



从上节给出的变形效果图中可以看出,在其他条件相同的前提下,越精细的自适应网格,变形结果的失真也越小,但精细程度越高的自适应网格计算,所需的计算量也越大。在运动角色仿真应用中,不仅需要变形结果的真实性,还需要变形速度的高效性。
在本节的实验中,以Frog角色的图像为例,获得各步骤运行时间与自适应网格的精细度的关系。为更准确地统计精细程度的不同造成的时间差,使角色数量为100个,这样可以减小单个角色变形计算时的统计误差。在时间统计过程中,每次实验连续记录100帧的运行时间,并求其平均值。
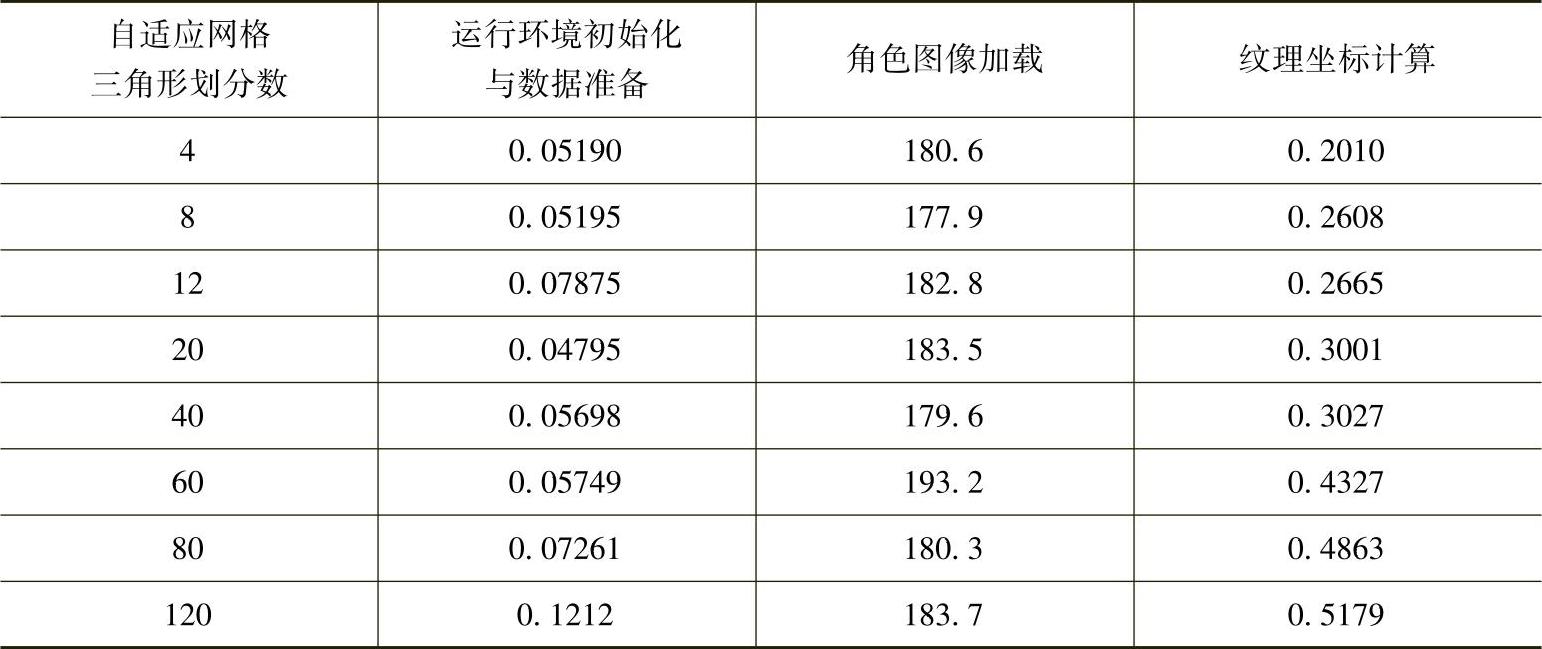
(1)在基于自适应网格的图像变形方法中,初始化步骤包含初始化运行环境、加载角色图像、准备简化骨骼数据、计算自适应网格的顶点纹理坐标等操作。