



按照上述定义的功能,我们定义堆管理器对象,作为堆功能的对外接口:

其中,__HEAP_OBJECT是一个堆对象,该对象定义如下:

在堆管理器对象提供的接口中,CreateHeap用于创建一个堆对象,dwInitSize是初始的缓冲池的大小,即在创建堆的时候,从系统中申请多少内存,作为堆的内存池。DestroyHeap用于销毁一个堆对象,而DestroyAllHeap函数,则是销毁当前线程的所有堆对象。这个操作一般是在线程运行结束后,被操作系统调用,用来销毁线程创建的堆对象的。顾名思义,HeapAlloc和HeapFree两个接口用于完成内存的分配和释放,它们除了接受一个DWORD类型的参数,用于指明需要申请的内存数量,还接受一个堆对象指针参数,这个堆对象指针指明了从哪个堆中分配内存。在当前的实现中,HeapAlloc只能从当前线程(调用这个函数的线程)的堆对象中分配内存。
堆对象管理器仅仅是一个操作接口,是为了采用面向对象的实现思路而引入的。
按照堆的功能描述,一个线程可能有多个堆,而一个堆只能属于一个线程。因此,必须有一种机制,可以管理多个堆的情况。在当前的实现中,修改了__KERNEL_THREAD_OBJECT对象(核心线程对象,用于保存线程的特定信息,每个核心线程对应这样一个对象),在该对象的定义中,添加了两个变量:lpHeapObject和lpDefaultHeap,这两个变量的类型,都是LPVOID,之所以这样安排,是为了不把堆对象的特定数据结构定义,引入核心线程的实现中,这样可保持代码的清晰和独立。其中,第一个变量指向一个堆对象链表,该链表把当前线程中的所有堆对象连接在了一起。在CreateHeap函数被调用的时候,该函数就创建一个堆对象,并插入该堆对象链表。第二个变量lpDefaultHeap,则指向了一个缺省的堆对象,所谓的缺省堆对象,就是malloc函数和free函数所操作的堆对象。
