



面对新的数据特征,在数据架构的数据整合环节需要解决多样化的数据存储和处理问题。逻辑数据模型建设时需要考虑如何兼容多样化数据处理混合架构,在搭建数据整合平台时需要结合大数据处理技术解决原有结构化数据存储与处理的短板。
1.互联网金融数据整合特征
从数据整合层面分析,数据具备如下特点:
1)互联网金融多样化的数据包括了半结构化和非结构化数据,这些数据需要被检索和分析,并且需要与传统金融数据(一般是结构化数据)进行整合;因此在数据整合环节,要求数据整合平台必须具备处理多样化数据存储、检索、关联等的功能。
2)基于互联网的行为分析大多需要支持智能化实时营销需求,时效性要求很高,在数据整合环节构建实时分析平台时需要考虑使用基于内存的流计算技术。
3)互联网金融会产生大量低价值密度的信息,这些信息不仅量大,而且产生速度快,对于这些数据需要使用成本更低的历史数据归档平台进行存储。
4)互联网金融产生了新的渠道信息、虚拟账户信息、非金融产品信息、合作方信息、潜在客户信息、客户虚拟识别信息等,这些信息在传统线下业务的数据仓库主题模型和数据标准中不能全覆盖,需要对原有的主题模型以及数据标准进行补充完善,实现互联网金融业务和传统线下业务的数据整合。
2.推动融合互联网金融的逻辑数据仓库架构设计(见图4-17)
基于上述数据特征,我们不难发现,互联网金融无论从数据本身的多样性、还是从数据处理技术的多样性来看,都直接推动了传统数据仓库向逻辑数据仓库的转型,形成从传统数据仓库转变为由多种技术整合的逻辑化数据仓库(大数据整合平台)的概念,如图4-17所示。
在银行传统的数据整合平台中,数据仓库领域一般采用的都是支持OLAP处理特性的关系型数据库,从保证处理性能线性增长的角度常常采用支持MPP架构的数据库。同样,在历史数据存储和ODS平台建设上也部分采用了MPP架构的数据库。(https://www.xing528.com)
虽然从某种意义上讲MPP架构也属于分布式处理系统,但是其数据存储、分布方式和Hadoop有区别。
随着Hadoop技术的发展,特别是spark的内存加速和对SQL处理的兼容,在未来数据整合平台部署中会出现三种类型的分布式处理:
1)沿用传统的MPP架构,将Hadoop存储的大数据信息通过外部表定义的方式,实现与MPP架构的关联访问。
2)出现基于Hadoop底层分布式架构的类MPP关系型数据库引擎。
3)由纯Hadoop架构处理所有数据类型。
这三种架构都属于分布式架构,而且将在不同的银行系统架构中短期并存。
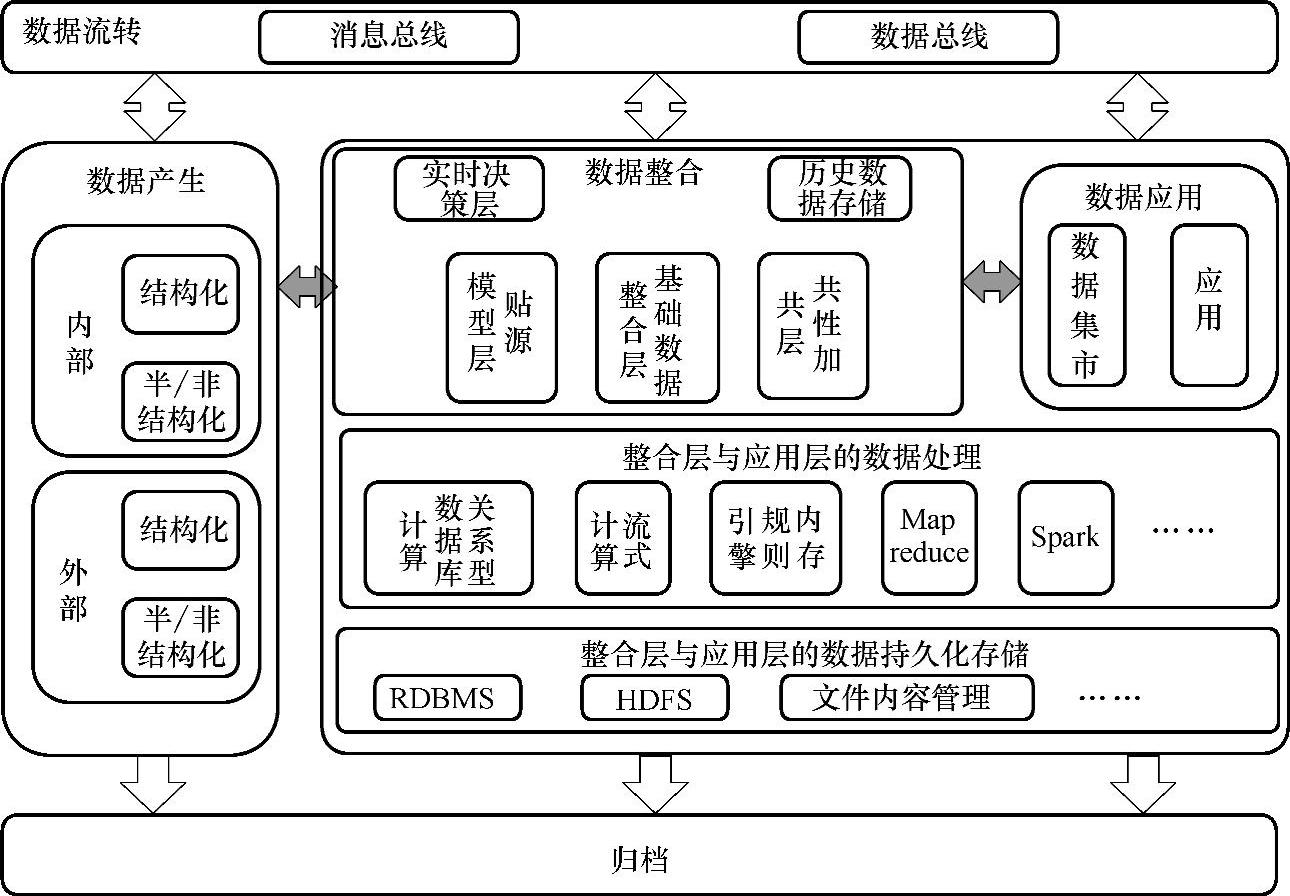
图4-17 逻辑数据仓库图
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。