在不同的网格精细程度,所需要的初始化各步骤所需时间见表3-3,由表中可以看出,随着网格三角形划分数的增多,纹理坐标的计算数量开始渐渐增加,这是由于三角形数量增多,顶点的纹理坐标计算量增加的缘故。
表3-3 初始化步骤所需时间 (单位:ms)
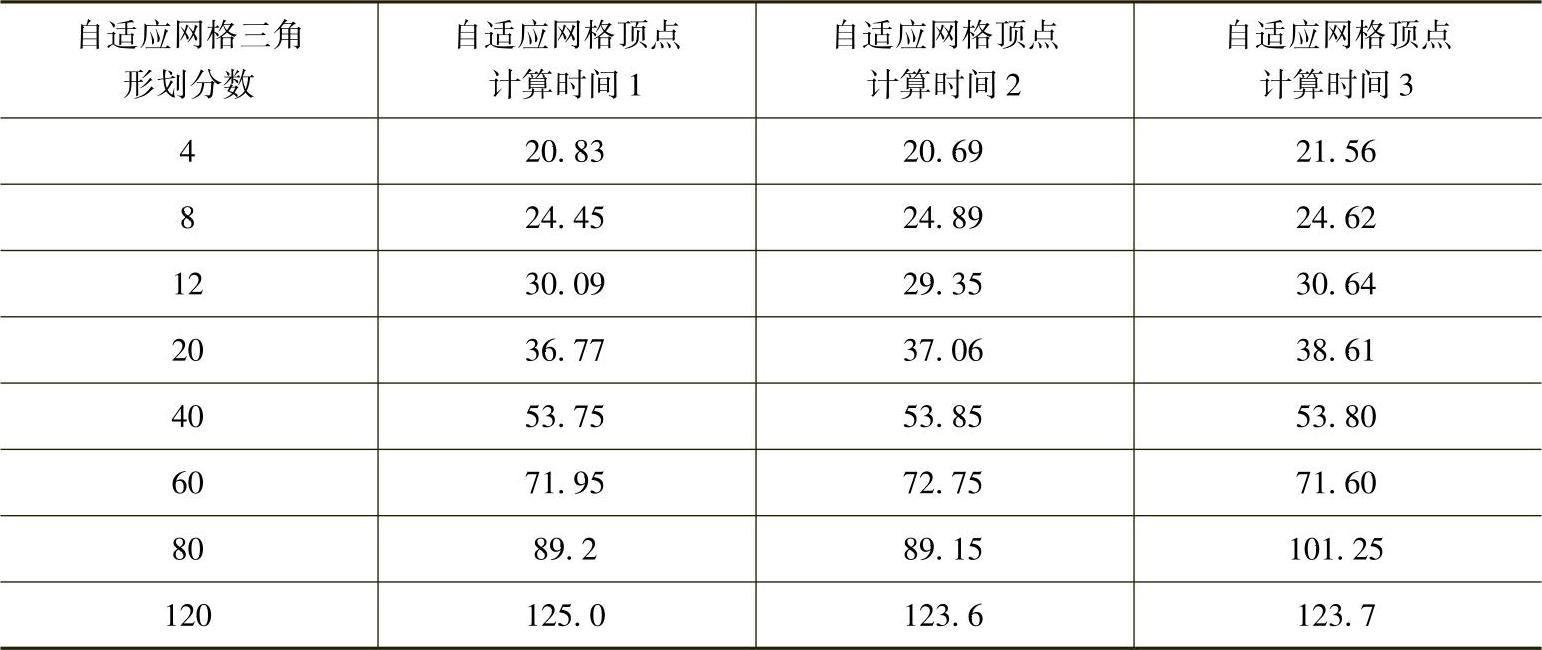
本节的实验对于本章提出的图像变形的硬件加速方法,分别实现了CPU、GPU二次渲染和GPU一次渲染三种加速算法,统计其运行时间并进行比较。对于网格精细度对变形过程中的各步骤运行时间影响,通过记录100个Frog角色变形过程中的数据,每次实验连续记录100帧,取其平均值。使用CPU计算100个Frog角色的变形,共做三组实验,各步骤运行时间见表3-4。
