



为了了解RYNSORD的性能,首先要确定独立参数和主要的性能评价指标,然后在实际铁路网络上进行大量的仿真实验,如图5.8所示。独立参数包括:①进入系统的火车数量;②火车的密度,即火车进入系统的频率;③使用的参数假设值。为了客观评价软预留的作用,本章还执行了另一个分布式路径算法,称为算法B。除了采用传统的硬预留策略之外,算法B在其他各方面都与RYNSORD类似。火车首先为主要路线发出硬预留请求,车站会尽量依照时间顺序在需要的时间段内为火车预留所请求的轨道。如果请求成功,火车就会使用主要路线上被批准的轨道。相反,如果每条轨道都很忙,预留请求就会被拒绝,火车立即返回始发站。在这种情况下,火车会接着为次要路线发送硬预留请求,如果这也失败了,火车再次为主要路线发起请求之前,必须至少等待一个时间步长。这个过程一直持续到火车能够获得预留为止,然后沿着被批准的轨道继续前进。所以,火车在成功获得预留批准前必须在车站等待,只有预留请求被成功批准后,火车才能沿着N段连续轨道向前移动。
主要性能评价指标有:①火车的行驶时间,即所有火车抵达目的地的平均时间;②抵达终点站的火车比例;③火车使用的中继段(轨道)数的分布;④火车行驶的中继段(轨道)数与前向值的函数关系;⑤每列火车的行驶时间与它们进入仿真的时间的函数关系;⑥轨道利用情况。此外,为了了解在全部实体中分配整体路径计算和通信任务的重要性,我们另外定义了三个性能评价指标,包括:⑦火车执行计算时间的分布;⑧车站处理预留的数量分布;⑨车站间链路的最大通信速率。
