



CreateKernelThread函数完成线程的创建功能,该函数执行下列动作。
(1)调用CreateObject(ObjectManager提供)函数,创建一个核心线程对象。
(2)初始化该核心线程对象。
(3)创建线程堆栈,并初始化堆栈。
(4)把核心线程对象插入就绪队列(初始状态为就绪)或挂起队列(初始状态为挂起)。
下面是该函数的实现代码,为了方便阅读,我们分段列举解释。


上述代码主要是检查创建线程的初始状态(也可以认为是参数合法性检查),本函数只创建状态为READY(就绪)或SUSPENDED(挂起)的线程,所有以其他值调用该函数的尝试都会失败。

上述代码调用ObjectManager提供的CreateObject函数创建核心线程对象。在目前的实现中,将核心线程对象也归纳到ObjectManager的管理框架中,即系统中创建的任何核心线程对象都会被ObjectManager记录,这样便于管理。

上述代码完成线程堆栈的创建。线程的堆栈实际上就是一块物理内存,对于堆栈的大小(dwStackSize),用户可以根据需要自行指定(在CreateKernelThread函数调用中通过参数传递),也可以不指定。若用户不指定堆栈大小(dwStackSize参数设为0),则系统创建一个缺省大小(DEFAULT_STACK_SIZE,目前定义为16KB)的堆栈,否则根据用户指定的大小创建。但若用户指定的堆栈尺寸太小(小于KMEM_MIN_ALLOCATE_BLOCK),则系统会采用KMEM_MIN_ALLOCATE_BLOCK代替用户指定的值。
若堆栈创建失败(内存申请失败),则CreateKernelThread函数会以失败告终。

上述代码完成核心线程对象的部分初始化(有一些成员,需要进一步初始化),包括设置线程的ID、优先级、当前状态等。需要注意的是,对线程核心对象中lpInitStackPointer的设置,不是设置为堆栈的起始地址,而是设置为堆栈的终止地址,因为堆栈是从高地址到低地址增长的。

上面这段代码设置了核心线程的线程名。在当前的实现中,核心线程的线程名字最大不能超过16B,因此为了安全起见,不使用诸如strcpy等函数,而是采取最“笨拙”也是最安全的逐个字节复制的方式来实现。

InitKernelThreadContext函数初始化了核心线程对象的硬件上下文,具体的初始化方法,本章后续会介绍。(https://www.xing528.com)
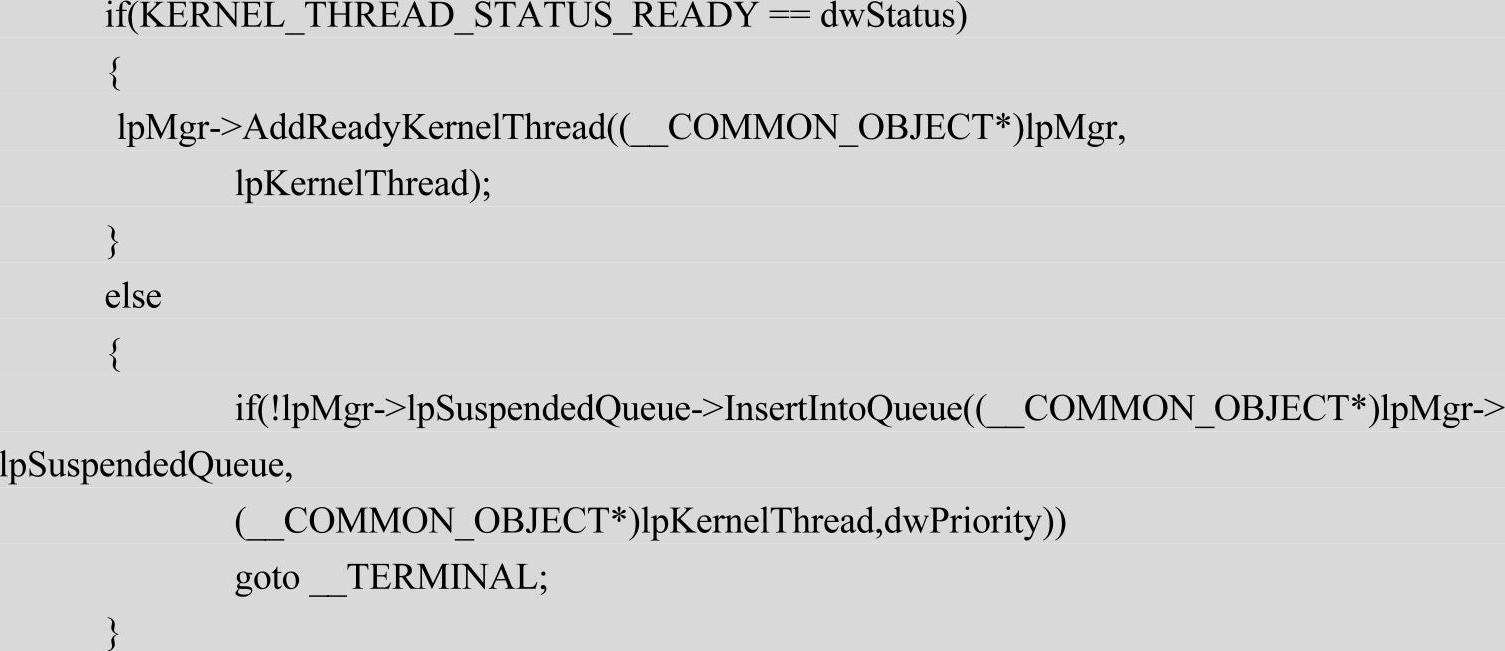
上述代码根据创建的线程的状态(READY或SUSPENDED),把线程插入对应的队列。若线程的初始状态为READY,CreateKernelThread函数会把线程加入就绪队列数组。这样一旦下一个调度时机(时钟中断或系统调用发生)到达,该线程就可能会被调度执行(根据线程的优先级确定)。若线程的初始状态为SUSPENDED,则该线程会被放入lpSuspendedQueue,除非该线程被手工恢复(ResumeKernelThread),否则不会被调度。