表3-4 传统CPU方法运行时间 (单位:ms)
根据表3-4中的数据所绘制的传统CPU方法变形计算时间与网格精细度的关系如图3-19所示。通过图中可以看出,网格顶点的计算时间随顶点增多而增加的趋势,CPU是直接计算方式,两者基本成正比关系(图中横轴为非等分尺)。
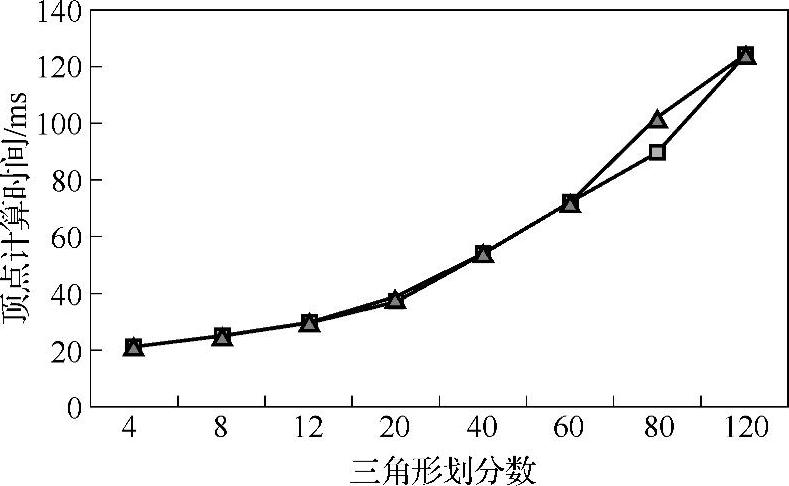
图3-19 CPU方法的运行时间与网格精细度关系图
(2)自适应网格可以使用GPGPU技术进行图形硬件加速,大大加快网格顶点的计算速度。当前主流的硬件配置下,单纯以浮点运算速度为指标,GPU的计算速度要远远高于CPU,但对于二次渲染方法来说,GPU每次计算过程分为初始化、计算和数据取回三部分,初始化操作包括设置渲染目标以及上传输入数据等,重置操作包括重置渲染目标,以及将计算结果数据从FBO缓冲区取回到内存等。