图5.9a是所有火车的出行时间与理想出行时间之差的平均值和前向值的函数关系图。每列火车的理想行驶时间作为一个参考值,它是指当整个系统中只有一列火车,并沿着最短路线前进到终点站而不受其他任何火车的干扰时,该火车需要的行驶时间。显然,由于实际系统中一定会有其他火车出现,所以某列火车有时并不能成功获得轨道预留,也不一定能按最短路线行驶。图5.9a显示了6条曲线,对应在3种不同密度下RYNSORD和算法B的情况。对于中、低输入交通密度,RYNSORD的性能一直优于算法B。图5.9a揭示了当前向值增加时,火车的平均行驶时间也会有不同程度的增加。对于高交通密度情况,RYNSORD的性能表现相对于算法B要差一些,这个异常现象可以由图5.9b中的曲线来解释。图5.9b描绘了仿真终止前抵达终点站的火车比例,同样对应在3种不同密度下RYNSORD和算法B的情况。密度的增加会引发更大的拥堵,从而导致能够完成全部行程的火车比例降低。同样,无论是在哪种情况下,RYNSORD仿真中火车抵达终点站的比例都比算法B大,这体现了软预留的优越性。此外,由于在高交通密度下相对于RYNSORD来说,算法B中抵达终点站的火车数量明显较少,造成图5.9a中算法B对应的行驶时间曲线不包括行驶到更远目的地的火车行驶时间,因此该曲线是扭曲的。
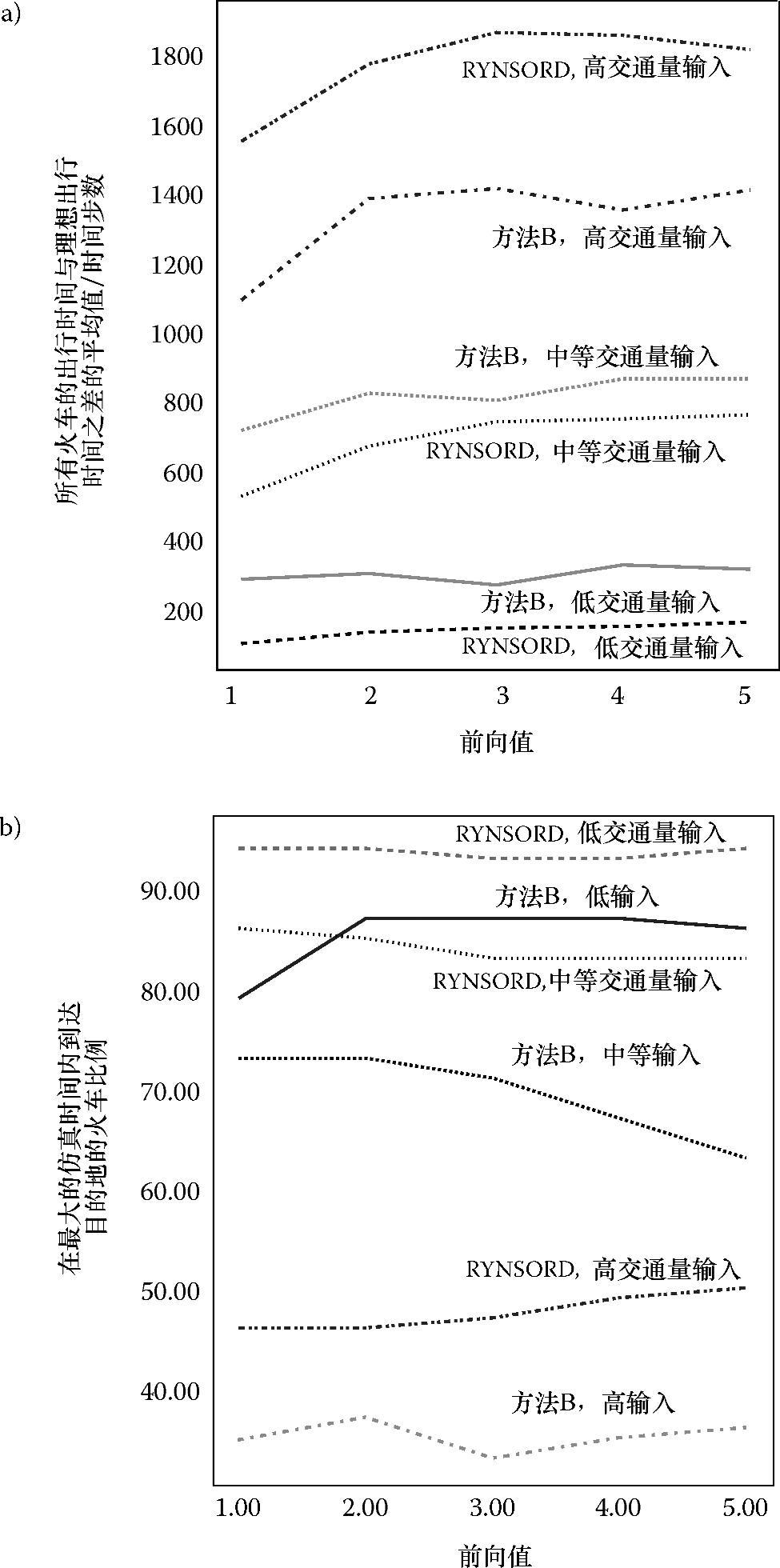
图5.9 所有火车的出行时间与理想出行时间之差的平均值与前向值的函数关系(图a)以及在最大仿真时间内到达其目的地的火车比例(图b)
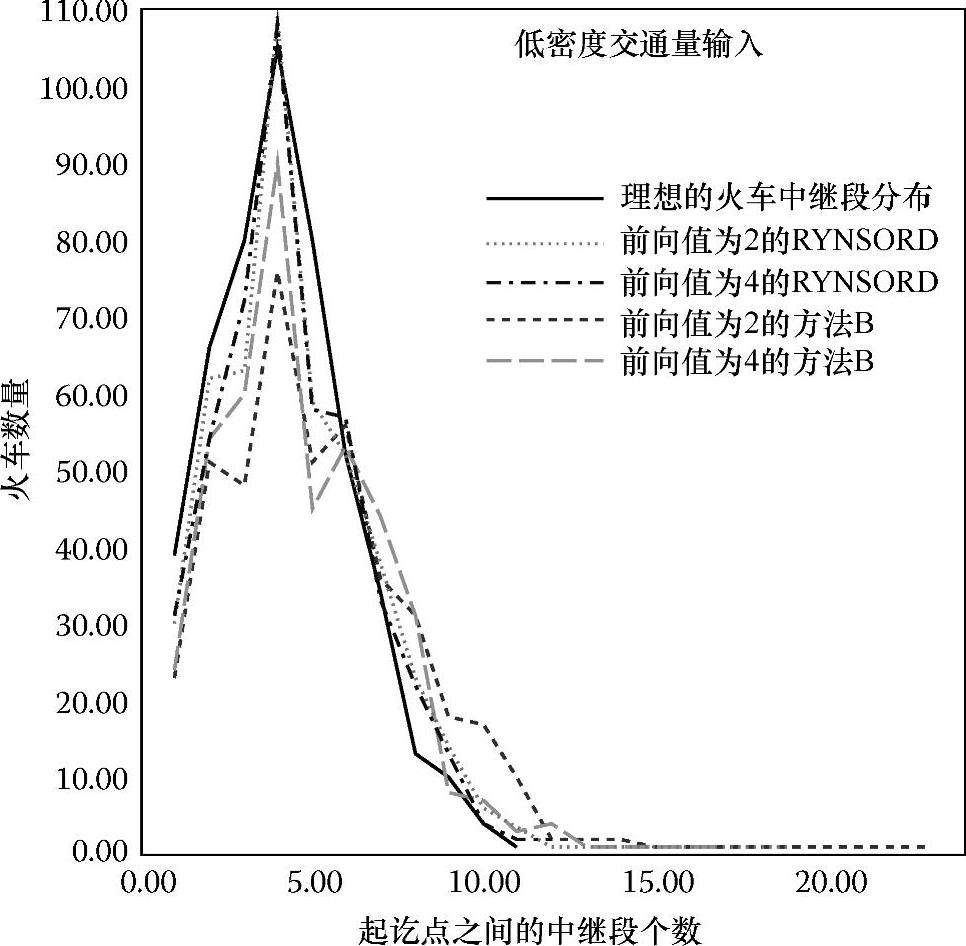
图5.10 在RYNSORD、方法B和理想状态下的火车实际中继段(轨道)数量分布图
