命名(Register Renaming)技术。
寄存器重命名技术实际上就是通过对寄存器使用的动态调度来提高寄存器的利用率,将一些使用同一个寄存器来暂存或存储数据的指令所使用的寄存器分离开来。也可以认为寄存器重命名实际上是在程序执行过程中对寄存器进行再次的分配。在现代的微处理器中,由于微处理器能够实际拥有的寄存器的数量远远多于其指令集中所规定的架构寄存器的数量,而且各寄存器之间不再具有不可替代的独特性,这就允许微处理器中的控制电路通过将架构寄存器中的寄存器名映射到实际寄存器中的不同寄存器实体之中,从而解决与寄存器名字相关问题带来的对性能的影响。经过寄存器重命名过程后,程序中的寄存器名字相关基本上都能够被消除掉。
大量寄存器带来的好处绝不仅仅是通过寄存器重命名来消除名字相关现象。由于寄存器是整个微型计算机中访问速度最快的数据存储部件,大量寄存器和与之相关的优化策略必然能够带来数据供应上的进步。比如RISC处理器中常用的重叠寄存器窗口技术,在处理机中设置一个数量比较大的寄存器堆,并把它划分成很多个窗口。每个过程使用其中相邻的3个窗口和一个公共的窗口,而在这些窗口中有一个窗口是与前一个过程共用,还有一个窗口是与下一个过程共用的。与前一过程共用的窗口可以用来存放前一过程传送给本过程的参数,同时也存放本过程传送给前一过程的计算结果。同样,与下一过程共用窗口可以用来存放本过程传送给下一过程的参数和存放下一过程传送给本过程的计算结果。重叠寄存器窗口技术能够有效地减少过程调用带来的存储器访问动作,提高微处理器的性能。
6.改善指令与数据的供应
现代处理机的主频越来越高,速度越来越快,而存储器的速度提高远远落后于处理机。在今天,存储器的时延一般是几十到几百个处理机时钟周期。这种处理机和存储器之间的速度差距被称作处理机-存储器速度间距(Processor-Memory Speed Gap),简称存储器间距(Memory Gap)。存储器间距的出现和日益扩大,影响了处理机在程序执行过程中的指令和数据供应,对处理机的性能影响很大。所以,现代的处理机都非常重视对存储器间距的填补。
除了使用各种方式提高微处理器前端总线(FSB)的传输速率以改善微处理器的数据供应之外,填补存储器间距最有效的工具是高速缓存(Cache),尤其是片上高速缓存(On-Chip Cache)。具有较高命中率的Cache对改善处理机的指令与数据的供应能够起到很好的作用。自从RISC技术出现以来,指令Cache与数据Cache分离的设计已经成为现代处理机片上高速缓存的标准结构。由于指令Cache与数据Cache相分离,一方面减少了两者之间的相互影响,另一方面指令与数据采用不同的通路,提高了向处理机提供指令和数据的能力,并有利于提高Cache的命中率。
