



1.实验目的
了解全文搜索引擎的工作原理,并初步掌握全文搜索引擎的实现方法,培养开发实用的搜索应用程序的能力。
2.实验设备
(1)硬件
● PC1台。
(2)软件
● Tomcat服务软件1套。
● MySQL数据库1套。
● 全文搜索引擎DBTSearch1套。
● 组织机构数据库OrgInfo1套。
3.实验原理
全文搜索引擎DBTSearch的系统框架主要包括系统核心层和应用层,系统构架如图5-7所示。
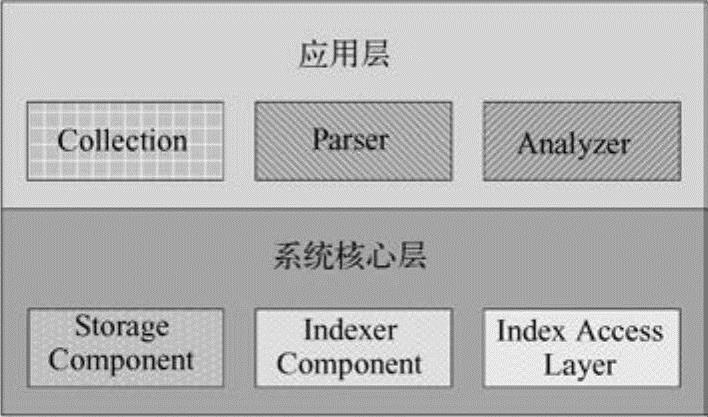
图5-7 DBTSearch系统架构
系统核心层包括存储组件(Storage Component)、索引组件(Indexer Component)和索引访问组件(Index Access Layer)3个部分。存储组件实现索引的压缩存储,存储的位置可以是本地磁盘,内存或机群等,具体的存储位置和方案对于上面的索引层是透明的。索引组件实现文档倒排,这一层又可以扩展多种不同数据类型字段的索引器。例如,对于中文文本,可以采用Word Indexer;而对于和中文文本大不相同的URL,则可以采用URL Indexer,这个索引器利用了URL的特征能实现更高效的索引,用户也可以扩展自己的索引器。索引访问组件架构在索引组件之上,实现对索引的读写、检索功能等。这一层包含3部分:索引检索(Index Searcher)、索引生成(Index Writer)和索引读取(Index Reader)。索引检索组件检索已经创建好的索引;索引生成组件输入原始文档,生成倒排索引;索引读组件读取索引的相关信息,包括索引文档遍历、索引词检索等。