图5.10显示了火车的中继段(轨道)的分布情况,即在低输入交通密度情况下,利用中继段(轨道)抵达终点的火车数量与中继段(轨道)数量之间的关系,轨道的数量在1~20之间。图5.10中有5条曲线,一条对应于理想状况,两条分别对应于前向值分别为2和4的RYNSORD结果,另外两条对应前向值为2和4时算法B的结果。这里的理想状况是指:将每列火车都看做系统中唯一的火车,火车按计算出的理想路线行驶的情况。在实验台上模拟的实际条件中,大多数火车都极可能无法为它们理想路线中的每段轨道获得预留,因为系统中存在的其他竞争火车也可能需要这些轨道。可是,与此推论截然相反的是,从仿真获得的图中却显示中继段轨道数量的分布非常接近于理想状况,也就是说,尽管有484列火车竞争轨道,但是RYNSORD在软预留策略下的分布式、动态路径算法产生的结果仍接近于理想状况。造成这种状况的原因如下:学术界一般认为,尽管分布式算法可能更快地产生结果,但分布式解决方案的质量还不能达到集中式算法结果的质量。这种看法源于一个事实,即当地的计算引擎在使用分布式算法进行决策的过程中,只被允许访问全局数据中的一小部分。而严密的RYNSORD仿真结果无疑证明了这种想法并不具有一般性。RYNSORD表明,在某些情况下,分布式算法也可以非常快速地产生高质量的解决方案。作者目前就正在研究一种新的数学结构,希望能从问题的集中式描述中提取出相应的分布式算法。图5.10也证明了RYNSORD的软预留是优于算法B的硬预留的。
图5.11a~c中的曲线对比了低、中、高交通密度条件下不同前向值的RYN-SORD和理想情况下的中继段轨道数量的分布情况。图5.11a~c中各自的每一条RYNSORD曲线都稍有不同,这表明前向值对中继段轨道数量的分布影响不大。此外,随着交通密度的增加,中继段轨道数量的分布越来越偏离理想状况,这意味着轨道竞争的加剧使得火车不再是沿它们从起点到终点的最短路线选择轨道。在图5.11a~c的每个图中,对应于前向值为2的图都显示出一个看起来小却不容忽视的迹象:较少的火车的数量却对应了过多的中继段轨道数。