



文本是互联网和物联网中的重要组成部分,海量的文本信息一般是存储在专用的数据库系统中进行统一管理。数据库管理系统存储的一般都是结构化数据,以方便数值的计算、查询、统计与挖掘。但随着计算机存储与计算能力的迅猛发展,越来越多的非结构化文本数据存储在数据库中,数据库中的文本搜索日益广泛。
当前,数据库中的文本搜索,一般采用SQL语句中的Like操作符或者采用数据库系统自带的全文索引功能。Like操作往往特别耗时,数据规模超过10万条,查询往往会导致网络连接超时,无法满足在线搜索的需要;同时,Like查询仅仅是简单的字符串匹配,没有考虑语言语义。例如,检索“和服”,同样会命中“产品和服务”。当前,数据库内置的全文索引功能、速度和效果同样存在类似缺陷。因此,在数据库系统基础上,需要对非结构化文本字段构建智能的搜索引擎。
一个良好的搜索引擎结构应该满足以下几个目标。
1)良好的检索效果。系统以各种方式接受用户的查询请求,给出令人满意的检索结果,给用户最想要的内容。这一点是最重要的,需要优先考虑。
2)快速的响应效率。对于搜索引擎系统来说,在保证检索效果的同时,效率是非常关键的,应该让客户感觉到无延时地返回结果。
3)系统规模的可扩展性。众所周知,现在信息量的膨胀速度十分惊人,要想应对它的发展,必须在系统结构上作出努力,使得系统可以在几年内容纳合理数量的记录及其各种索引。
4)合理的系统性能。信息数量飞速增长,因此系统容纳的吞吐量可能越来越多,但是,系统必须保证在有限的运行资源下取得理想的效果。
5)系统结构最好便于修改。这是因为技术不断进步,今天看来很先进的技术,也许两年后便不再先进了。搜索引擎系统也需要不断地更新,加入对新技术的支持。要想做到系统结构的灵活性,最好的方法是保持系统各部分之间的相对独立。
6)可以保存日常的使用情况。便于进行日志的分析和挖掘,了解用户的需求和数据对用户的价值。
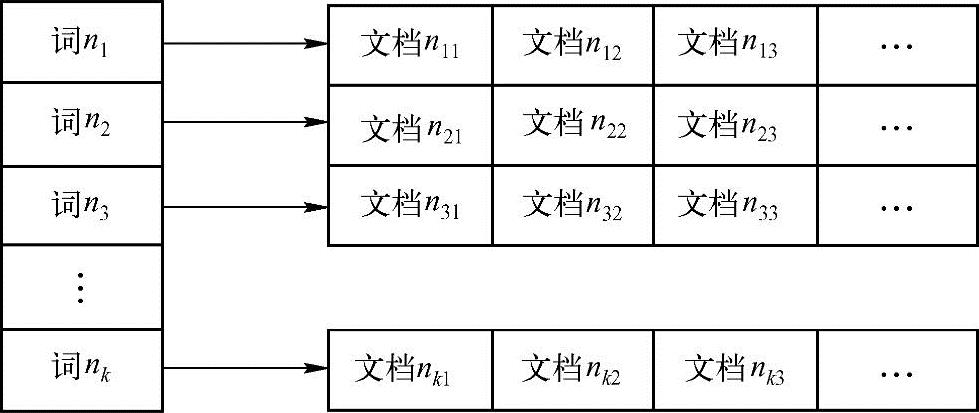
基于倒排索引的全文搜索技术较好地实现了上述目标,是目前应用广泛的索引和搜索方法。这种方法的基本原理如图5-6所示。
 (https://www.xing528.com)
(https://www.xing528.com)
图5-6 基于倒排索引的全文搜索技术的基本原理
从根本上说,倒排文件的基本结构是一个词表,每个表项是系统可以识别的一个词汇。从每个表项引出一个指针,指向一个数据结构,此结构记录了该词汇在所有文本中的出现位置和频率等信息。
倒排文件的生成过程是这样的:取得一个文本记录之后,将其顺序扫描,用一个分词词典对它进行分词,记录下每一个词的出现位置和频率,存入倒排表。合并所有文本产生的倒排表(当然,要记录下来词汇出现的记录),就得到倒排文件。
倒排文件方法有以下突出的优点。
1)实现简单。因为原理很简单,所以几乎所有的工作都集中在数据结构的设计和实际编码上。一个良好的数据结构是非常重要的,它会影响到系统的诸多方面,最重要的是:
● 查找速度。好的数据结构会使查询时需要检索的数据最小化,这样可以大大减少IO时间,提高程序运行效率。
● 存储空间。好的数据结构需要考虑极大数据量情况下的磁盘存储问题。页面的索引与页面需要的存储空间是同一量级的。因此,对于一个在大规模应用领域使用的搜索引擎来说,数据结构是非常重要的。
● 可维护性。倒排文件的结构是很难维护的,但设计良好的数据结构可以在一定程度上缓解这个难题。
2)查找速度快。倒排表的结构是直接适应查询请求的。对于只含关键字的简单查询,当用户输入查找关键字时,系统要做的工作就是分析关键字,从倒排表中查找相应的关键词,然后把它们对应的文本记录信息提取出来进行合并输出。即使文本库中包含的文本数量达到百万级,这个过程仍然是相当快的,一般在几毫秒钟之内就会得到结果。如果系统的查询界面支持逻辑操作符和其他操作符,这个过程会复杂一些,主要是增加了中间结果的合并操作,但相对简单查询来说,增加的复杂度仍然是线性的。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。