



索引(concordance),又称词语索引,或称语境中的关键词(Key Word In Context,简称KWIC),指逐行列举检索词在语料库中发生的片段,通常是检索词左右文字构成的上下文语境(如图4.1)。Sinclair在他经典的著作Corpus, Concordance, Collocation(《语料库、索引与搭配》)中给予索引较为权威的定义:索引是某词汇形式在文本环境中出现的集合,并在该词汇形式被检索时列出其在文本中出现的位置(Sinclair 1991:23)。

图4.1 BNC学术子库中索引词findings的部分索引行
索引是语料库研究中具有代表性的操作之一。尽管索引工具可以进行多词短语与语法标注的检索,但是检索词通常是单一的单词。一般来说,操作者可以自定义语境的宽度,包括检索词语左侧语境的宽度和检索词语右侧语境的宽度,宽度可以以词数为单位定义,也可以以字符数为单位定义。当检索词语的主要搭配词在左侧语境中,则可以设定更宽的左侧语境,反之则可以设定更宽的右侧语境。此外,Tribble(2010)总结了三种处理索引行的方式:排序(sorting)、取样(sampling)和调整(refining)。
排序是指索引行可以按照检索词自身、左侧词语或右侧词语的字母,正序或逆序排列,这样研究者可以更好地观察检索词的使用规律。例如,图4.2是图4.1索引行按照左侧第一个词的字母顺序排列的,图4.3是图4.1索引行按照右侧第一个词的字母顺序排列的。通过图4.2,我们发现,findings最多的前置词是these和the,这表明findings的使用较多指代前文提及的结果;其次,laboratory和research出现的频率高于其他词,这表明findings在语境中多涉及 “实验室”和“研究”的发现。通过图4.3,我们同样发现findings常与介词from和of连用,可见findings在使用中限定指及范围。另一个规律是findings右侧的部分对findings进行评价,一般使用be动词或实义动词(如indicate、suggest、show)。

图4.2 findings的部分索引行按照左侧第一个词的字母正序排列

图4.3 findings的部分索引行按照右侧第一个词的字母正序排列
取样可以有效减少索引行过多带来的信息处理压力。当检索产生过多的索引行时,Tribble(2010)建议我们可以通过三种方式进行处理。第一种方式是减少语料内容。我们在BNC中检索into会得到157,925个索引行。显然,这些索引行的信息量是庞大的,或许是超出我们得出语言结论所需要的数量。Biber(1990)发现,针对类似into这样的单个词汇检索,百万词符以上规模的语料库提供的索引行信息其实是过剩的。因此,我们可以改用BNC缩减版(BNC Baby)以减少语料内容,同样对into进行检索,BNC缩减版的检索结果就降低到了5,982条。可见,这种方法大大提高了可操作性。第二种方式是可以在所获索引行中进行随机抽样(现有部分语料库索引工具可以进行指定数量的随机抽样)。第三种方式是限制检索(restricted search),即限定目标检索的条件。例如,Jiang & Wang(2018)考察了学术论文中指示代词this使用的学科差异,分析this后面不带名词、伴随名词以及伴随名词的类别等。他们使用自建多学科学术论文语料库,通过AntConc软件检索this,然后再分析索引行。但是这里存在一个问题,即this的使用较为普遍,产生的索引行数量过多。因此,他们缩小了搜索范围,只关注谓语独立句首的this使用,从而减少了索引行过多带来的信息负担。
此外,值得注意的是,在图4.1、4.2、4.3中,我们选择了30个索引行。Sinclair(1999)认为,因为丰富的检索能够产生成百上千的索引行,因此我们可以随机选择30个索引行来观察语言使用的规律,然后再选择另外30个索引行,发现新的规律,直到额外的30个索引行不会产生新的规律为止。同样,梁茂成(2016)认为,索引分析是一项需要极大耐心和敏锐观察力的工作,也是验证语言研究者直觉的过程。分析过程中可形成各种假设,然后加以验证、修正、再验证、再修正,直至形成最完善和系统的描述。Sinclair(2003)建议索引行的解读按照扩展意义单位的方法进行,分析从右至左,由近及远,分别观察搭配、类联接、语义倾向和语义韵。这里,笔者引用Sinclair(2003:57-58)用以举例的incur索引行以及他提出的疑问式程序,从而更好地理解如何从右至左、由近及远地观察索引行。
在图4.4中,先浏览紧靠incur右侧的单词,它们极有可能是incur的施物对象,告诉我们“哪些事物常被招致和引起”。我们找到这些目标词汇,然后根据它们的含义进行归类,再分析目标词汇的前置限定词。如有可能的话,再关注目标词汇的其他限定词和修饰语。

