



为了比较分析VPM和PPM的性能,这两种策略都在同一个并行处理试验台上进行建模和仿真。试验台在非常接近实际情况的环境下,进行了大量实验设计和操作。一个实际移动计算网络的关键参数包括:静态网络的规模,即静态网络中的静态节点数量;静态网络的互联拓扑结构、移动实体数量、移动实体计算量、移动实体和静态实体每次交换的信息量以及移动实体的移动形式等,仿真过程中会采用一些独立变量来表示这些参数。评价性能的一个关键指标是完成试验台上所有处理程序所需的最长时间。在实验过程中,实体数量是受限制的,因为试验台只有65个工作站。假定静态互联网络拓扑是全连通时,静态节点的数量范围是5~10个,移动实体的数量范围是5~50个。一个移动单元的计算负荷用100~10000000之间的某个整数表示,形成一个简单的“for loop”循环(见图8.5和图8.10),这意味着“for loop”循环中的迭代次数就等于计算负荷值,也等于迭代循环模拟实际计算时间的操作次数。假定一个移动实体和一个静态实体之间的数据元交换量为1~100,其中,每个数据元素的虚拟长度为128B,这与第4章使用的消息尺寸是一样的。消息的交换也参考图8.5和图8.10中提到的方式,其中也展示了每个移动实体的移动形式:①随机的;②唯一的,即所有移动节点的移动形式都是相互独立的;③异步式的,即移动实体会以不规则的时间间隔发生迁移。这里对移动单元唯一的限制是实体不能立即与它刚刚连接过的静态节点重新连接。在仿真过程中,除另外说明的情况外,每个移动实体会与静态节点连接或切断连接的总次数是1000次。
假设并行处理试验台的处理器都是异步的,执行速度不同,时间也不同步,那么仿真过程中事件执行的顺序一般也与实际操作中不同。有时人们会采用一些不同的同步技术,来保证事件执行顺序的有效性。但是使用这种技术会加大仿真中人为的痕迹,产生与实际不符的仿真结果。这些同步技术还会大大降低仿真速度,对VPM和PPM都造成相似的影响,因此本章设计实施VPM和PPM时一律不使用这些技术。但是要注意的是,在第5~7章实施VPM时,是使用了同步化技术的。
仿真一共运行了200次,每次大约需要1000s,65个工作站同时执行,仿真中会产生几MB数据。当一个移动实体与一个静态实体相连时,首先它会在计算负荷值范围内执行运算,然后与静态进程交换数据。当每个移动实体都完成了规定数量的连接和断开后,仿真终止。用于评价的仿真时间包括建立协议连接所需的时间、运算时间、交换数据的时间以及断开连接的时间。