使用与CPU方法同样的运行条件,通过GPU二次渲染方法进行网格顶点加速计算,连续记录运行数据,所获得的GPU二次渲染方法变形过程中各步骤运行时间见表3-5。
表3-5 GPU二次渲染方法各步骤运行时间 (单位:ms)
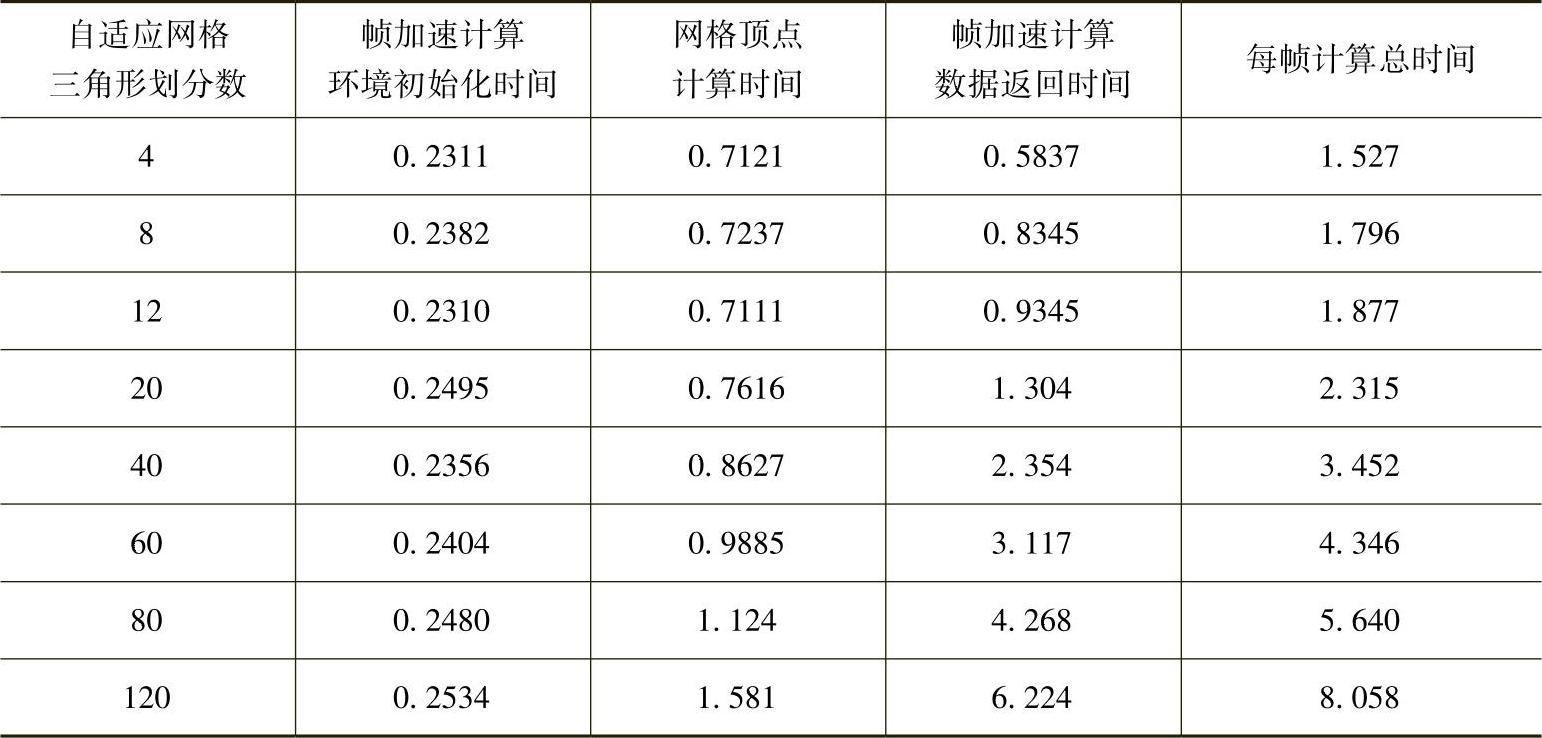
根据表3-5的数据绘制的GPU二次渲染法运行时间与网格精细度关系图如图3-20所示,通过图中可以看出,在GPU二次渲染方法中,环境初始化的时间一般会保持不变,而网格顶点计算时间会随自适应网络精细度增加而增加,数据取回时间也会随顶点数据的传输量增加而增加。(https://www.xing528.com)