在系统核心层之上是应用层,包含文档集抽象组件(Collection)、文档格式解析器组件(Parser)和文档内容分析器组件(Analyzer)组件。文档集抽象组件从待索引的文档集中抽取出单个文档,输入到解析器组件进行文档格式解析;分析器组件则对解析器解析后的文档内容进行分析(分词、去停用词和词根还原等),将文本的字符串序列转换成数字编号的词(Term ID)序列,输入到系统核心部分进行索引。分析器组件同时也应用在检索部分,将检索词转换成词编号。
核心层的存储组件、索引组件以及应用层的文档集抽象组件、文档格式解析器组件、文档内容分析器组件都可以单独扩展、升级或替换。其中,文档格式解析器组件和文档内容分析器组件可以通过COM插件扩展。
(1)索引算法及实现
索引采用目前广泛使用的向量空间模型(Vector Space Model)和TF_IDF标引策略。主要步骤是对文本记录进行分词、去除停用词、词根还原(Stemming)等简单的预处理之后,对文本建立倒排表。主文档中的每一个词(预处理之后保留的)都在倒排表中有对应的入口词项。每个入口词都指向一个属性项链表,链表中每一项记录该入口词在主文档中的出现情况,如偏移量、(英文)大小写等信息。建立索引后,对索引文件进行压缩优化,然后进行保存。上述索引过程的实现代码如下:

(2)检索算法及实现
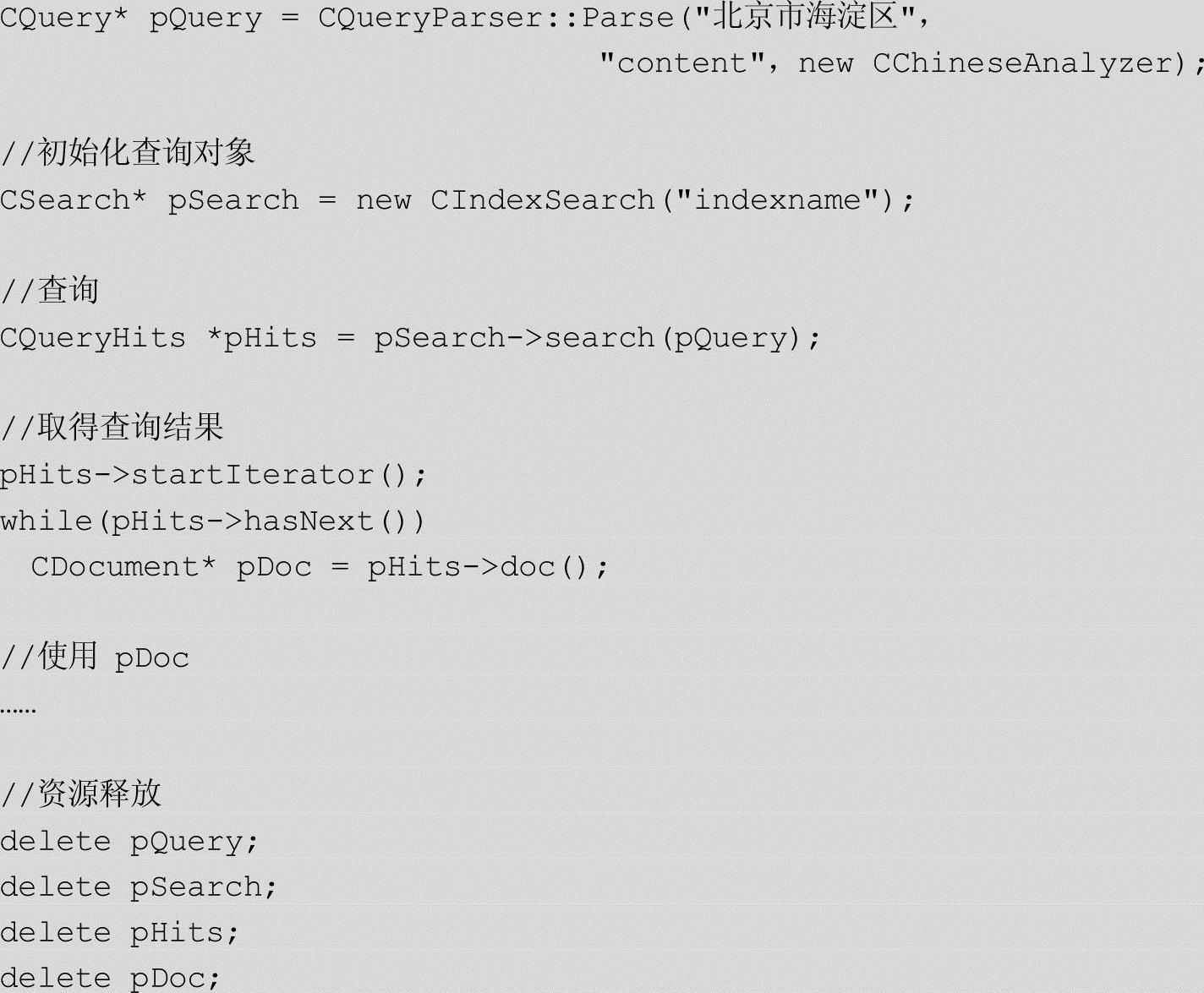
检索过程是根据用户的查询请求,到页面库/知识库中查找相关记录,再把查询结果返还给用户。在返还的结果中,要根据记录的相关度和重要性对结果进行排序,把质量最好的结果排在检索界面的前面。系统首先对查询请求进行分析,包括分词、去除停用词、词根还原等预处理过程,然后在索引文件中找到相关的结果记录,然后进行综合性的排序和整合。上述检索过程的实现代码如下:
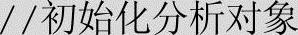
4.实验内容
了解搜索引擎的基本知识,包括索引的建立、搜索的过程。掌握MySQL数据库的安装与运行、搜索引擎的搭建、搜索结果的检查。
5.实验步骤
1)启动MySQL数据库,并使组织机构数据库OrgInfo顺利运行。
2)词表建立(该步骤可忽略,只针对定制需求,可以直接采用原有的PDAT文件。)
命令格式:
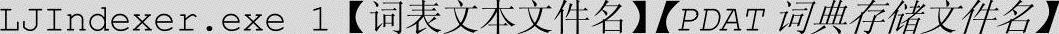
例如:
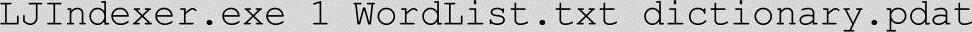
词表每行即一个词项。
注:斜体字为输出文件名,下同。
3)词表数据导入,便于调试输出(该步骤可忽略,只针对定制需求,可以直接采用原有的WordList文件)
命令格式:
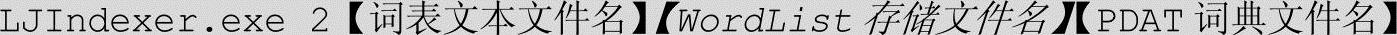
4)数据库字段信息列表导入。
命令格式:

FieldInfo.txt内容示例见表5-3。
表5-3 FieldInfo.txt内容示例

相关内容说明如下:
● 字段名称为数据库中的实际字段名称,必须一致,否则无法访问数据库。(https://www.xing528.com)
● 索引名称为后续检索的字段名称,必须和提交搜索的名称一致,否则解析错误,无法正确搜索。
● 数据类型支持数据库的常见格式,其中要求非字符型字段不用有索引,只用于过滤或者存储。
● 是否需要索引,只针对文本字段。
● 是否需要过滤使用,可针对所有类型字段,一般文本索引即可,无需过滤使用。
● 是否需要存储,存储在文件中,方便搜索结果显示该字段。
● 是否为通配符索引域是指在不指定字段名称搜索时,是否覆盖该字段。
5)建立索引。