上述代码中最主要的一个地方,就是调用了CallThreadHook函数。在Hello China V1.75的实现中,采用了一种回调机制,用户可自行创建一个函数,然后注册到系统(实际上是核心线程管理器对象)中。当核心线程被创建、被销毁、被换出CPU、被调入CPU时,将会调用这个回调函数,从而完成一些系统级的任务。最典型的一个应用就是线程运行时间的统计功能。可创建一个回调函数,在线程被调度到CPU开始执行的时候,记录下当时的系统时间戳。当线程被调度出CPU的时候,再次记录当时的时间戳。这样对比两个时间戳,就可得到线程本次被调度的执行时间。这样累加起来,就可以得到线程的完整执行时间。具体的回调机制的实现,在本书后面将会讲到。
最后,CreateKernelThread如果执行失败,则必须进行一些资源清除工作,比如释放线程的堆栈、释放创建的核心线程对象等。如果执行成功,则直接返回创建成功的核心线程对象指针即可。
相信读者对核心线程的创建过程已经有一个基本的了解了。在上面的描述中,曾提到CreateKernelThread函数通过调用InitKernelThreadContext函数,完成了核心线程上下文的初始化。核心线程上下文是与CPU紧密相关的一些硬件信息的集合,下面详细讲解InitKernelThreadContext函数的实现。先看代码(为了描述简便,代码有所精简):

其中,PUSH是预定义的一个宏,代码如下:

