



RYNSORD模型和仿真器用C语言编写,在一个基于UNIX工作站的异构网络上执行,该网络通过一个10Mbit/s的以太网连接,并且配置为一个松散耦合的并行处理器。工作站使用免费却有版权的Linux操作系统,该系统提供英特尔486DX2/66和奔腾处理器,还包含SUN OS4.1.2和SUN Solaris 5.3操作系统的SUN Sparc1、Sparc2和Sparc10工作站。站点和火车通过程序进行模拟,并且通过TCP/IP进行通信。关于每个车站及停靠在该站点的火车在内的代码段大约是1700行C程序,网络代码约1000行,也是C程序代码。仿真器由GNU C,gcc编译,效果设置为“好”,在低优先级背景下执行。我们要说明的是到这些工作站可以为控制台的用户完成大部分主要工作。如果50个SUN Sparc10工作站同时运行,进行单次仿真实验的平均时间约为2h。
RYNSORD是一个建立在最高级通信协议TCP/IP上的应用程序。根据定义,ISO-OSI层模型开始于会话,它在两个或更多的机器之间通信时负责所有必需的数据转换工作。由于英特尔80X86机器采用Little Endian模式而SUN Sparc机器采用Big Endian模式[42],所以在异构网络工作站中要实现必要的转换数据,就必须使用n-to-h l(网络到主机长整型)、n-to-h s(网络到主机短整型)、h-to-n l(主机到网络长整型)和h-to-n s(主机到网络短整型)等实用程序[43]。
在这一章中,我们根据美国东部现有的主要铁路情况,选中美国东部铁路网的一部分(如1994年兰德麦克纳利商业地图集所示)作为研究对象,并在其中加入一些额外的轨道来代表一些次要铁路路段。图5.8给出了这个典型铁路网的情况,该网络由50个主要车站、84个轨道段区间和总长14469mile的轨道组成。在图5.8中,网络的模型在RYNSORD上建立,仿真在50个工作站的网络上执行,并且一个车站对应于一个工作站。