这是由折返行驶造成的,即当火车试图与车站协商一条合适的路线以到达目的地时,它可能会在两个或更多的车站间折返行驶。尽管这看起来可能会降低轨道的利用效率,但图5.9a的结果却表明火车在前向值为2的情况下,能更快到达目的地。随着前向值的增加,出现火车折返行驶的情况会大幅减少。
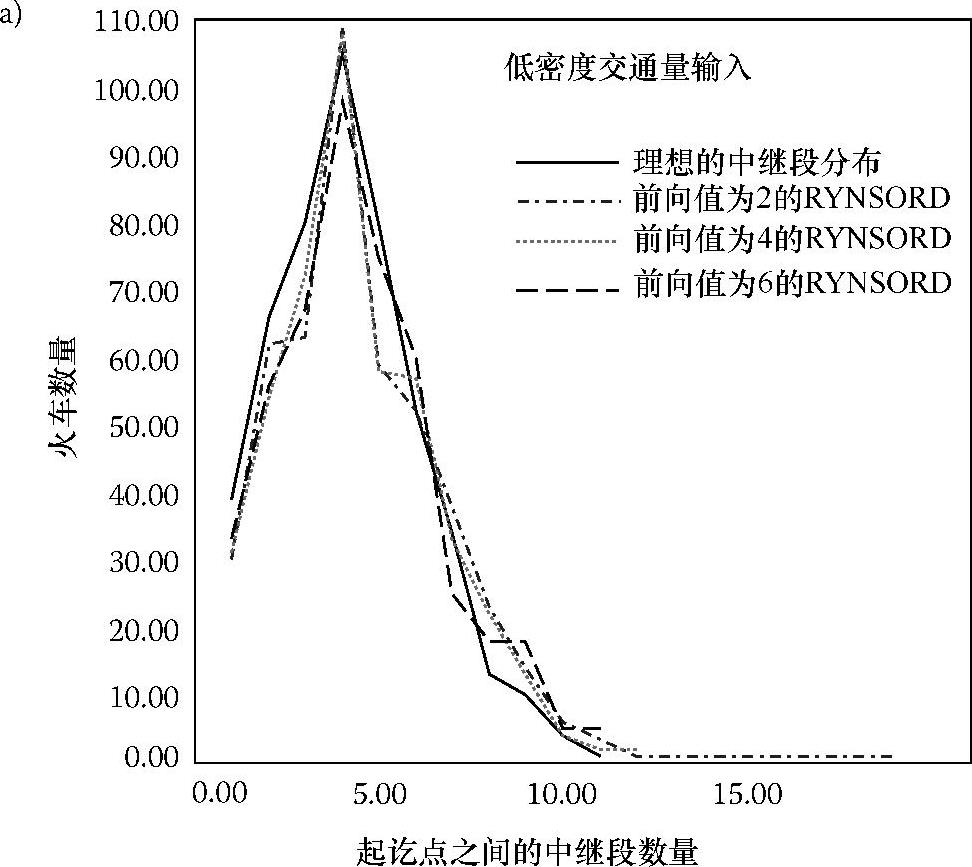
图5.11 低、中、高交通密度的输入条件下RYNSORD的中继段轨道数量实际值分布与理想分布的对比
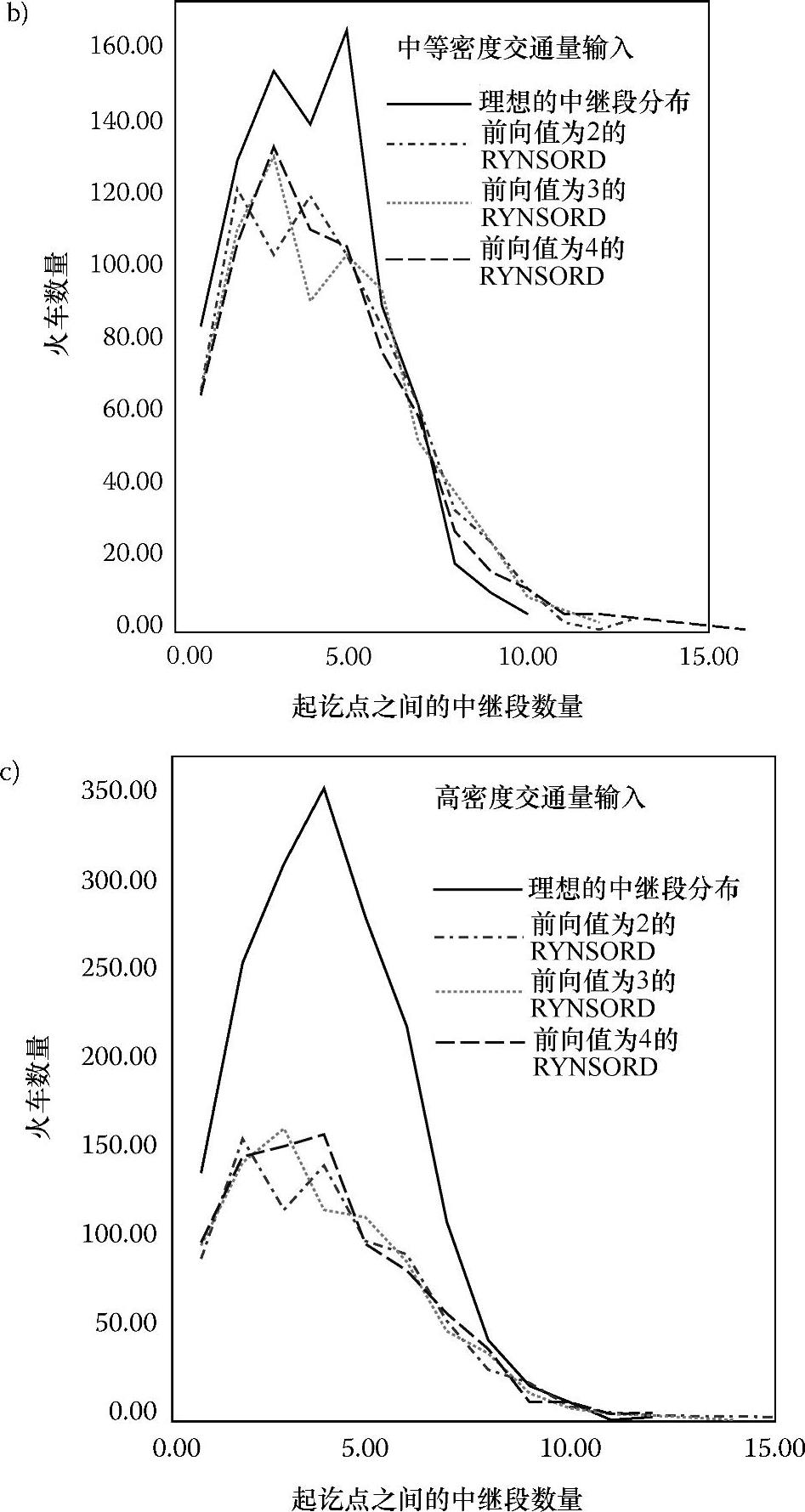
图5.11 低、中、高交通密度的输入条件下RYNSORD的中继段轨道数量实际值分布与理想分布的对比(续)
图5.12说明了在三种不同的输入交通密度条件下,RYNSORD和算法B的前向值大小对中继段(轨道)平均数的影响。对于每列火车,要计算理想的中继段轨道数,并将它当作比较火车实际使用的中继段轨道数的标准。在RYNSORD下,三种输入密度情况下的曲线看来都收敛到一个较小的数,它略小于方法B的收敛值,这再次证明了软预留的优越性。此外,对图5.12中每种情况的低前向值状态进行考察,发现平均中继段轨道数都明显高于理想的中继段轨道数。这证实了之前的发现:低前向值会使火车在运行过程中频繁转换轨道,造成火车在整个过程中要使用更多数量的轨道。
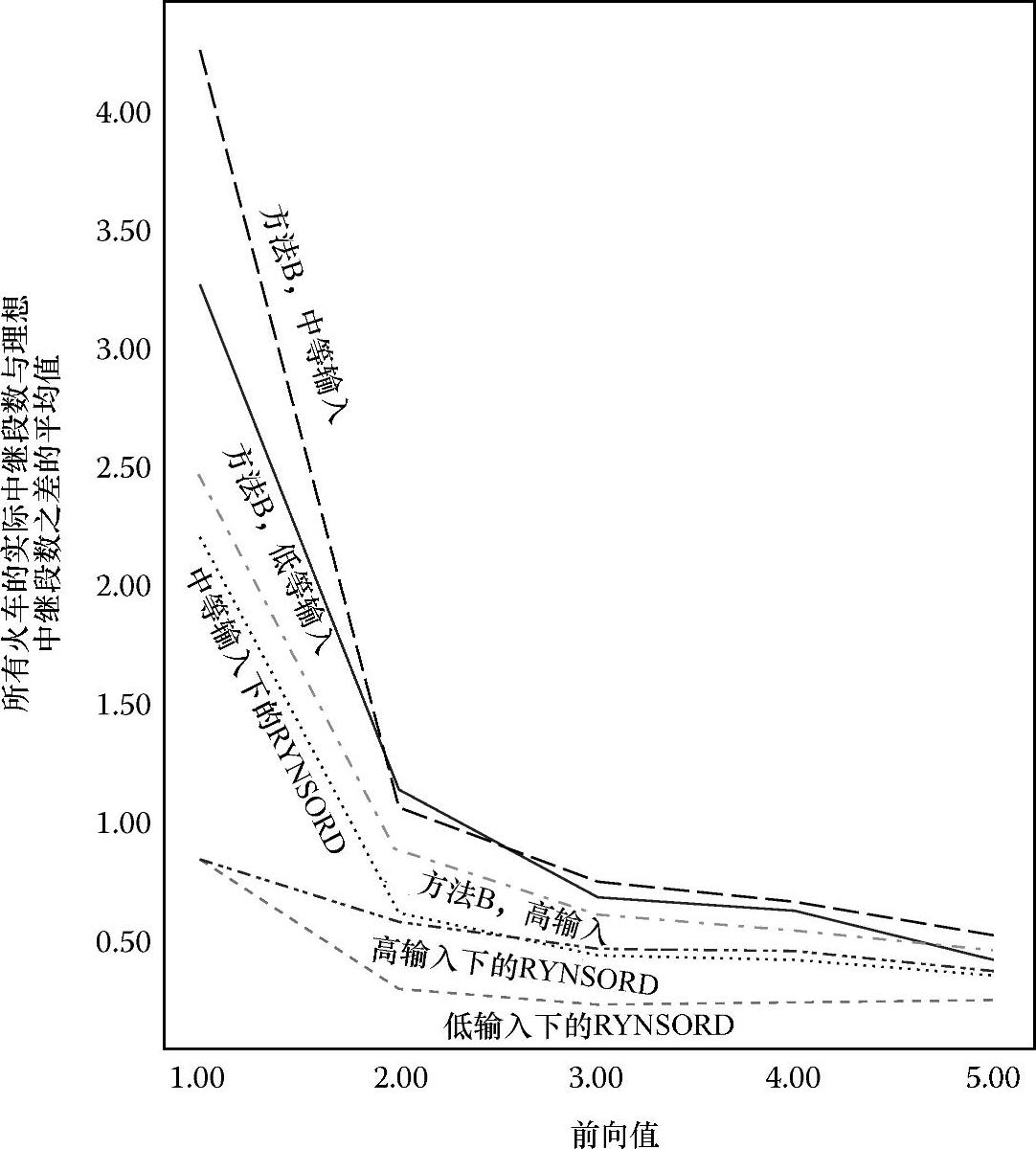
图5.12 所有火车的实际中继段数与理想中继段数之差的平均值与前向值的函数关系