在高速缓存的基础上,更多的技术被用于改善指令与数据的供应。这些技术有:Cache Prefetch、Trace Cache、Write Buffer等。其中Cache Prefetch的基本思想是采用某种预测算法,根据当前被访问的Cache行预测即将被访问到的Cache行并将其调入Cache。根据不同的预测方法,Cache Prefetch被分为Always Prefetch、Prefetch on miss、Tagged Prefetch等。
Trace Cache(见图2-27)是一种用于指令Cache的技术。由于指令的特殊性,对指令Cache的访问也表现出与对数据Cache的访问不同的特点。在程序的执行过程中,大量的动态指令片断被经常访问,而这种访问经常是可预期的。这种可以预期的经常被访问的动态指令片断被称为指令踪迹(Trace),而以动态的指令踪迹而不是静态的指令为缓存对象的指令高速缓存技术就被称为Trace Cache。由于Trace Cache在一定程度上对指令的动态执行踪迹进行了记录和缓冲,在程序局部性的作用下,Trace Cache能够对处理机指令的供应做出一定的改善,但正像TLB无法代替常规的地址转换一样,Trace Cache也无法替代指令Cache,它只能是指令Cache的一种有益的补充。
Write Buffer是另外一种用来隐藏存储器时延的有效手段。所有要存入存储器中的数据并不直接存储到存储器中而是置于一段被称为写缓冲的高速缓冲区中,直到存储系统空闲或缓冲区满时再真正执行写入操作。Write Buffer能够有效地隐藏写操作时的存储器时延,在一定程度上填补了存储器间距,同时由于Write Buffer中的数据也经常被立刻读回到处理机核心中继续使用(尤其是对于临时数据,这种情况更加常见),Write Buffer对处理机读操作的时延隐藏也能起到一定的作用。
7.分支指令的双向预测执行
分支指令的双向预测执行指的是在遇到分支指令时,不论转移条件是“是”或“否”,处理机都在两个方向上同时执行。然后,在转移条件最后算出时,取用其中的一路(见图2-28)。这样可把预测执行失败所带来的延迟减到最少。
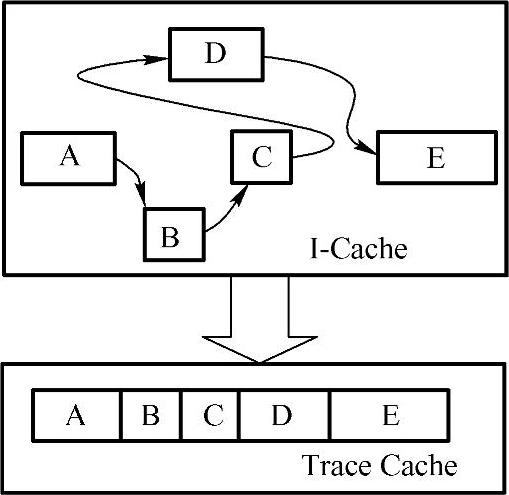
图2-27 Trace Cache与I-Cache
