



1.正确率
在介绍系列指标之前,先明确以下4个基本的定义:
①True Positive(TP):指模型预测为正(1)的,并且实际上也的确是正(1)的观察对象的数量。
②True Negative(TN):指模型预测为负(0)的,并且实际上也的确是负(0)的观察对象的数量。
③False Positive(FP):指模型预测为正(1)的,但是实际上是负(0)的观察对象的数量。
④False Negative(FN):指模型预测为负(0)的,但是实际上是正(1)的观察对象的数量。
上述4个基本定义可以用一个表格形式简单地体现,见表4-2。
表4-2 二类问题的混淆矩阵

基于上面的4个基本定义,可以延伸出下列评价指标:
①Accuracy(正确率):模型总体的正确率,是指模型能正确预测、识别1和0的对象数量与预测对象总数的比值,公式为
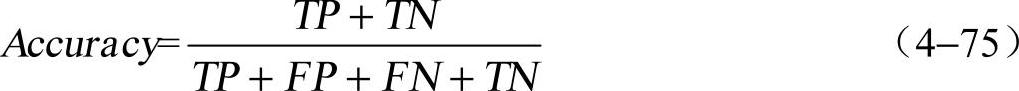
②Errorrate(错误率):模型总体的错误率,是指模型错误预测、错误识别1和0的观察对象的数量与预测对象总数的比值,即1减去正确率的差,公式为
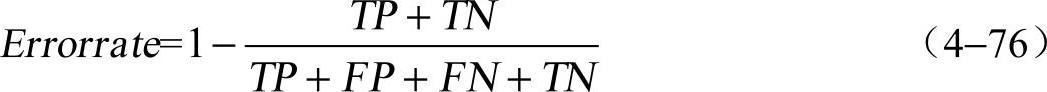
③Sensitivity(灵敏性):又叫击中率或真正率,模型正确识别为正(1)的对象占全部观察对象中实际为正(1)的对象数量的比值,公式为

④Specificity(特效性):又叫真负率,模型正确识别为负(0)的对象占全部观察对象中实际为负(0)的对象数量的比值,公式为

⑤Precision(精度):模型正确识别为正(1)的对象占模型识别为正(1)的观察对象总数的比值,公式为
 (https://www.xing528.com)
(https://www.xing528.com)
⑥False Positive Rate(FPR,错正率):又叫假正率,模型错误地识别为正(1)的对象数量占实际为负(0)的对象数量的比值,即1减去真负率Spedficity,公式如下:

⑦Negative Predictive Value(NPV,负元正确率):模型正确识别为负(0)的对象数量占模型识别为负(0)的观察对象总数的比值,公式为

⑧False Discovery Rate(FDR,正元错误率):模型错误识别为正(1)的对象数量占模型识别为正(1)的观察对象总数的比值,公式为

可以很容易地发现,正确率是灵敏性和特效性的函数:
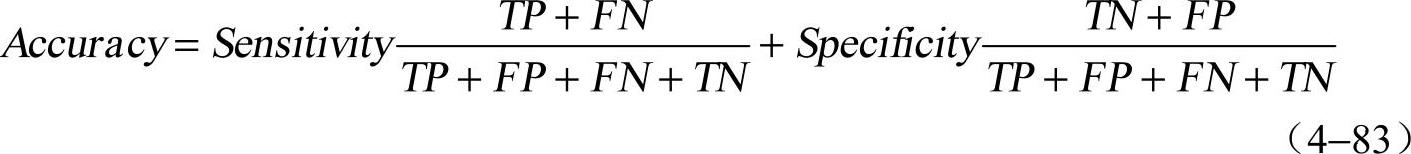
上述各种基本指标,从各个角度对模型的表现进行了评估,在实际业务应用场景中,可以有选择地采用其中的某些指标(不一定全部采用),关键要看具体的项目背景和业务场景,针对其侧重点来选择。
另外,上述各种基本指标看上去很容易让人混淆,尤其是与业务方讨论这些指标时更是如此。而且这些指标虽然从各个不同角度对模型效果进行了评价,但指标之间是彼此分散的,因此使用起来需要人为地进行整合。
作为示例,图4-16展示了某案例中各分类算法正确率的评估图。
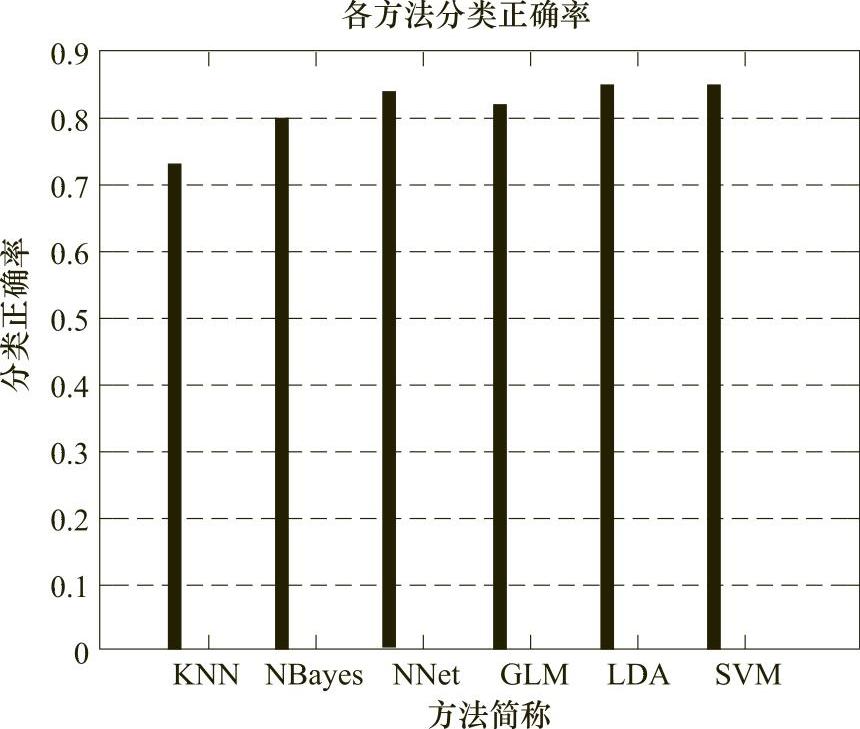
图4-16 各分类算法的正确率评估图
2.ROC曲线
ROC曲线是一种有效比较(或对比)两个(或两个以上)二元分类模型(Binary Model)的可视工具,ROC(Receiver Operating Characteristic,接收者运行特征)曲线来源于信号检测理论,它显示了给定模型的灵敏性(Sensitivity)、真正率与假正率(False Positive Rate)之间的比较评定。给定一个二元分类问题,我们通过对测试数据集的不同部分所显示的模型可以正确识别“1”实例的比例与模型将“0”实例错误地识别为“1”的比例进行分析,来进行不同模型的准确率的比较评定。真正率的增加是以假正率的增加为代价的,ROC曲线下面的面积就是比较模型准确度的指标和依据。面积大的模型对应的模型准确度要高,也就是要择优应用的模型。面积越接近0.5,对应模型的准确率就越低。
图4-17是两个分类模型所对应的ROC曲线图,其横轴是假正率,其纵轴是真正率,该图同时显示了一条对角线。ROC曲线离对角线越近,模型的准确率就越低。从排序后的最高“正”概率的观察值开始,随着概率从高到低逐渐下降,相应的观察群体里真正的“正”群体则会逐渐减少,而假“正”真“负”的群体则会逐渐增多,ROC曲线也从开始的陡峭逐渐变为水平。图中最上面的曲线所代表的神经网络模型(Neural)的准确率就要高于其下面的曲线所代表的逻辑回归模型(Reg)的准确率。
要绘制ROC曲线,首先要对模型所做的判断即对应的数据排序,把经过模型判断后的观察值预测为正(1)的概率从高到低进行排序(最前面的应该是模型判断最可能为“正”的观察值),ROC曲线的纵轴(垂直轴)表示真正率(模型正确判断为正的数量占实际为正的数量的比值),ROC曲线的横轴(水平轴)表示假正率(模型错误判断为正的数量占实际为负的数量的比值)。具体绘制时,要从左下角开始,在此真正率和假正率都为0。按照刚才概率从高到低的顺序,依次针对每个观察值实际的“正”或“负”进行ROC图形的绘制。如果它是真正的“正”,则在ROC曲线上向上移动并绘制一个点;如果它是真正的“负”,则在ROC曲线上向右移动并绘制一个点。对于每个观察值都重复这个过程,(按照预测为“正”的概率从高到低的顺序来绘制),每次对实际为“正”的在ROC曲线上向上移动一个点,对实际为“负”的在ROC曲线上向右移动一个点。当然,很多数据挖掘软件包已经可以自动实现对ROC曲线的展示,所以更多时候只是需要知道其中的原理,并且知道如何评价具体模型的ROC曲线即可。
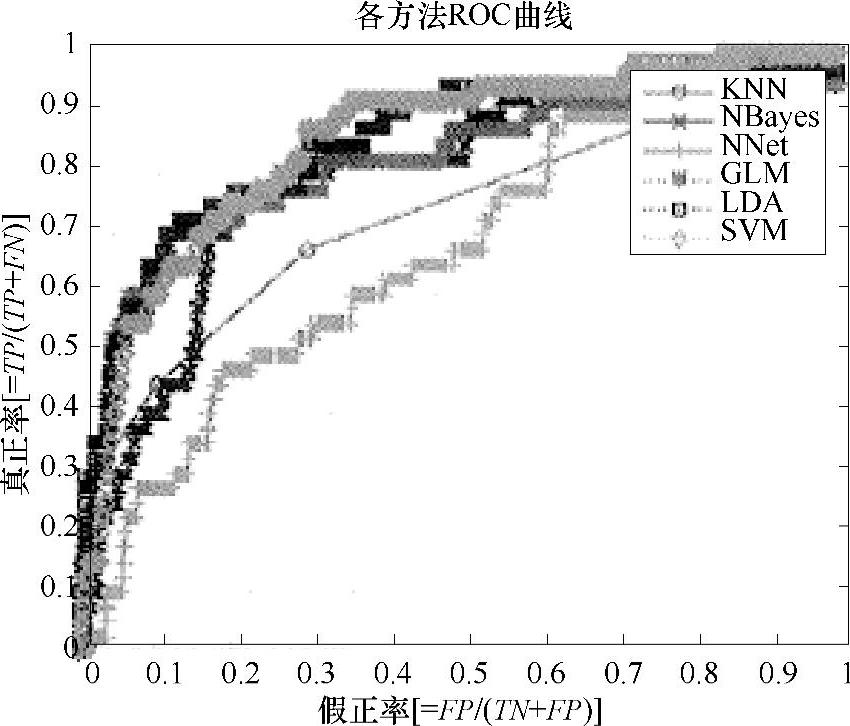
图4-17 两个分类模型所对应的ROC曲线图
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。