图5.13a~c描述了所有到达目的地火车的数组关系[(实际行驶时间与理想行驶时间之差),火车进入系统的时间]。图5.13a~c分别对应于低、中、高输入交通密度情况。一般来说,随着越来越多的火车竞争轨道,火车会需要更多的时间到达目的地。这可以从图5.13a~c中Y轴上增加的时间步长刻度单位上看出。对于低输入交通密度,大多数火车到达目的地需要的行驶时间与其进入系统的时间无关,所以图5.13a中的分布相对均匀。而图5.13b则在较高的进入时间值处,即进入系统的时间步长为10000处出现一定程度的中断,这种情况在图5.13c中更加严重。这反映了一个事实:在较高的输入密度下,一列火车Ta比另一列火车Tb更晚进入系统,而火车Tb却可能比Ta需要更多的行驶时间,并且,在某些情况下,它甚至可能无法在允许的最大模拟时间内成功完成旅程。显然,为了形成一个中断最少、稳定而连续运行的系统,必须选择一个适当的输入交通密度。
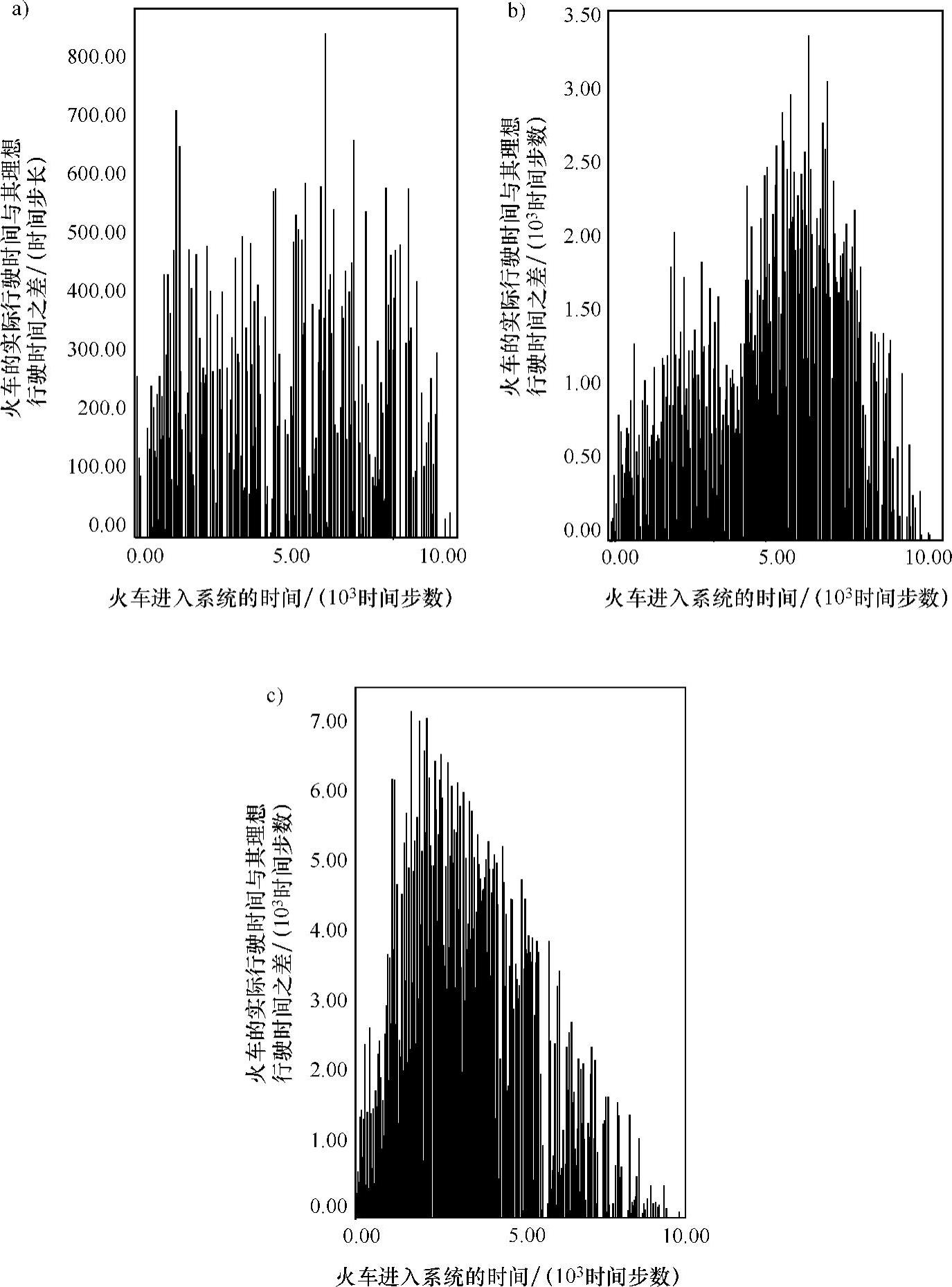
图5.13 前向值为4时,RYNSORD中火车的实际行驶时间与其理想行驶时间之差,与火车进入系统的时间之间的函数关系
a)低交通输入密度 b)中等交通输入密度 c)高交通输入密度
图5.14a、b显示了轨道的使用结果,即算法B和RYNSORD中每段轨道被火车使用的累积次数。轨道区间段编码为1~84。虽然大部分轨道段的使用都是合理的,体现出了资源利用的有效性,但还是有一些轨道段有过高的使用率,反映出火车目的地选择的随机性和对“高流量”车站的选择偏好。可以观察到,图5.14b中的轨道使用率在一般情况下要比图5.14a的高,这意味着RYNSORD软预留优于算法B的硬预留。
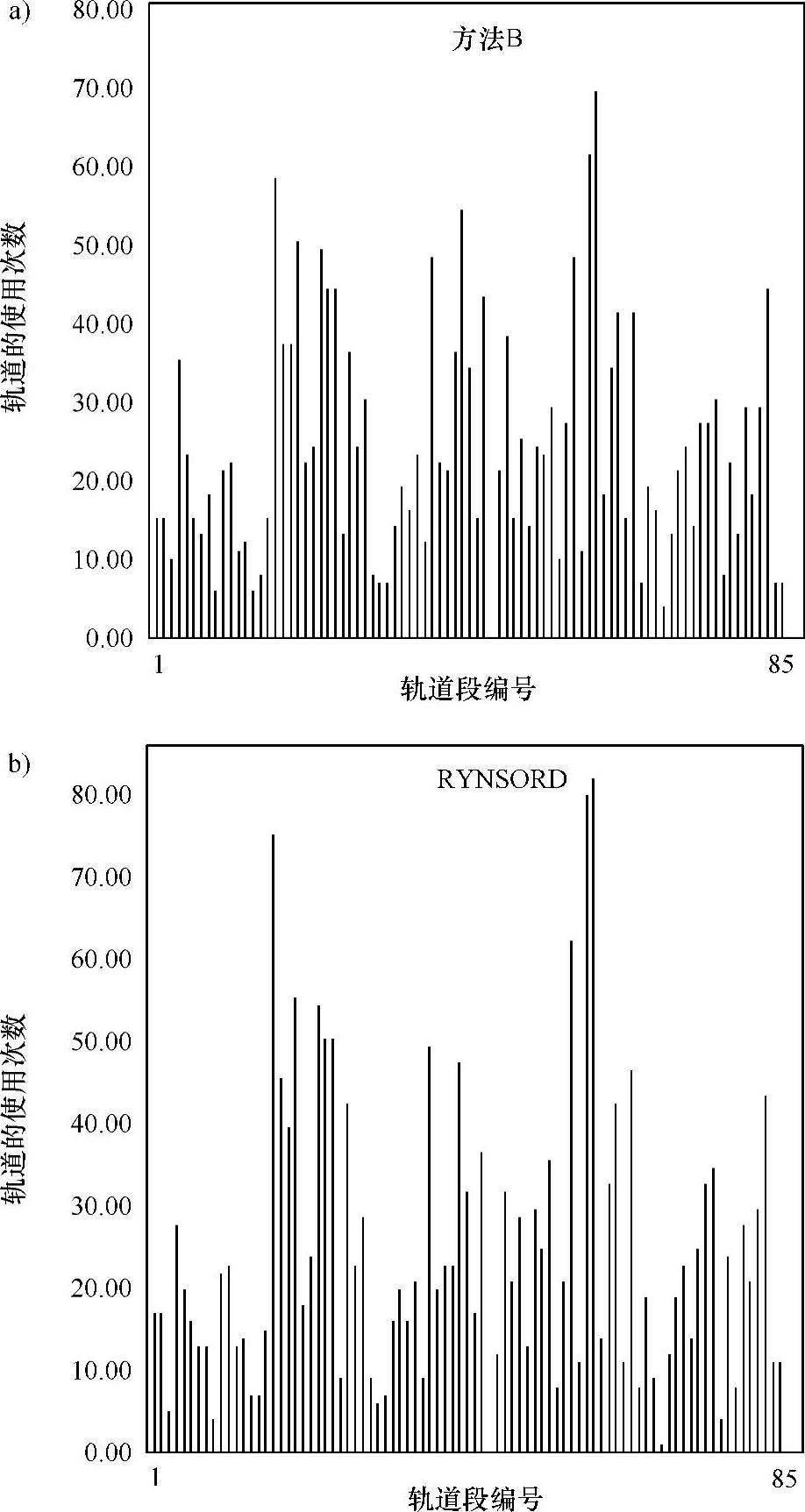
图5.14 低输入交通密度、前向值为6时轨道的使用次数分布