图4.4 Sinclair(2003)用以举例的incur索引行
观察这些修饰形容词,思考它们传递的语言含义是积极的还是消极的;再浏览目标词汇的名词修饰语、所在的介词词组或者其他的语言结构,并思考它们是否也传递某种语言含义。
接下来,观察incur左侧的词汇。浏览incur左1、左2、左3的词汇,再考察是否有涉及时态和语态的动词、副词和连词因素。
当我们发现incur左1的位置常出现to时,观察to的使用与何种含义相连,从而总结incur的上下文语境。
整体而言,阅读和分析索引行通常包含七个步骤(Sinclair 2003;Tribble 2010):
第一步,初步了解(initiate)。
观察检索词的左侧或右侧的词汇,尝试找到某种显著的规律。Hyland & Jiang(2017b)在自建的期刊论文语料库中搜索数字,手动排除非学术引用形式后,得到引用形式的索引行(部分如图4.5)。于是我们很快就能够发现一些最为显著的规律,比如“姓氏+(年份)”。(https://www.xing528.com)
第二步,粗略解读(interpret)。
Sinclair(2003)阐述道,该步骤主要是观察反复出现的词汇形式,试图找到能够关联这些或者大多数词汇形式的一般性概论。我们可以关注它们是否是相同的词类,或者是否含有相同的含义。就图4.5而言,我们可以初步总结出,学术英语写作通常使用“姓氏+(年份)”来陈述或报告引用的文献,这里既不是用名字也不是用“首字母缩写+(年份)”的形式。
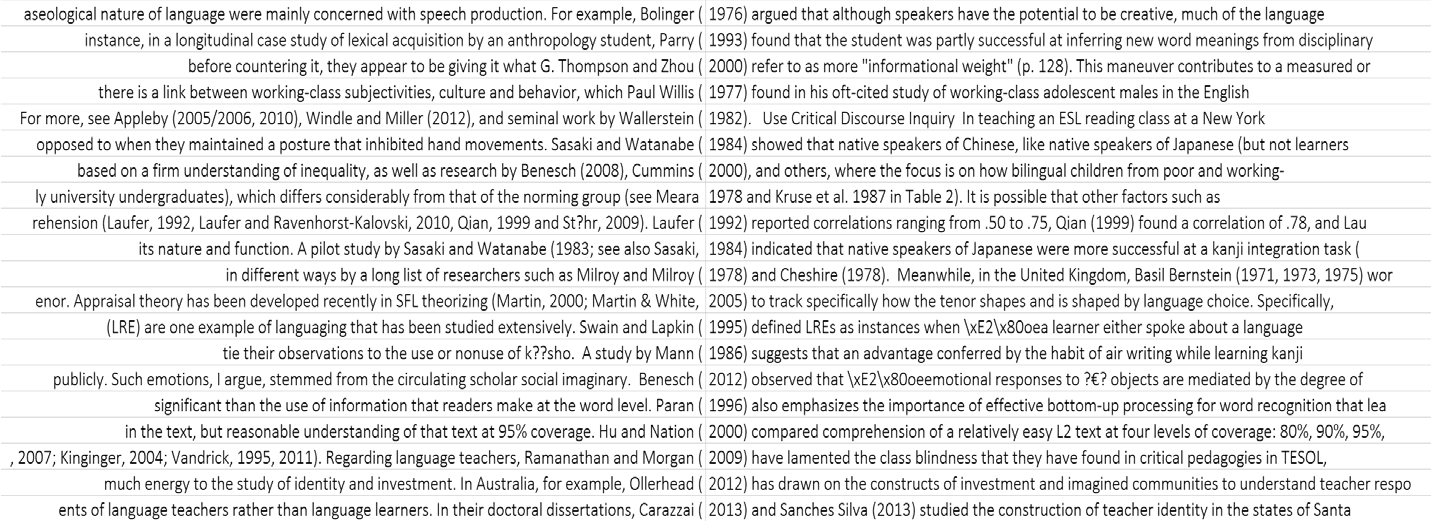
图4.5 Hyland & Jiang(2017b)自建语料库中学术引用的索引
第三步,仔细确认(consolidate)。
在这一步骤中,我们跳出检索词,查看左右文字,观察是否有其他的规律可以提炼。在图4.5中,还发现一系列动词(如argue、find、refer to等)与“姓氏+(年份)”连用,形式为“姓氏+(年份)+动词”。
第四步,列明报告(report)。
经过前三个步骤的观察和解读之后,列明得到的发现。继上述案例描写后,我们可以逐一记录观察到的“姓氏+(年份)”之后的动词,并在报告中列明:
学术引用形式:姓氏+(年份)+动词
动词选择:argue、find、refer to、show、report、indicate、define、suggest、observe、emphasize、compare、lament、draw on、study
第五步,语境回顾(recycle)。
该步骤要求研究者再一次回顾检索词的上下文语境,进一步观察上述步骤的发现。我们在图4.5中浏览扩展语境时发现在学术引用之前有时添加for example。例如,For example, Bolinger(1976)argued that although speakers have the potential to be creative, much of the language…和In Australia, for example, Ollerhead(2012)has drawn on the constructs of investment and imagined communities to understand teacher…。
第六步,结果总结(result)。
这一步骤将上述观察结果进行记录和总结,用于后续研究的分析和对比。例如:
学术引用形式:姓氏+(年份)+动词
动词选择:argue、find、refer to、show、report、indicate、define、suggest、observe、emphasize、compare、lament、draw on、study
扩展语境:for example+姓氏+(年份)+动词
第七步,过程重复(repeat)。
这一步骤并不意味着索引行阅读和分析的结束,而是使用更多的语料重复上述步骤。这样,研究者能够检验、扩展、调整或修正上述步骤的观察和概论,也可以对潜在不确定的观察进行印证。比如,在图4.5中,我们发现了“姓氏+(年份)+动词”中的动词时态具有多样性的特点,有过去时、现在时、现在完成时。但是由于目前索引行个数有限,难以作出规律性的总结,所以研究者可以加载新的语料然后重复上述过程,以期得出规律性的结论。有意思的是,Hyland & Jiang(2017b)基于大量索引行,发现学术引用中现在时的使用比例增加,而过去时的比例缩减。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。