在当前的实现中,采用空闲链表算法,来完成堆对内存池的管理。所谓空闲链表,指的是把所有空闲的内存块,连接在一起,作为一个统一的空闲内存池,在分配内存的时候,遍历整个空闲链表,选择一块合适的空闲内存块,返回给调用者,并把该空闲内存块从空闲链表中删除。在释放内存的时候,释放函数把释放的内存块重新插入空闲链表。在操作系统核心内存池的管理中,也使用了空闲链表算法对任意尺寸内存池进行管理。这样,每个堆对象需要维护一个空闲链表(FreeBlockHeader变量就是该空闲链表的头指针),用于完成空闲内存块的管理。开始的时候(堆被创建的时候),堆对象申请的初始内存池,作为空闲链表中的第一个对象(也是唯一一个空闲块)被插入空闲链表,随着内存分配的持续,空闲链表中的元素(空闲块)数量会增加或减少。
堆对象除了维护一个空闲链表外,还维护一个虚拟区域对象链表,每个虚拟区域,实际上就是系统线性地址空间中的一块连续区域,而且这块区域已经与实际的物理内存完成了映射(CPU MMU的内存管理数据结构已经被成功填充)。虚拟区域列表实际上就是堆对象的内存池,堆对象初始化的时候,会申请一块特定大小的虚拟内存区域,作为内存池,随着分配的持续,申请的虚拟内存区域可能已经分配完了,或者用户请求的内存大小,已经超过了剩余的可分配的内存空间,这时候,堆对象会再次调用VirtualAlloc函数,申请额外的虚拟区域对象。申请成功后,将把该虚拟区域对象插入虚拟区域列表。在堆对象的定义(__HEAP_OBJECT)中,lpVirtualArea就是虚拟区域链表的头指针,需要注意的是,虚拟区域链表是一个单向链表,每个链表元素是一个__VIRTUAL_AREA_NODE结构,该结构定义如下:

可见,该结构的定义非常简单,仅仅保留了虚拟区域的起始地址,以及该虚拟区域的大小。
按照上述实现方式,一个核心线程的堆对象组成一个链表,其中,每个堆对象中,又维护两个链表:空闲块链表(双向)和虚拟区域链表(单向),如图5-24所示。
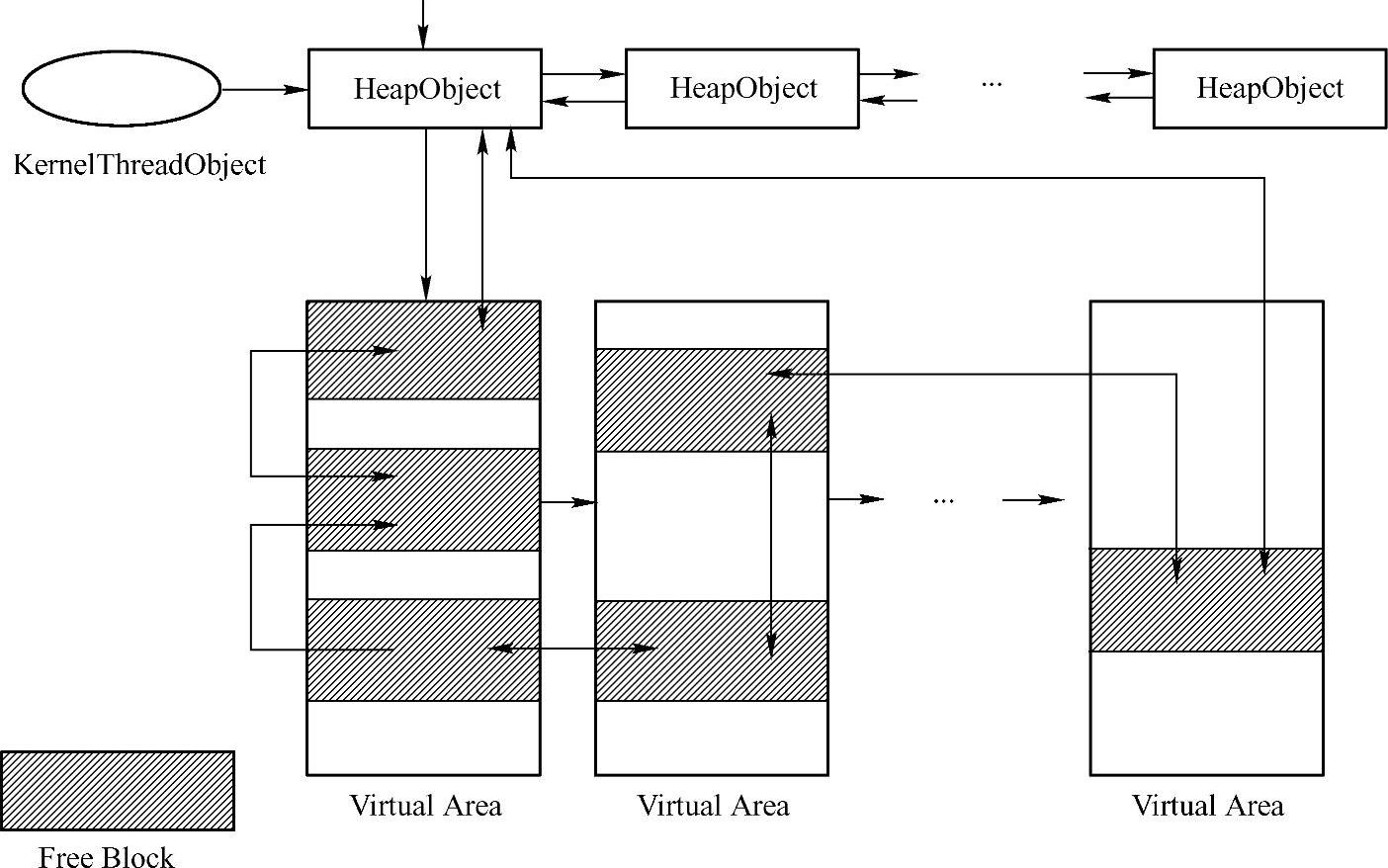