a)方法B b)RYNSORD(https://www.xing528.com)
图5.15a、b显示了高输入交通密度时的轨道利用情况,它显然大大高于图5.14b中低输入交通密度时的利用率。然而,从图5.15可以看出,RYNSORD的轨道利用率并没有受到前向值选择的显著影响。
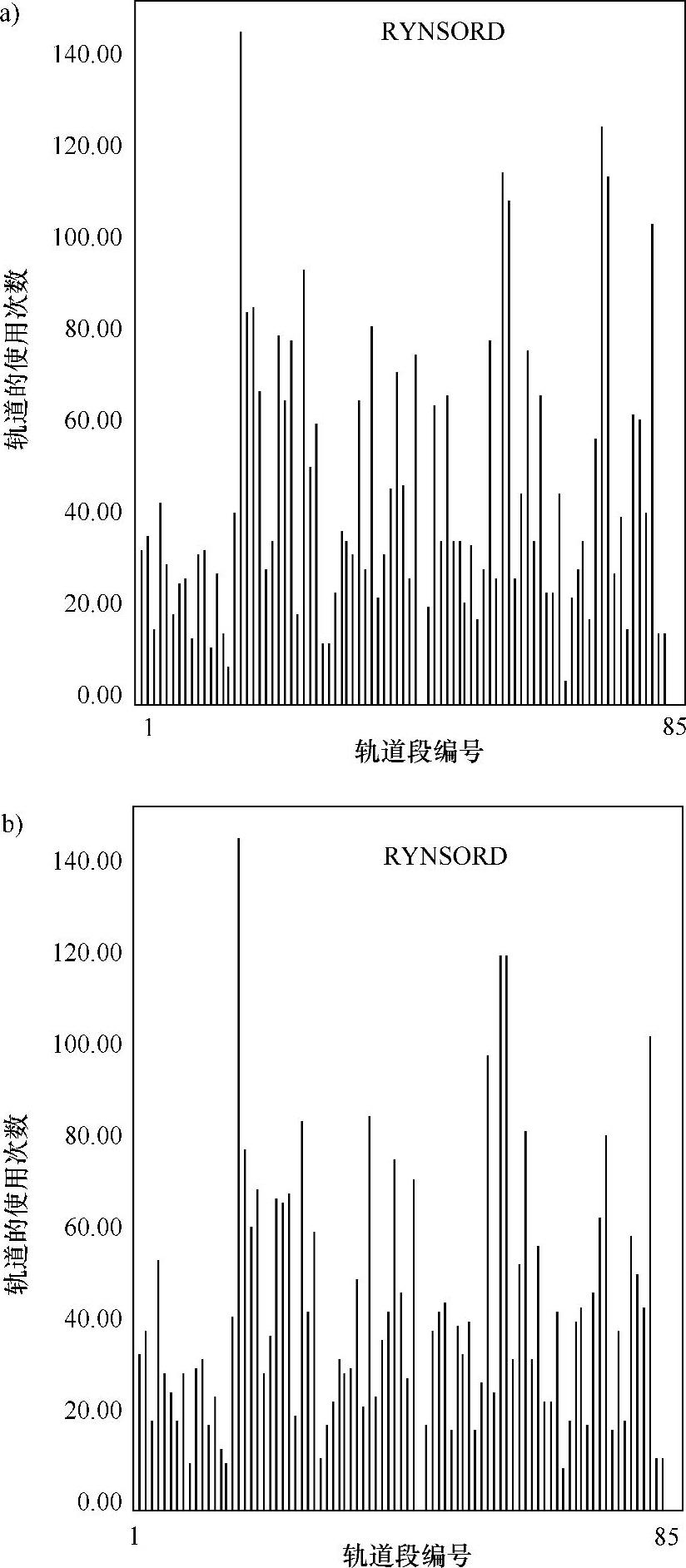
图5.15 高输入交通密度时的轨道使用次数情况
a)前向值为2 b)前向值为4
图5.16显示了为所有站间火车进行路径计算的部分任务的分布情况。为所有火车计算路径的任务中,一个重要组成部分就是预留处理。图5.16a对应的前向值为2,图5.16b的前向值为4。前向值为2情况下,车站间的计算负荷分配值略高于前向值为4的情况。尽管在低前向值情况下,每列火车都要更频繁地执行Dijkstra[44]的最短路计算,但在某个特定时间,它们预留的车站可能更少。
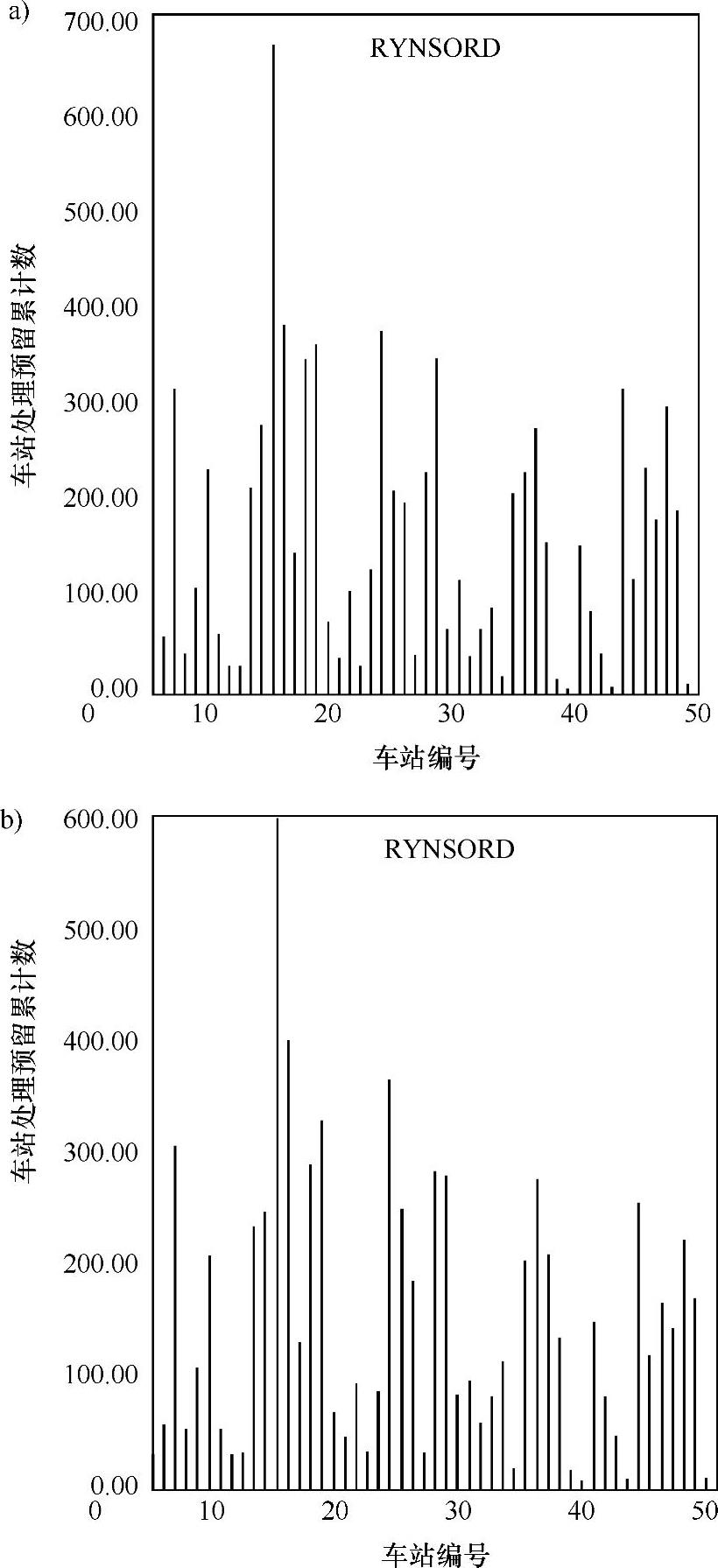
图5.16 在中等输入交通密度下,RYNSORD中车站处理的预留数分布情况
a)前向值为2 b)前向值为4
图5.16a和图5.16b都强调了要将全部路径计算任务有效地分配给所有车站节点这一初始目标。预留处理分布的不均匀主要是由火车目的地的随机性造成的,这又反过来影响了火车的路径计算。
图5.17给出了完成火车间全部路径计算任务中剩余部分的时间分布情况。全部路径计算任务的另一个主要组成部分就是火车通过执行最短路算法计算主要路线和次要路线。图5.17a对应于前向值为2的情况,图5.17b对应于前向值为4的情况。
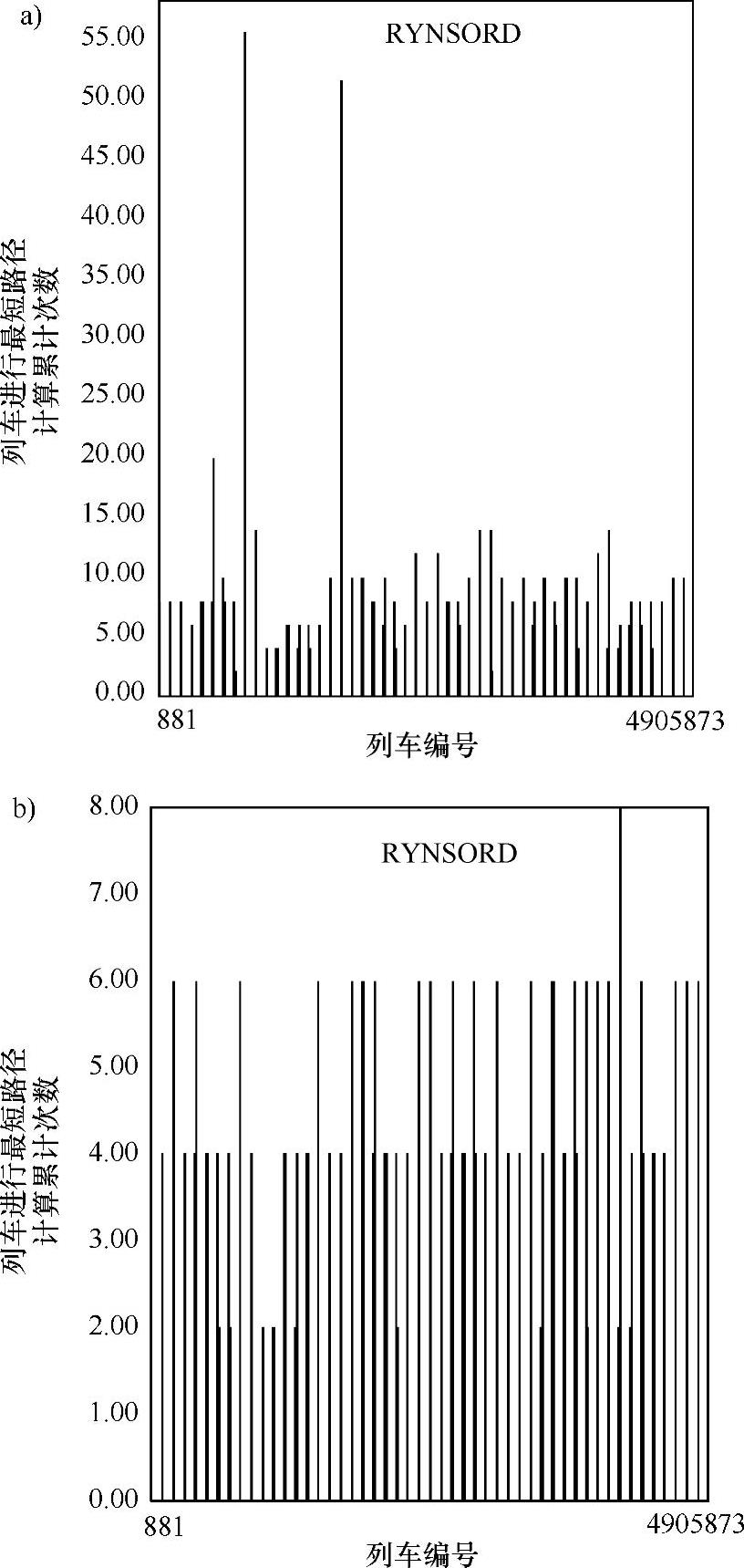
