



时间序列分析是根据系统观测得到的时间序列数据,通过曲线拟合和参数估计来建立数学模型的理论和方法。通常采用曲线拟合法和非线性最小二乘法,通过观测、调查、统计、抽样等方法取得被观测系统的时间序列动态数据,然后根据动态数据做相关图,进行相关分析,求自相关函数。具体计算方法如下:
可以假设yt是时间变量t的时间序列观测值;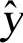 为第t期的预测值。通常采用二次曲线外推法进行预测,预测模型为
为第t期的预测值。通常采用二次曲线外推法进行预测,预测模型为
则第t期的离差为
离差的二次方和Q为(https://www.xing528.com)
将收集到的各个时间序列点xt以及对应的具体保有量数值yt代入模型,可以得到一些方程组,结合最小二乘法可以求得参数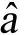 、
、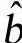 、
、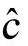 的值。计算出的模型需要用另外采集的数据代入进行验证,保证模型的预测精度(即离差et与离差的二次方和Q的值)控制在合理的范围之内。得到合理的预测模型后,输入想要预测的时间序列点xt,就可以得到对应的汽车保有量数值。
的值。计算出的模型需要用另外采集的数据代入进行验证,保证模型的预测精度(即离差et与离差的二次方和Q的值)控制在合理的范围之内。得到合理的预测模型后,输入想要预测的时间序列点xt,就可以得到对应的汽车保有量数值。
在进行曲线拟合的过程中,从相关图中能得出变化的趋势和周期,并能从图中发现一些跳点与拐点。跳点是指与其他数据不一致的观测值。如果跳点是正确的观测值,则在建模时应当将其考虑进去;如果是反常的值,则应把跳点设置成期望值。拐点是指时间序列从上升趋势突然变为下降趋势的点,也就是曲线的明显转折点。如果有拐点存在,则应在建模时用不同的模型去分段拟合该时间序列。
采用时间序列数据的方法对电动汽车保有量进行预测时,可通过建立趋势、季节、周期等因素下的状态空间方程,对各成分值进行预测,并以此对汽车拥有量样本期内和样本期外的值进行预测。但是时间序列数据的方法仅仅是基于历史数据来对未来进行延续性预测,只是围绕时间这个变量因素而没有考虑到未来电动汽车市场可能发生诸多复杂变化所带来的影响。当电动汽车市场或者相关政策发生较大变化时,预测结果可能会存在一定的偏差。因此时间序列数据预测法对于中、短期的预测效果要好于长期的预测效果。同时在电动汽车的普及阶段,外界因素发生重大变化的可能性很大,电动汽车保有量的发展趋势也将因此发生异于以往的变化。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。