命令格式:

例如:
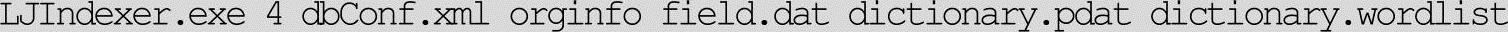
其中dbConf.xml配置信息如下:

其中:
DBConnectString为连接数据库的字符串,各个不同的数据库系统的字符串都不太一致,如
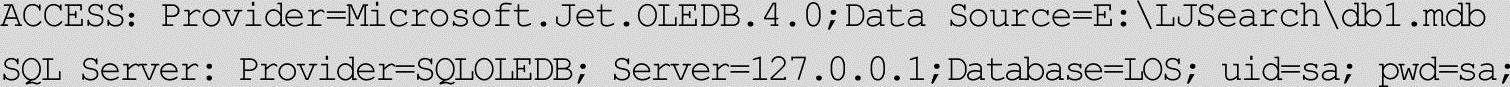
Table为需要建立全文搜索的表名;
SortField为搜索结果排序字段名称(在本例在,是按照id来排序的)。
6)构建全文搜索服务。
执行LJSearchServer.exe即可。
其中主要依据SearchServer.xml进行配置,配置文件如下:
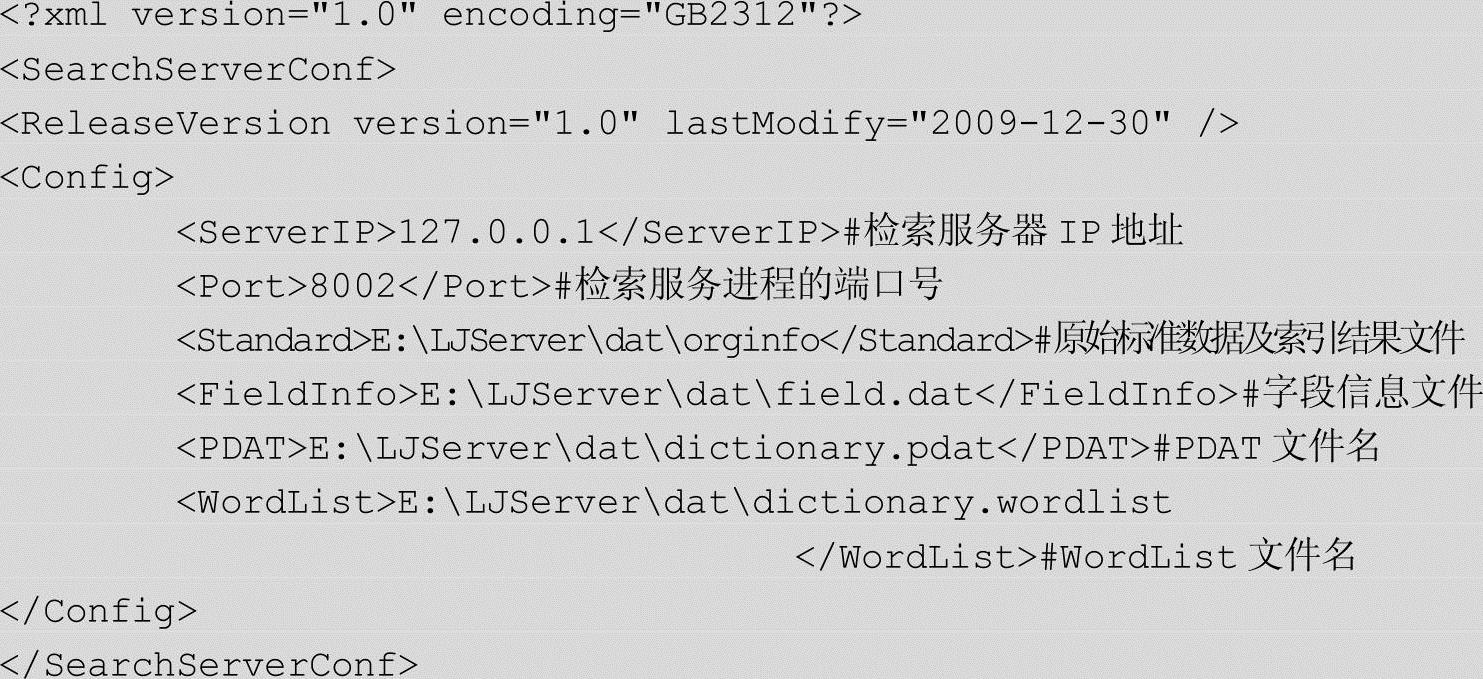
其中:
ServerIP为检索服务IP地址;
Standard为索引生成的数据路径名称。
7)检索对比测试。
启动检索测试程序SearchAgent.exe,输入检索语句,语句格式为:
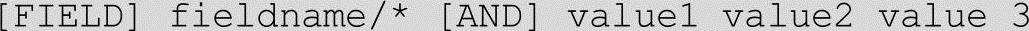
其中:
Fieldname为索引字段名称;也可以给出通配符*,表示在认定的字段范围内搜索;可以多个字段并联,实现关联搜索。例如:
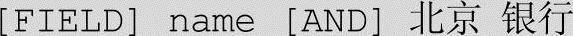
SQL语句查询为:
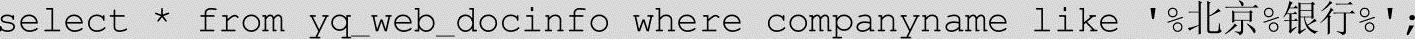
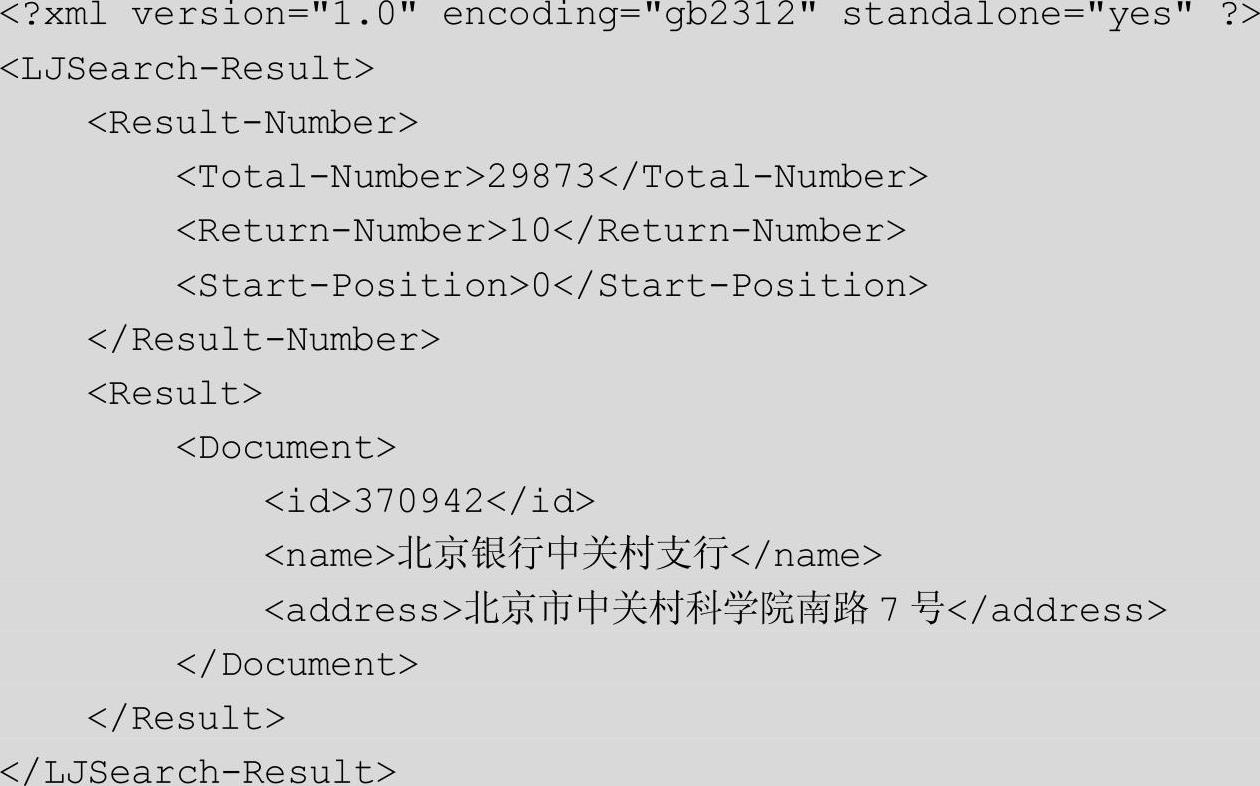
查看返回结果的数量和内容,DBTSearch的结果如下:
6.思考题
1)为什么全文搜索引擎DBTSearch能够显著提高数据库全文搜索的效率?
2)如何应用DBTSearch开发复杂的物联网服务应用程序?
3)如何实现多个服务器集群的分布式检索?
7.补充阅读
[1]灵玖DBTSearch数据库全文搜索引擎白皮书,灵玖软件,2010.
[2]D.Hawking,N.Craswell,andP.Thistlewaite.Overview of the TREC-7 very large collection track.In Proceedings of TREC-7,1998:40-52
[3]William Frakes,Ricardo Baeza-Yates.Information Retrieval:Data Structures&Algorithms[M].NewJersey:Prentice Hall Press,1992.
[4]Sergey Melnik,Sriram Raghavan,Beverly Yang.Hector Garcia-Molina Buildinga Distributed Full-Text Index for theWeb[C].In 10th International World Wide Web Conference,May2-5,2001:396-406.
[5]Eric W Brown,James P Callan,W Bruce Croft.Fast Incremental Indexing for Full-Text Information Retrieval[J].In Proc.of 20 th Intl.Conf.on Very Large Databases,September,1994:192-202.
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。