图5-24 线程本地堆的整体数据结构
需要注意的是,空闲链表的空闲块,与虚拟区域链表中的区域是重合的,这很容易理解,因为空闲块是从虚拟区域中分配的,虚拟区域作为空闲块的原始资源。
空闲链表算法比较简单,基本思路就是把系统中的所有空闲内存块,通过链表的方式串连在一起,开始的时候,空闲链表中只有一块空闲块,那就是最初申请的虚拟区域。对于内存分配操作,该算法做如下操作:
(1)从空闲链表头部开始,依次检查空闲链表中的空闲块,大小是否满足要求的尺寸。
(2)若能够找到这样的一块空闲块,则判断该空闲块的大小,是否应该拆分。在空闲内存块比用户的申请尺寸大不太多(当前情况下,定义为16B)的情况下,就把整个空闲块分配给用户,否则把找到的空闲块进行拆分,把其中剩余的部分再次插入空闲链表,然后把拆分出来的另外一块,分配给用户。
(3)若无法找到满足要求的空闲块,则再次调用VirtualAlloc函数,从系统空间中申请一块虚拟区域,然后把这块虚拟区域当作空闲块对待,从中摘取头部的一部分,返回用户,然后把剩余的部分(若用户申请的内存足够大,则整个虚拟区域直接返回用户),当作一块空闲块,插入空闲链表。当然,若调用VirtualAlloc失败,则会返回用户一个NULL指针,以指明本次操作失败。
可以看出,上述空闲链表采用的是首次适应算法。所谓首次适应算法,即从开始遍历空闲链表,只要找到一块尺寸大于要求的空闲块,就停止继续查找,直接把这块内存块返回给用户。这样做的优点是,实现起来相对方便,且效率高,当然,首次适应算法也有一个缺点,就是随着分配的深入,空闲链表中可能出现大量的“碎片”(尺寸很小的空闲块),这样一旦遇到申请内存数量很大的请求,就可能失败。但这样的分析只是在理论上的,实际上,许多成熟的计算机操作系统,都采用了首次适应算法,工作得都很好。而且在Hello China的实现中,对于堆,只是为了满足少量内存的申请而实现的,对于大块内存的分配,可直接调用VirtualAlloc函数来分配,这样就可避免首次适应算法带来的问题。(https://www.xing528.com)