图5.17 在中等输入交通密度情况下,RYNSORD中列车计算量分布情况
a)前向值为2 b)前向值为4
图5.17a和图5.17b也都强调了RYNSORD的初始目标是在所有火车间有效地分配全部路径计算任务。在图5.17a和图5.17b中,除了少数火车外,大多数火车的计算量负荷均匀,这样就实现了在所有火车中均匀分配计算任务的目标。图5.17a的计算量明显高于图5.17b,因为在低前向值的情况下,火车需要更频繁地进行最短路计算。
表5.2和表5.3提供了一些从仿真中采集的数据,以帮助我们理解前向值对主要性能指标的影响。“平均时间”是指火车实际行驶时间与理想行驶时间的相对数,它的值等于{[(每列火车的实际行驶时间-理想行驶时间)对所有火车求和]÷火车的总数}。表5.2是低输入交通密度情况下的数据,表5.3则对应中输入交通密度。在表5.2中,对于高前向值,火车的平均行驶时间会增加,与其有关的平均等待时间也相应增加。平均等待时间的增加是由于N值的增加,增加了要预留的轨道数,火车就必须在启动预留请求的主站等待更长时间,同时也需要与更多的车站通信。但是,平均中继段轨道数却随着前向值的增加而减少,而火车折返行驶的次数减少幅度更大。低前向值和高前向值对各性能参数影响的对比在表5.3中表现得更明显。
表5.2 低输入交通密度下不同前向值对RYNSORD性能参数的影响比较
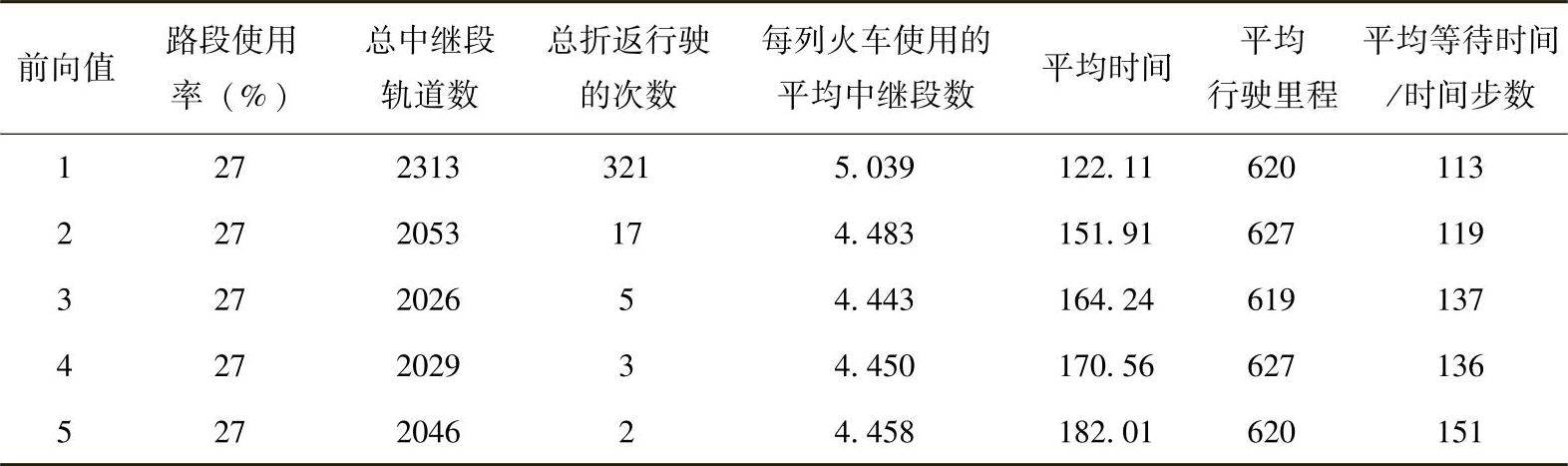
表5.3 中等输入交通密度下不同前向值对RYNSORD性能参数的影响比较
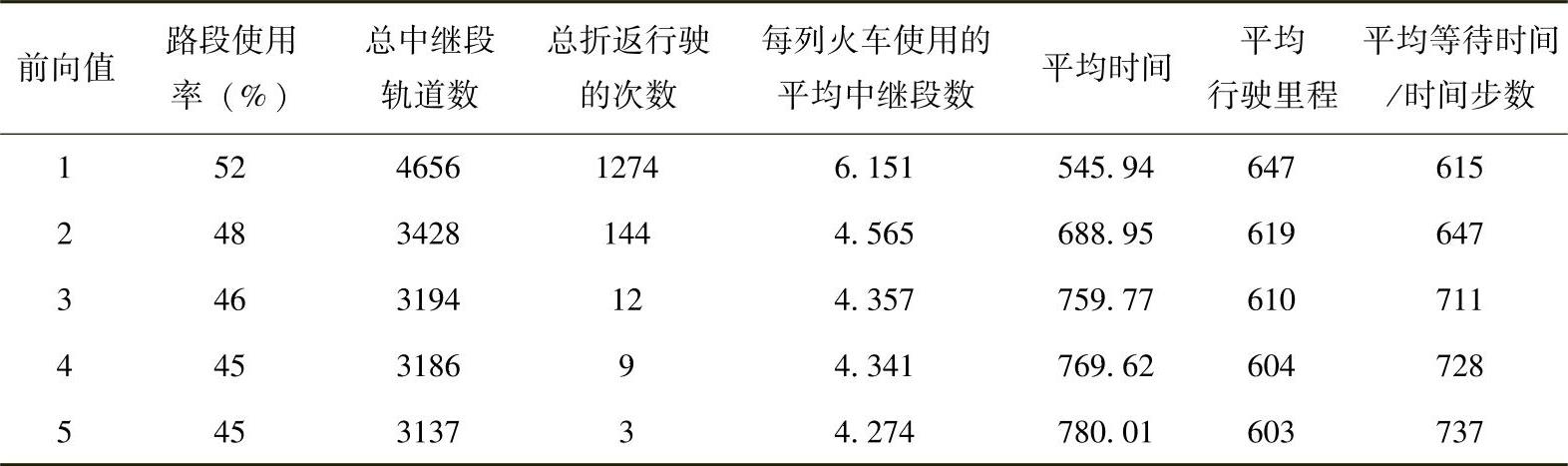