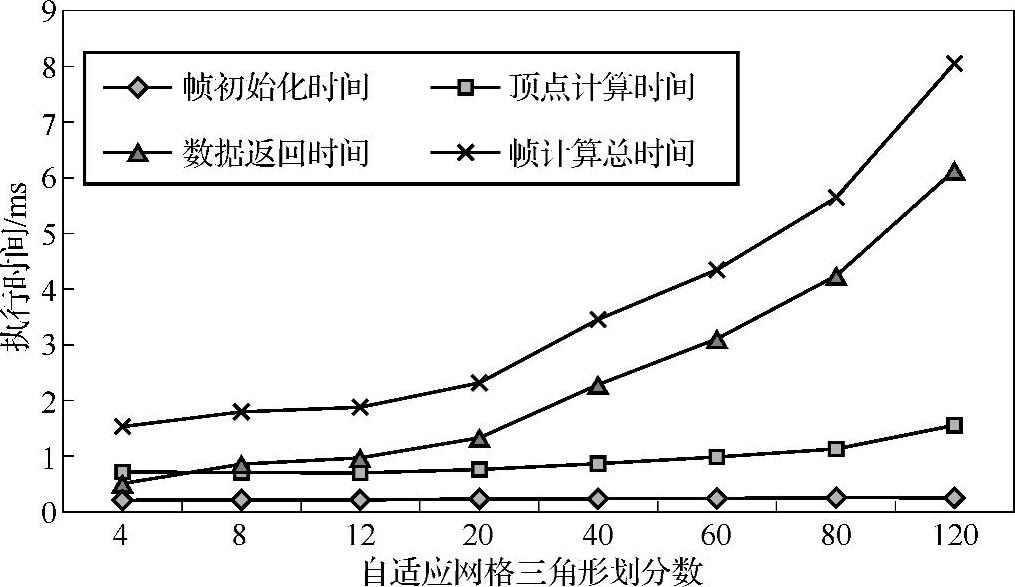
图3-20 GPU二次渲染法运行时间与网格精细度关系图
(3)在GPGPU加速方法中,二次渲染一般应用于复杂的计算过程,而一次渲染方法一般应用于较简单的几何属性计算。在图像变形过程中,GPGPU加速计算的是自适应网格的顶点坐标,可以使用一次渲染方法进行加速。
使用GPU一次渲染方法统计各步骤运行时间,运行环境与上面CPU、GPU二次渲染条件相同,使用100个Frog角色图像同时进行变形计算,所获得的在不同网格精细程度下的运行时间数据见表3-6。
表3-6 GPU一次渲染方法运行时间 (单位:ms)
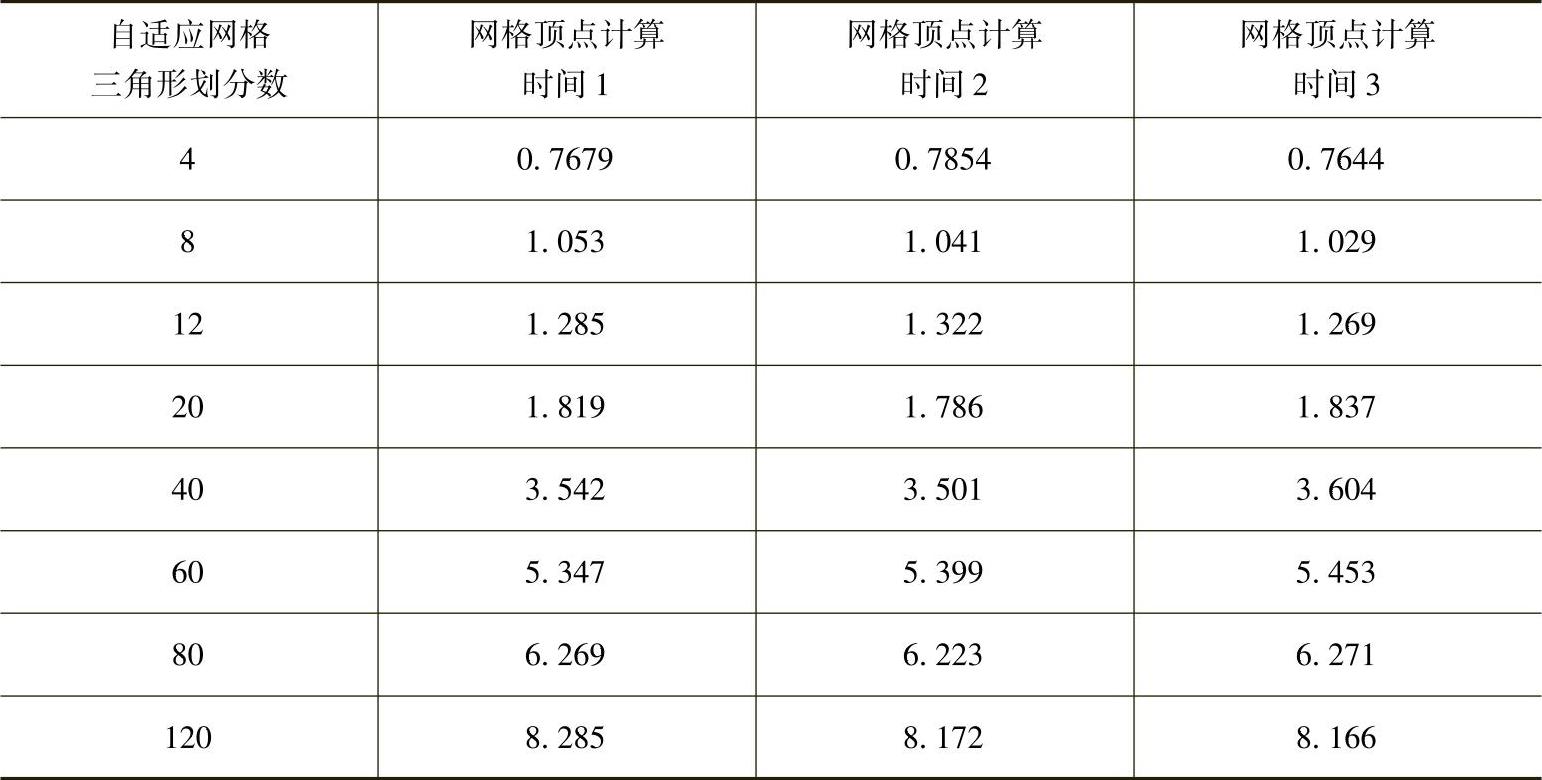