这个宏模拟了一个堆栈PUSH动作,首先把堆栈指针减去1(实际上是减去四个字节),然后把val存放在栈顶。
InitKernelThreadContext函数通过PUSH宏,建立了如图4-5所示的堆栈框架。
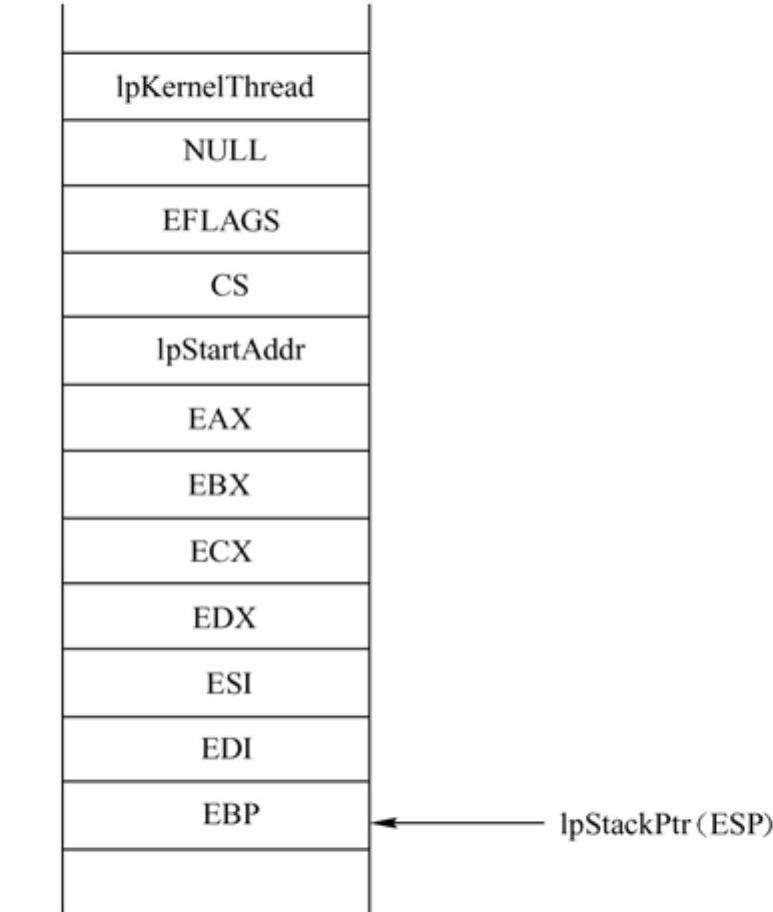
图4-5 新创建的核心线程的堆栈框架
其中,lpStartAddr就是Hello China提供的核心线程封装函数(KernelThreadWrapper)。堆栈框架建立完成之后,InitKernelThreadContext就把lpStackPtr赋值给当前核心线程对象的lpKernelThreadContext变量。待该核心线程得到调度后,通过lpKernelThreadContext变量,就可得到上述堆栈框架的栈顶指针,然后依次恢复通用寄存器,并执行iretd指令,就可跳转到lpStartAddr位置处(即KernelThreadWrapper函数处,这是所有核心线程的统一入口点)。KernelThreadWrapper函数的原型如下:

由于KernelThreadWrapper是一个函数,接受一个核心线程对象作为其参数,因此我们在开始的时候,压入了当前核心线程对象的指针和一个NULL值,以模拟一个call指令执行过程。如果读者对iretd和call指令的执行过程不是很清楚,那么可能会感到迷惑。在此再进一步解释一下这个过程。
InitKernelThreadContext函数把lpStackPtr赋值给核心线程对象的上下文指针之后,核心线程创建的工作就结束了。在核心线程得到调度的时候,调度程序会恢复线程的硬件上下文信息。恢复的方法就是把CPU的ESP寄存器(堆栈指针)替换为核心线程对象的硬件上下文指针(lpKernelThreadContext),然后依次恢复EAX到EBP等几个通用寄存器,执行iretd指令。iretd指令的执行过程是,从堆栈中依次恢复EIP寄存器、EFlags寄存器和CS寄存器,然后接着执行。按照上述过程,在核心线程完成创建,第一次被调度执行的时候,是从KernelThreadWrapper函数处开始执行的,即iretd指令执行完成后,CPU的执行线索就跳转到了KernelThreadWrapper处。注意,这里不是通过call指令跳到这个函数处的,而是通过iretd指令。但KernelThreadWrapper函数却不知道这些,它依然会按照传统的方式(即认为是被call指令调用)去访问函数的参数,即核心线程对象指针(lpKernelThread)。
而传统方式对函数参数的访问方法,则认为堆栈框架是通过call指令构建的,即首先压入函数参数,然后压入函数调用者调用KernelThreadWrapper时的指令偏移(返回地址)。因此我们必须模拟这种堆栈框架,以适应KernelThreadWrapper函数本身的要求。模拟方法就是,首先把该函数的参数(lpKernelThread)压入堆栈,然后压入4个空字节模拟返回地址。这样在KernelThreadWrapper函数看来,就是一个通过call指令建立起来的堆栈框架,于是就可正常访问lpKernelThread参数。
需要注意的是,在堆栈中压入一个“空”双字(4字节),并不会导致异常的发生。因为这仅仅是为了迎合call指令的动作而完成的一个虚拟操作。实际上,KernelThreadWrapper函数永远不会返回,在KernelThreadWrapper函数的结尾处,已经把当前的核心线程对象从就绪队列中删除,这样该函数就不可能被再次调度,从而没有返回的机会,该“伪位置”就不可能被访问。详细信息请参考4.2.6节。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。