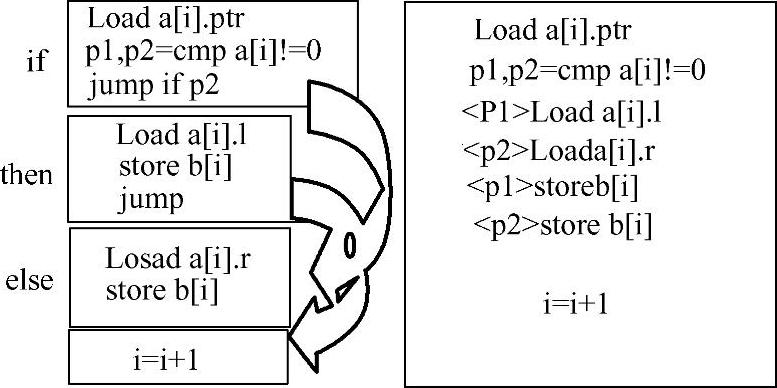
图2-28 Itanium对分支指令的处理
分支指令的双向预测执行是建立在处理机内部指令流水线的数目得到巨大提高的基础上的。由于处理机内部所具有的流水线数目已经能够满足对程序中多个不同分支的指令进行处理的需求,分支指令的双向预测执行才有可能对处理机的性能作出贡献。Intel的IA-64体系结构处理器Itanium中就采用了这种技术来实现对分支指令的高效处理。
8.针对特定应用领域,增加一些强有力的指令
对于一些特定的应用领域(如多媒体应用),其应用的特点需要一些特殊的指令支持,针对这些领域增加一些特定的指令能够在很大程度上提高处理机在该领域内的应用性能。如AMD的3D Now!技术、Intel的MMX技术和SSE/SSE2技术都是针对多媒体应用领域的新增指令的代表。以Intel Pentium Ⅲ的SSE(SIMD Stream Extension)为例,与Pentium Ⅱ相比较,Intel在Pentium Ⅲ中专门设计了长浮点寄存器堆(见图2-29a),可以一下子取出相当于数组的浮点数据流,实现针对多媒体应用的SIMD。在此基础上实现四个数据和另外四个数据同时执行浮点运算,或有选择地对其中一个或几个数据执行浮点运算(见图2-29b和图2-29c)。这也提高了浮点指令执行的并行性,从而有效地增加了速度。在Pentium 4的SSE2中这种设计得到了进一步的发挥。由于这些指令针对特定应用领域的特定模型进行了优化,对于这些应用领域(比如多媒体处理)的程序运行效率的改善是非常巨大的。
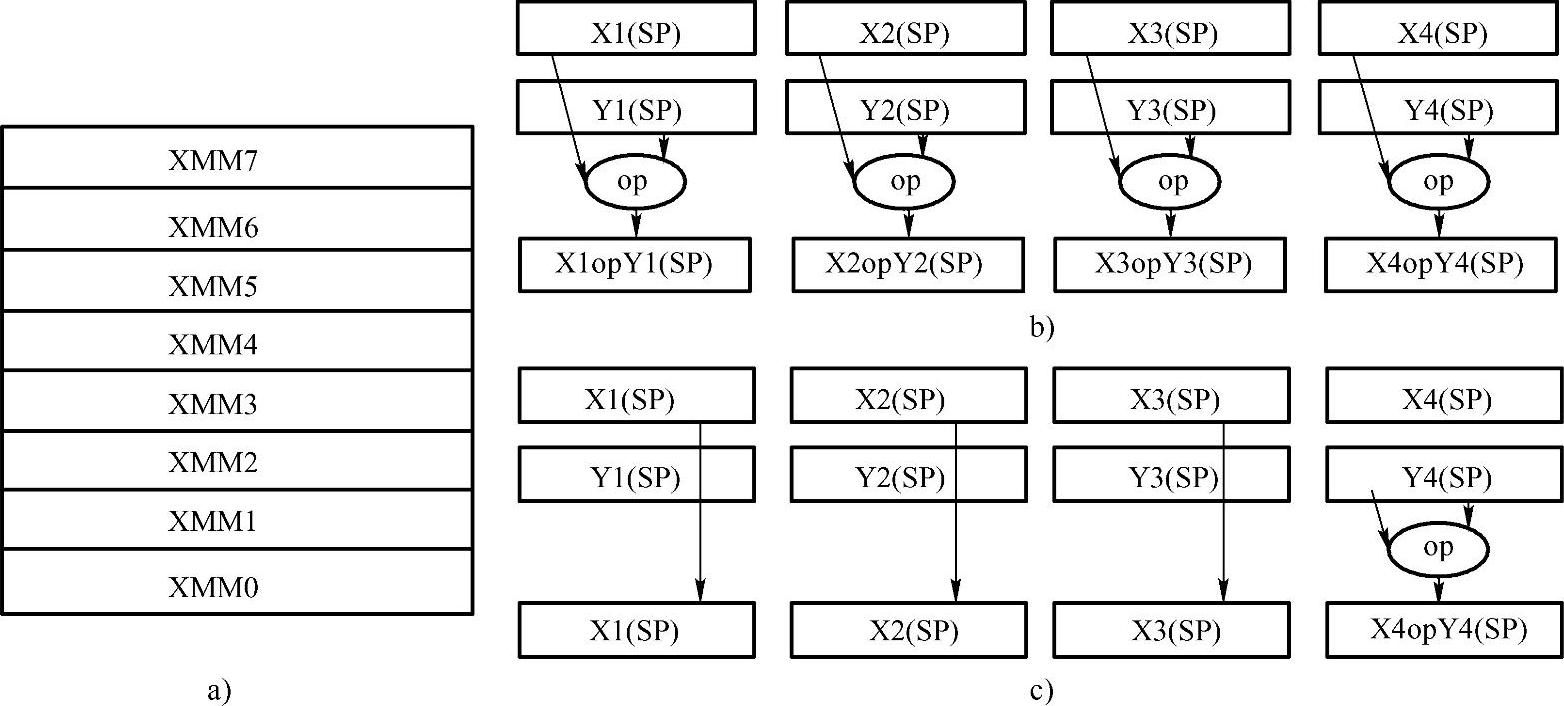
图2-29 Intel Pentium Ⅲ中的SSE技术
9.同时多线程处理和超线程技术
同时多线程处理机是多现场处理机的代表。它的核心思想是在多道工作程序负载产生的多个线程之间共享一个具有大量功能流水线的处理机核心。多线程处理机基于不同线程之间指令的无关性来提高处理机核心中大量功能流水线的利用率。通过此种方式,多线程处理机能够在提高单个处理机核心的吞吐能力的同时减少对功能流水线的浪费。在图2-30中,图a是传统的超流水结构的处理机,图b是纯粹的多线程超流水结构的处理机,而图c则是同时多线程结构的处理机。以不同颜色填充的格子,代表相应的功能部件被某个线程所使用,空格子代表该功能部件空闲。模拟结果表明,在8个线程共享一个具有10条流水线的SMT处理机的情况下,SMT处理机可以获得6.1~6.2的IPC值。