对于释放操作,在当前的实现中分两步进行:
(1)把释放的内存块,插入空闲链表。
(2)调用一个合并操作,把空闲链表中的相互邻接的小空闲块合并成一个大的空闲块。
其中,第一个步骤比较简单,只需要根据待释放内存的物理地址,找到该块空闲内存块的控制头,然后把该空闲内存块插入空闲链表即可。对于空闲块的合并操作,当前的实现中,是以虚拟区域为单位进行操作的。因为一个堆对象,可能申请了多块虚拟内存区域(这些区域被连接成单向链表),而一块空闲内存块,只属于一块虚拟区域,这样在释放内存的时候,只需根据待释放的内存地址,找到该空闲内存块所属的虚拟区域,然后从虚拟区域的开头,来开始空闲块的合并工作。需要注意的是,对于空闲块的合并,是按照地址相邻(而不是空闲块在空闲链表中相邻,两块空闲块,其在内存中的位置收尾相接,但在空闲链表中的位置可能不会收尾相接)进行的,算法如下:
(1)以虚拟区域的第一块内存块为起始(虚拟区域的起始地址,对应于该虚拟区域所包含的第一块内存块的控制头地址),作为当前内存块,判断该块是否空闲(通过判断控制头的一个标志字段),若不空闲,则把当前内存块更新为与当前内存块相邻接(地址邻接)的下一块内存块,这可以通过在当前内存块指针上,增加当前内存块的大小(可从控制头中获取)来实现。
(2)判断当前内存块的相邻内存块是否空闲,若不空闲,则更新当前内存块为相邻内存块,并从上述步骤(1)重新开始操作。
(3)若当前内存块的相邻内存块空闲,则进行一个合并动作,合并操作比较简单,只需要把当前内存块的相邻内存块从空闲链表中删除,然后在当前内存块的“大小”字段上,增加当前相邻内存块的大小即可(实际上还需要增加相邻内存块的控制头大小),如图5-25所示。
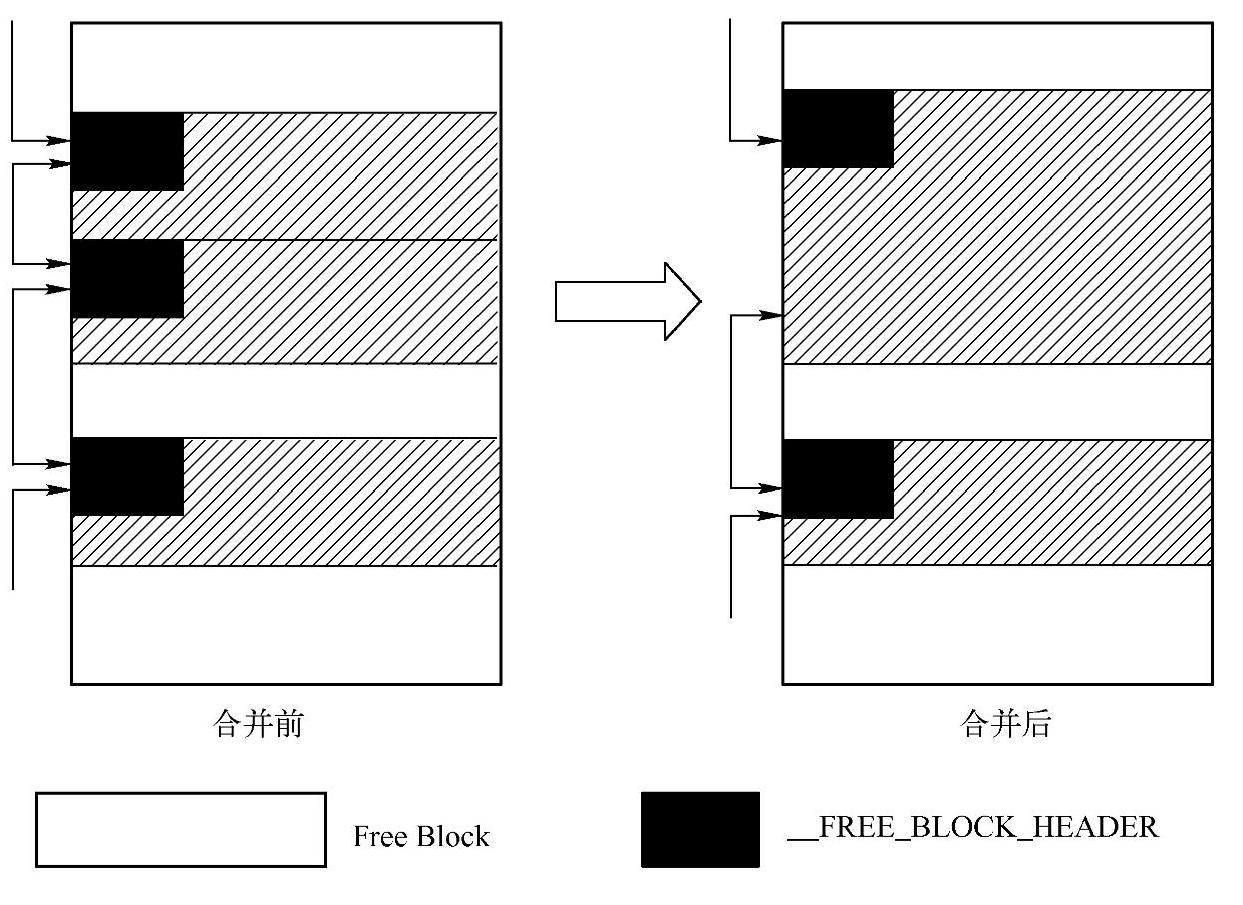
图5-25 空闲内存块的合并操作