图8.12a分别表示了VPM和PPM中仿真时间随移动实体的计算负荷变化的情况。静态节点数设定为10,移动节点数分别为5、10和50。每次数据元交换量设定为1,且每个移动实体总共要连接和断开1000次。这些曲线显示:当计算负荷增加时,VPM中的仿真次数增长很快,而PPM中的仿真次数仍保持相对稳定。对于5、10和50个移动实体而言,PPM的仿真次数分别为110s、300s和710s,且一直保持不变。在计算负荷值较小时,VPM有较好的表现,因为PPM中连接和断开的花销很大。对于5个移动实体而言,当计算负荷超过20000时,PPM的表现优于VPM。同样,对于10个移动实体,当计算负荷超过50000时,PPM的表现也超过了VPM。更进一步来说,PPM成功地对50个移动实体进行仿真时,计算负荷值高达100000,需要710s,而VPM所需要的运行次数则远远超过100000次。当每个中继站交换的数据量设定为10、有5个静态节点和5个移动实体时,图8.12b显示PPM与VPM的比较结果也是差不多的。因此,对于较小的数据元交换量、中等的移动实体数量、计算负荷值在100000以下的情况,PPM策略具有较好的可扩展性,并且表现出更优越的性能。
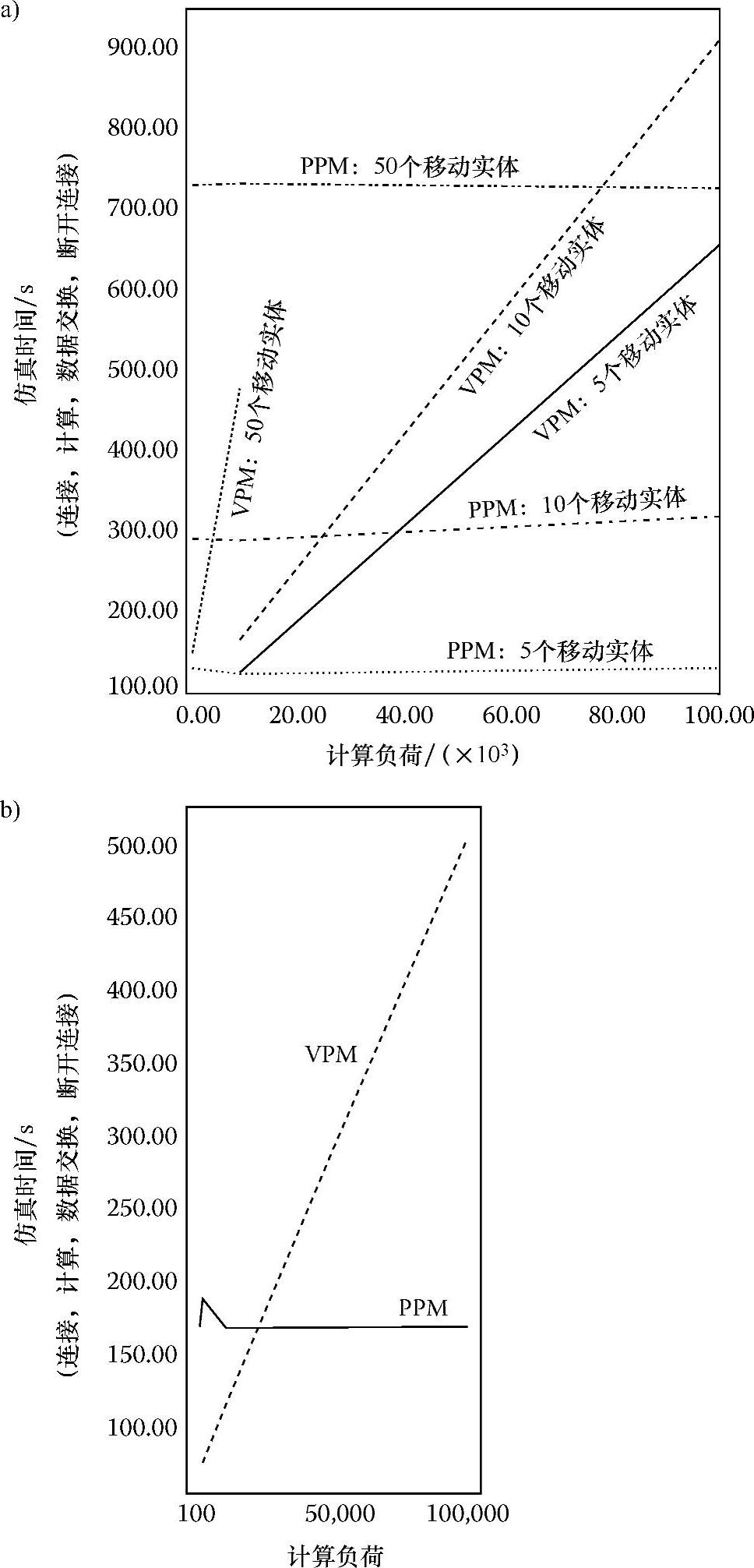
图8.12 VPM和PPM中的仿真时间是移动实体计算负荷的函数(静态节点总数为10,中继站每次交换的数据元个数为1,移动单元要完成1000次连接和断开)
a)每次交换10个静态节点和1个数据元 b)每次交换5个静态节点和10个数据元
图8.13重新组织了图8.12a中的数据,在计算负荷值分别为1000~100000的各种情形下,将仿真时间作为移动节点数的函数来画图,其目的在于揭示移动实体数量变化时,计算负荷值对PPM和VPM表现的影响。可以观察到,计算负荷值较小(在1000~10000之间)时,VPM性能比PPM好;超过100000时,PPM性能较好。PPM中的曲线差不多重叠在一起,这表明PPM中更多数量的处理器均匀高效地分担了高负荷的计算任务。
 (https://www.xing528.com)
(https://www.xing528.com)
图8.13 VPM和PPM中的仿真时间是不同计算负荷值情况下移动实体数量的函数(静态节点数为10,每次交换的数据元个数为1,移动单元要参与1000次连接和断开)
图8.14a和图8.14b绘制了VPM和PPM中仿真时间随着每次数据元交换数量而变化的情况。移动实体数设定为10。图8.14a和图8.14b分别将计算负荷值设定为10000和100000,分别考虑静态节点数量为5和10的情况。VPM曲线显示其仿真时间增长与数据元交换量的增长保持基本一致,因为复制缓冲区是非常快速的。然而,我们观察到,10个静态节点的VPM曲线比5个静态节点需要更多的仿真时间,这似乎是违反常理的,因为人们一般认为10个处理器,即10个静态节点去完成移动实体的计算任务要比5个处理器,即5个静态节点要快。出现这样的观察结果的原因在于,在每个静态节点中,将处理器标识符转换为套接字描述符号的函数是通过一个链表来实施的。在一般常用的方法中,每次执行函数时,都要依次搜索一遍链表。假设静态节点是全连通的,那么套接字的数量就会迅速增加,这样就会导致有10个静态节点的系统仿真速度比有5个静态节点的系统慢。UNIX效能评测器显示:10个静态节点的系统会在该函数上花费40%的仿真时间,而5个静态节点的系统则只花费了23%的仿真时间。由于处理器标识符与套接字描述符之间的绑定是固定的,人们已打算采用矩阵数据结构来提供更直接更快的访问路径。