为了得到有代表性的运行结果,许多实验中随机产生输入火车并将其引入到RYNSORD中运行。铁路交通密度,是指每单位时间步长内被引入到系统的火车数量,对该密度的选择是根据一年365天都使用美国东部铁路轨道的货运列车的实际数量获得的。本章的实验选择了三种铁路交通密度——低、中、高。在一个时间步长内(即实际的1min)生成一列火车的概率,对于低、中、高交通密度来说,分别设为0.075、0.15和0.30。对于每列在车站始发的火车,其速度是随机生成的,取值范围为60mile/h~100mile/h。除了始发站是随机选择的一个车站外,最终目的地的选择,也是通过对始发站以外的每个车站分配相等的权重后随机产生的。地理上的优势在选择过程中不起作用。对应于大城市的车站更有可能产生较高的交通密度,我们从图5.8中选择了一组9个具有“高流量”的车站,包括芝加哥、底特律、圣路易斯、费城、纽约、华盛顿、匹兹堡、哥伦布和辛辛那提。对于和这些城市相对应的车站,输入火车的交通密度将增加一倍。另外,在选择火车最终目的地的过程中,这些城市的车站权重是其他城市的两倍。
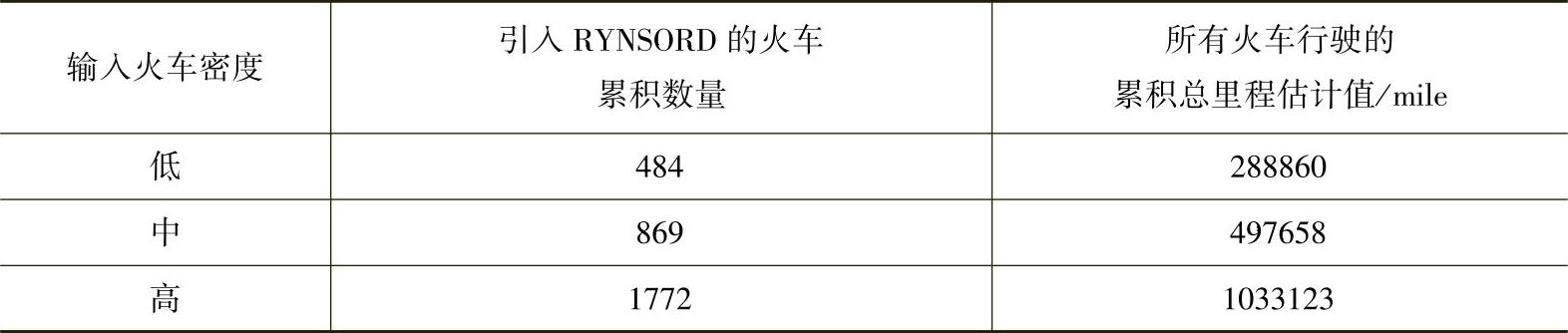
根据不同的情况,针对不同的参数,我们对这个有代表性的铁路网仿真了150多次。每次仿真都执行10080个时间步长,它对应于实时操作的一周时间。如前所述,执行一次典型的仿真实验大约需要2h,而50个工作站如果单独运行,最长的运行时间往往需要7h。在每一次仿真运行的过程中,火车输入都是一个常数,火车速度也是一定的,该速度是在仿真开始时就设定好的。表5.1分别给出了低、中、高输入火车密度下被引入系统的火车累积数和所有火车行驶的累积总里程估计值。这一估计值的确定,是建立在每列火车都是沿着从起点到终点的最短路径行驶这一假设基础上的,所以这个值并不一定在每种情况下都是对的。(https://www.xing528.com)
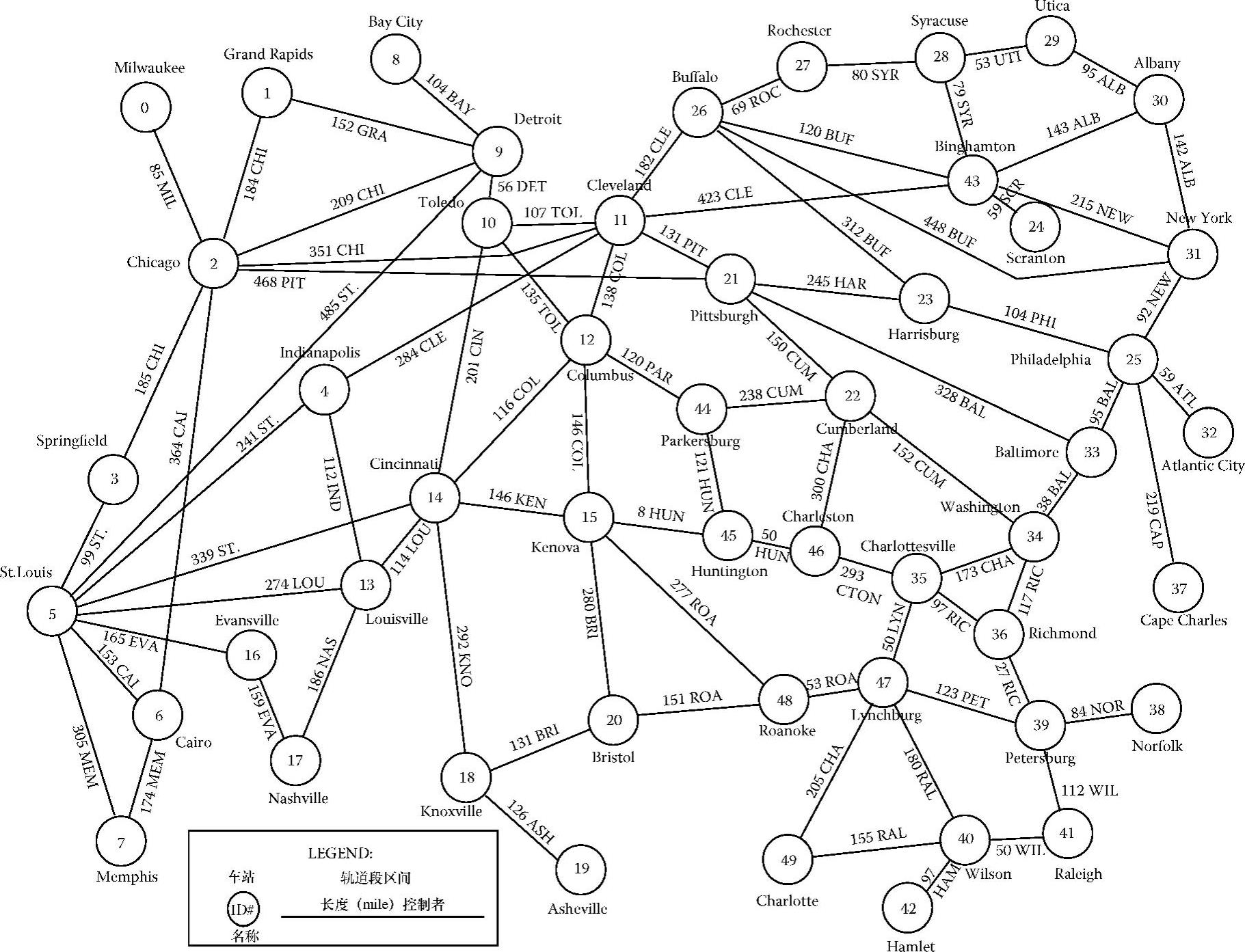
图5.8 一个典型的铁路网:美国东部铁路网络中由5O个车站组成的子网
表5.1 输入的火车交通参数
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。