(4)重复上述动作,直到当前内存块地址到达虚拟区域的尾部(这时,对于当前虚拟区域的合并操作完成)。
把对空闲块的合并操作限制在一个虚拟区域内部,可以提高效率,因为无需遍历整个空闲链表。
从上述描述中可以看出,在当前Hello China对堆的实现中,由于采用了空闲链表算法,对内存的分配和回收,时间是无法预测的,在理想的情况下,可能很快就能完成内存的分配和释放,但如果空闲链表很长,而且“碎片”很多,则分配和回收操作都可能耗费较长的时间。因此,基于这种实现,对于一些对时间要求非常严格的应用,可能无法满足要求,但对于大多数非“硬实时”的应用,这样的实现是足够的。若程序员面对的是对时间要求十分苛刻的硬实时系统,则可考虑实现自己的内存分配器,这时候,只需要调用VirtualAlloc函数,事先获得一个内存池,然后在这个内存池的基础上,实现能够满足要求的分配算法。
对于空闲块的管理,是通过一个空闲控制块结构来进行的,该结构定义如下:

在该结构中,记录了空闲块的尺寸,并提供了一个标志字段,来标志当前块的状态,比如空闲或占用。若当前块的状态为占用,则说明当前内存块已经分配给了用户应用程序,不在空闲链表之中。lpPrev和lpNext指针把空闲块连接在双向空闲链表中。
对于每个内存块,都预留开始的16B,作为控制头,如图5-26所示。
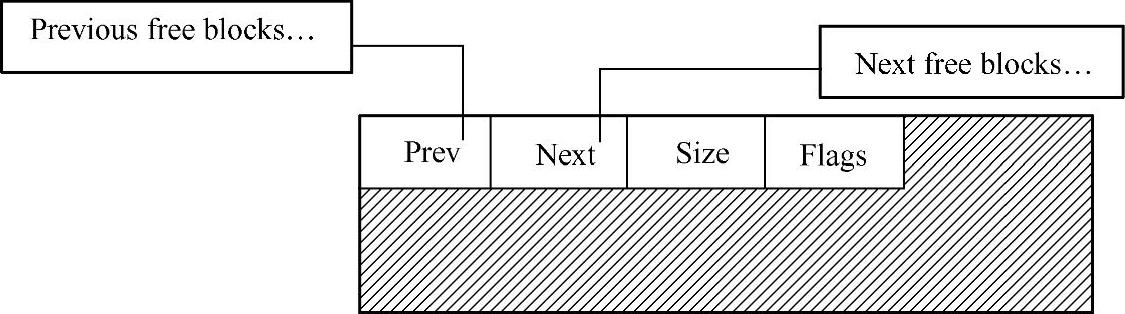
图5-26 空闲内存块的控制头结构及位置
这样,在进行内存分配的时候,只需要从空闲链表中找到一块合适的空闲块,这时候的块指针,指向的是控制头基地址,在返回用户的时候,只需要在控制头地址基础上,增加16(控制头结构长度)即可,当然,还需要修改内存块的标记字段。在释放内存的时候,根据用户提供的地址,减少16B,就可获得控制头的基地址,然后把控制头中的标记字段修改为空闲,并插入空闲链表即可。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。