



【摘要】:目前,狭义的分布式计算框架是指“Google的Map/Reduce并行计算框架”。图5-51 MapReduce框架图MapReduce模型适用于大规模、可并发的任务处理,可以处理大量结构化、半结构化和非结构化数据,但该模型任务处理的实时性并不高,这主要是由于计算过程中需要大量分布式数据访问。相比于传统MapReduce框架,该框架更适用于迭代较多的机器学习和数据挖掘运算。
前面谈到了分布式文件系统,实现了分布式架构中大量数据的存储实现。那么这么多的数据只是实现了存储还是远远不够的,要对数据进行“计算”才能让数据“活”起来。
分布式计算是把网络上分布的资源汇聚起来,完成大规模的、复杂的计算和数据处理任务。分布式计算以分布式的方式把巨大的计算任务分割成许多足够小的单元,每个单元可以在单机能够承受的条件下执行,降低了单个节点配置要求的同时,大幅提升计算并发度和计算效率。
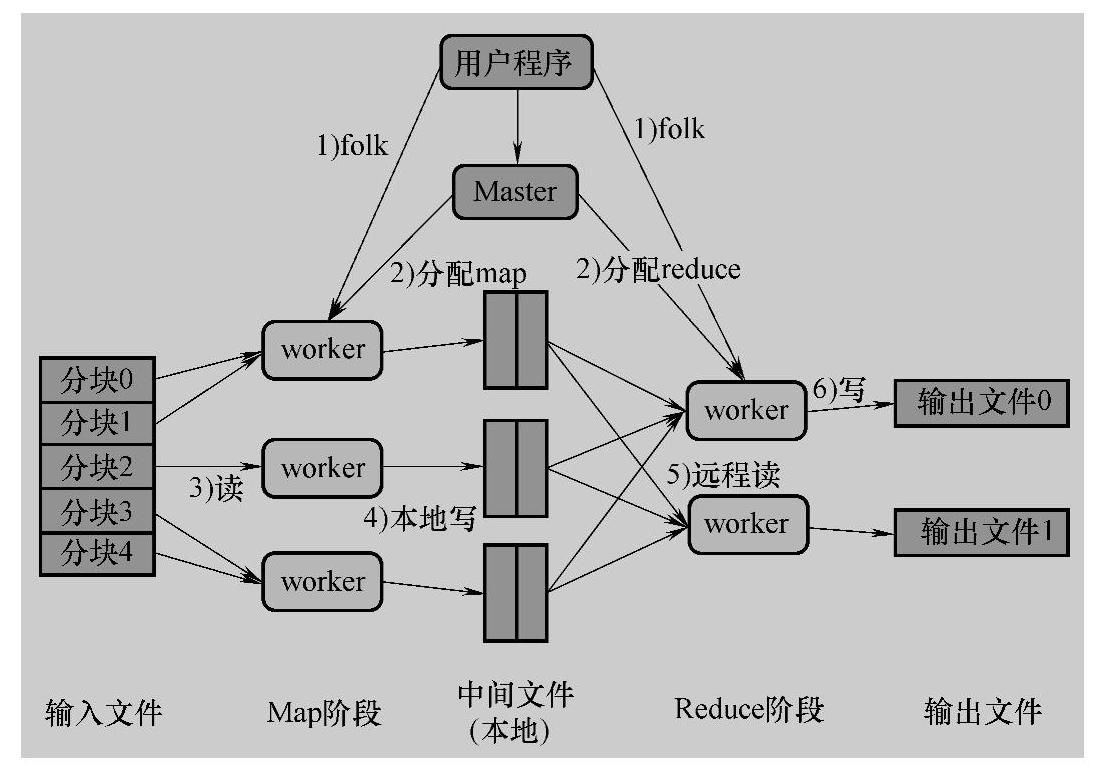
目前,狭义的分布式计算框架是指“Google的Map/Reduce并行计算框架”。Ma-pReduce框架采用函数式编程思想,把一个计算分成Map和Reduce两个计算过程,利用一个输入key-value对集,来产生一个输出key-value对集。顾名思义,Map就是将一个任务分解成多个小的子任务,然后把每个小的计算任务分配给集群各个计算节点,并一直跟踪每个计算节点的进度决定是否重新执行该任务,Reduce就是最后收集每个节点上的计算结果汇总获得最终计算结果并输出,如图5-51所示。
 (https://www.xing528.com)
(https://www.xing528.com)
图5-51 MapReduce框架图
MapReduce模型适用于大规模、可并发的任务处理,可以处理大量结构化、半结构化和非结构化数据,但该模型任务处理的实时性并不高,这主要是由于计算过程中需要大量分布式数据访问。一些框架(如Spark)将缓存引入到分布式计算框架,采用基于弹性分布式数据集的内存分布式并行计算框架,通过对数据进行缓存,减少数据重复加载时间,提高整体计算效率。相比于传统MapReduce框架,该框架更适用于迭代较多的机器学习和数据挖掘运算。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。