图2-30 各种不同结构的处理器对功能部件的使用
SMT在原理上是正确且简明的。但SMT有几个弱点:①SMT依赖于大量的工作线程,如果工作线程的数量下降,SMT的效率就有可能降低;②由于没有考虑对存储器间距的填补,在工作线程大量增加(如达到几十甚至几百)时,处理机核心从存储器获得数据和向存储器存储数据的能力将成为瓶颈且限制SMT效率的发挥。Intel在Pentium 4微处理器中引入了SMT技术,并将其命名为超线程技术(HyperThread),以取得更佳的处理器性能。在Intel最新的Core系列微处理器中该技术也被使用。
10.单片多处理机与多核技术
单片多处理机通过在一个芯片上集成多个快速处理机来加强对芯片上三极管的使用,并通过多个处理器之间的并发执行来获得更好的整体性能。斯坦福大学的CMP在一个芯片上实现4到16个快速微处理机,这些微处理机各自有其私有的一级高速缓存并共享一个大的二级高速缓存。它们可以被用来合作处理一个并行任务以提高该任务的完成速度或各自运行其独立的任务以提高处理机整体的吞吐能力。
CMP从传统的SMP结构基础上发展而来,其所能获得的性能增益是可以预期的。但由于从本质上来讲CMP是一种多处理机结构,其并行性属于处理机间的并行,或者称线程级并行,这就要求程序员必须对应用进行显式的优化以发挥CMP线程级并行的优势。另外由于CMP并没有对存储器数据的供应问题提出有效的解决方案,存储器间距问题可能会成为限制CMP得到更佳性能的瓶颈。
CMP与SMT在一些方面上有其相似之处:同样依赖于显式的线程间的并行性,同样面对存储器间距问题的困扰。其不同在于SMT的各负载线程的指令流共享着相同的流水线而CMP中不同的负载线程运行于不同的处理机核心上,这种区别致使CMP能够比SMT做得规模更大,能够同时执行的负载线程更多,但与SMT相比,CMP的流水线利用率相应要低一些。
随着微处理器主频提升越来越困难,Intel和AMD等微处理器的设计制造商将微处理器性能的提升从以提升主频为主的策略转变为提高微处理器的并行度为主的策略,其中被称作超线程的SMT技术和来自CMP的多核技术是最被寄予厚望的两种技术。多核技术来自于CMP,其主要差别在于多核技术中集成在一个微处理器中的不是多个完整的快速处理机,而是多个快速处理机的内核,这样更加易于实现。诸如Intel Core i7这样的高性能微处理器中已经同时使用了SMT和多核技术,从而获得更高的处理性能。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。