根据表3-6中的数据所绘制的GPU一次渲染方法运行时间与网格精细度的关系如图3-21所示,通过图中可以看出,随着自适应网格精细程度的提高,变形计算量增大,从而造成GPU一次渲染法加速计算的时间变长。
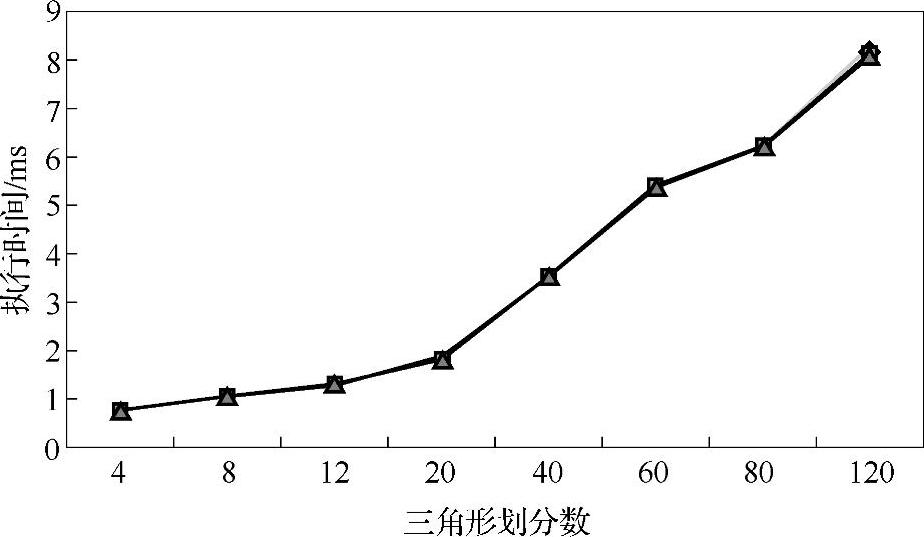
图3-21 GPU一次渲染方法运行时间与网格精细度关系图
(4)本节的变形算法包括传统CPU计算、GPU二次渲染方法加速和GPU一次渲染方法加速三种,分别统计网格精细度对各种方法的运行时间影响。这三种执行方法所需的变形计算总时间随网格精细程度的变化如图3-22所示,从图中可以看出,GPU相比CPU可以提供显著的加速作用,验证了针对二维角色变形的硬件加速算法的有效性。
不同网格精细度的GPU二次渲染与GPU一次渲染方法的对比如图3-23所示,图中可以看出两者的计算时间是相似的,造成这种