图8.14 VPM和PPM中的仿真时间与每次交换的数据元个数的函数关系(移动单元数为10,移动单元要参与1000次连接和断开)
a)负荷值为10000 b)负荷值为100000
然而,在PPM中,随数据元交换的是精确的消息,所以数据元交换量的增加意味着需要更多的仿真时间,PPM曲线的斜率证明了这一点。对于10个静态节点的系统而言,PPM仿真时间虽然是增长的,但是在每次交换数据元的数量达到90之前,一直都低于VPM的仿真时间。显然,PPM中由20个处理器执行计算任务要比VPM中10个处理器来执行快得多。但是,当数据元素交换量超过90时,PPM中由于传递精确信息产生的费用会超过拥有更多计算单元所带来的优势,这时,VPM会在性能上超越PPM。静态节点数为5时,PPM中会配备15个处理器,而VPM中只有5个处理器。假设中等计算负荷值为10000,那么PPM对5个静态处理器的连接和断开压力将持续增加,再加上高额的精确信息传递花费,都将导致PPM的表现劣于VPM。也就是说,当每次数据元素交换量超过10时,PPM会失去它的性能优势。
当计算负荷值较高,如为100000时,PPM中更多数量的处理器很可能会使它的表现优于VPM。图8.14b的曲线进一步证实了这一预期,可以看出,在每次数据元素交换量从1增加到75的情况下都是如此。图8.14a中PPM曲线的斜率比VPM曲线的斜率大,但是图8.14b中,两种曲线的斜率是相近的。这是因为较大的计算负荷值抵消了PPM中昂贵的信息交流费用对其产生的影响。当有10个静态节点时,PPM仿真过程会使用20个处理器,只有5个静态节点时,PPM使用15个处理器,并且和预期的一样,前者的性能要优于后者。
总体来说,VPM和PPM在模拟和仿真实际的移动计算网络时都起到了极大的作用。PPM从本质上来讲更切合实际情况,但是VPM也能以适当数量的处理器实现拥有大量移动实体的网络在试验台上的仿真。第6章已描述了在一个有60个SUN Sparc 10工作站的网络上,模拟有45000个自主车辆实体的IVHS的过程。相比之下,PPM实施起来会比较困难,因为它需要大量的处理器,而且由于要处理大量的连接和断开,会使它的运行速度非常慢。当计算负荷以及移动实体数都很高时,PPM无疑会更好一些。然而,与VPM相比,当系统需要移动单元和静态单元之间频繁进行数据交换时,PPM的性能会差一些。我们希望在未来,随着试验台技术的大大改进,随着处理器数量的增加,连接和断开费用的降低,PPM能得到更广泛的运用。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。