对于低前向值情况,火车的平均行驶时间和平均等待时间明显较低。然而,火车的平均行驶里程、平均中继段轨道数和路段的使用率却较高。此外,火车折返行驶的次数相当高。这是因为低前向值情况下火车只能对全系统范围内的拥挤状况进行有限的观察,并且在做较长路线的方案选择时,很有可能会做出较差的方案。然而,这种情况下,火车往往更加频繁地进行线路选择,虽然这增加了它们的计算负担,但是能及时更新信息,并做出更优的决策,较短的平均行驶时间再次证明了这一点。相反,火车在高前向值的情况下,有可能在较长时间内被锁定在特定轨道段上,不能快速地利用整个系统中轨道的动态变化情况重新进行路线选择,其更长的平均行驶时间反映了这一点。然而,高前向值时,运行路线更易于组织,需要的中继段轨道数和行驶距离都较少,并且几乎消除了折返行驶的情况。因此,在追求较短的行驶时间,且可以忽略轨道使用成本的情况下,低前向值是合理的;而在轨道使用成本比火车空闲在车站的等待成本高很多的情况下,推荐使用高前向值。
RYNSORD的一个基本目标是通过将总体路径计算任务分配到全部实体中去,而尽可能使网络内部的通信量减到最少。图5.18显示了每个站间通信链路的最大通信速率。鉴于仿真的分辨率为1个时间步长或实际操作的1min,这里提出的数据分辨率也限制为1min。在图5.18中观察到的数据传播的最大速率是500B/min,这通过传输速率为9600bit/s或19200bit/s的商业无线调制解调器可以很容易地实现。这样也就实现了RYNSORD的一个基本目标。相比之下,集中式算法理论上需要更高的通信速率,这意味着通信系统接口的成本会十分昂贵。
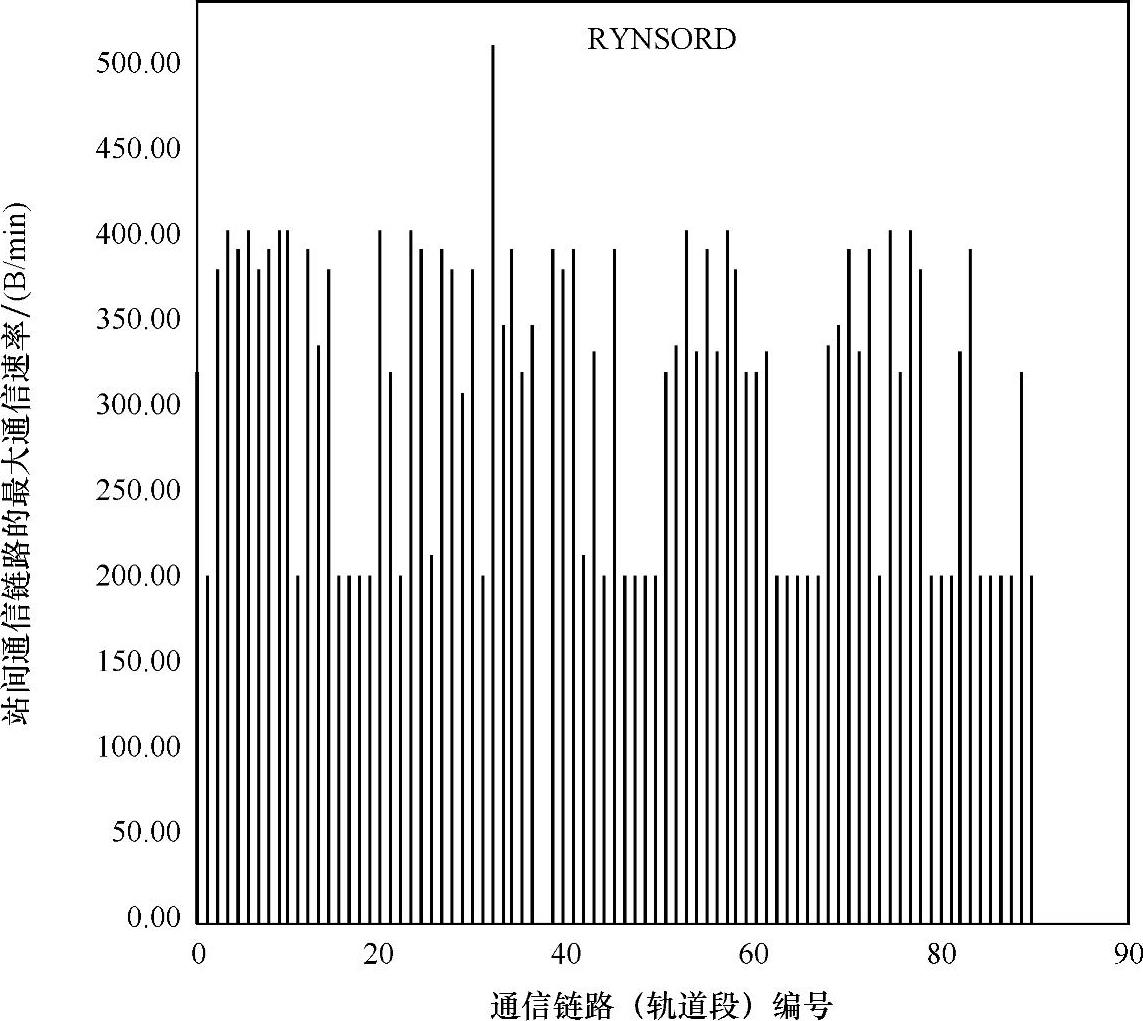
图5.18 站间通信链路的最大通信速率
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。