现象的原因主要有两点:一方面,GPU二次渲染所需要上传的数据少,回传的数据量多,而GPU一次渲染所需要上传的数据量多,GPU二次渲染的回传数据量应该等于GPU一次渲染的上传数据量,都为自适应网格的顶点坐标数据量;另一方面,GPU二次渲染避免重复计算,减少了计算量,而GPU一次渲染则避免了重复设置/还原渲染目标。
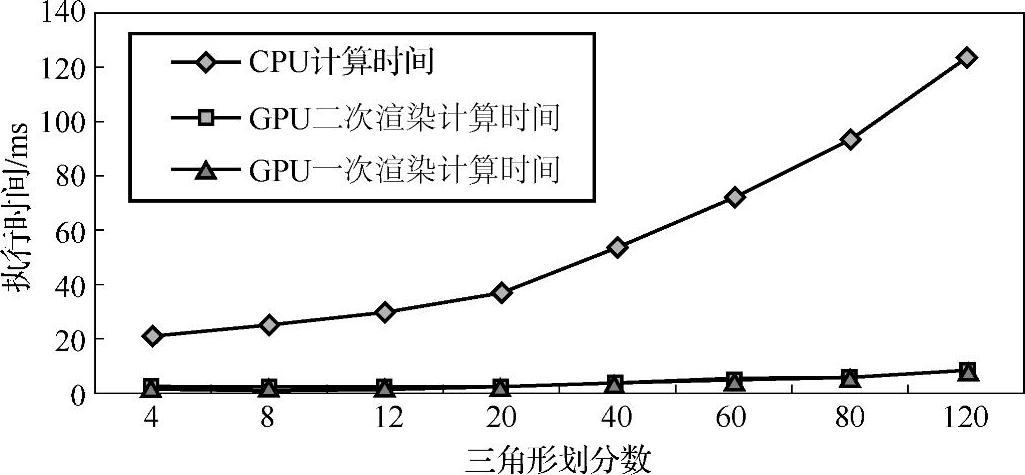
图3-22 不同网格精细度的CPU/GPU变形计算时间比较
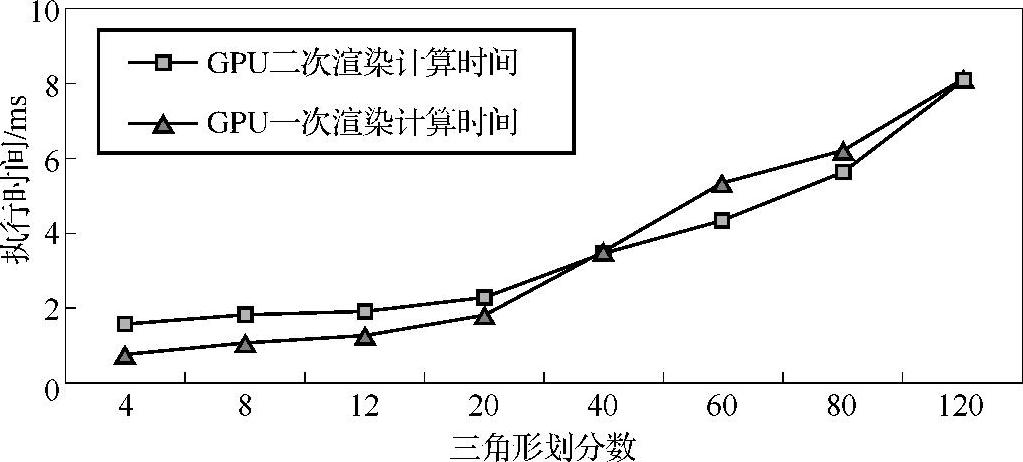
图3-23 不同网格精细度的GPU方法的计算时间比较
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。