



在对基于Agent的辩论谈判过程中的社会制度作了较为详细的研究之后,可以结合Agent所处的社会关系和角色,对其在这样的社会性环境下如何进行辩论谈判提出相关的策略及模型,以更进一步地完善本章所做的研究工作。
有关社会学理论认为,整个社会结构由许多不同的网络构成,而每个网络又都由许多不同的节点构成。其中,每个网络代表一种社会关系,每个节点代表一个社会成员,节点与节点之间的连接规则(即映射关系)代表这两个社会成员在这个社会关系中所应遵守的制度,并且每个社会成员在这个社会关系中各自应充当一定的角色,具有一定的权利和义务[1]。
对作为人工智能的Agent来说,由于其具有类似于人的信念、意图、愿望等内在属性,可将每个Agent视为一个具有多个不同社会关系网络的社会成员,所有Agent和社会关系网络构成多Agent社会。其中的Agent为了实现各自及共同的目标,通过在每个社会关系中扮演不同的角色,遵守属于其中的规则,从而在其所具有的这种社会关系中承担一定的权利和义务,进而完成某个行为,发挥其所具有的功能。
为便于说明,考虑如图5-2所示的例子。其中,Agent α、Agent β、Agentγ都是多Agent社会中的成员,Agent α和Agent β之间是工作关系,同时Agent α和Agentγ之间还存在学校关系。Agent α在工作关系中所承担的角色是公司员工,具有的权利如要求及时发工资等,具有的义务有按时完成工作等,遵守的规则是公司制定的各项制度,与此同时,其还在学校关系中承担学生的角色,具有的权利有要求老师按时批改作业等,具有的义务有按时完成作业等,遵守的规则是学校制定的各项制度。此外,Agent β和Agent β也还各自在其其余的社会关系中承担一定的角色,还可以进一步将此网络图拓展。
图5-2 Agent社会性举例
5.3.1 策略及模型
处于某种社会关系中并承担其中某个特定角色的Agent在完成某个特定行为的同时,常常会因为其同时属于其余某种或某些社会关系中的某个特定角色而与之产生冲突。这时候,为了更好地做出决策与达成一致,需要寻找较为有效的谈判方式来解决冲突,而基于辩论的谈判方式由于能在此时的信息不对称条件下给谈判对手带来其有可能忽略的信息,因此,其作用显得尤为突出,对其进行策略及模型构建也显得极其重要。
在建立策略及模型之前,先对多Agent所构成的社会中的成员的属性及相关集合作出如下定义[2]:
①Φ={Agent α,Agent β,Agentγ,…}表示所有Agent的集合;
②Ψ={Ru1,Ru2,Ru3,…}表示以上Agent所应遵守的社会制度集合;
③Σ={Rl1,Rl2,Rl3,…}表示以上Agent所具有的社会关系集合;
④Ω={Ro1,Ro2,Ro3,…}表示以上Agent在整个多Agent社会中所承担的角色集合;
⑤Ξ={d1,d2,d3,…}表示以上Agent的所有行为集合。
通过以上定义,可以看出,对处于某种社会制度中的某两个Agent(如Agent α和Agent β,Agent α、Agent β∈Φ)来说,如果Agent α要求Agent β完成某行为d(d∈Ξ),而Agent β表示拒绝的话,Agent α和Agent β可能为此进行谈判,而传统的提议和反提议的谈判方式并不能使作为人工智能且具有一定思维、信念和意图等内在属性的Agent谈判对手信服,因此难以解决问题。Agent α和Agent β陷入谈判僵局。此时,为了更好地做出决策、达成一致并解决冲突,Agent α会根据其在所处社会关系中承担的角色及相关的社会制度提出相关的辩论,以使Agent β接受并完成此行为。先定义相关符号及关系表达式如下:
①Arg{d(α→β)}表示此辩论,Rlα→βd (Rlα→βd ∈Σ)表示Agent α和Agent β在此辩论中所具有的社会关系,Roαd、Roβd(Roαd、Roβd∈Ω)表示Agent α和Agent β所承担的角色,Ruα→βd (Ruα→βd ∈Ψ)表示Agent α和Agent β所应遵守的社会制度,Rα→βd 、Oα→βd 表示Agent α对Agent β来说享有的相应的权利和义务;
②In:Φ×Σ×Ω×Ξ表示处于某种社会关系的某个Agent为完成某个行为而承担的相应的角色,Rel:Ψ×Σ表示其此时应当遵守的规则与这种社会关系的从属关系。
综合以上各项,可将此辩论表示为如公式(5-15)的多元函数,其中的各项元素关系符合公式(5-16)、(5 17)和(5 18):
同理,Agent β也可向Agent α提出反辩论,表示为公式(5-19),其中的各项元素关系符合公式(5-20)、(5 21)和(5 22):
5.3.2 有关策略及模型的决策函数及评价
在对作为社会成员的Agent间的辩论谈判建模(即知道相关的辩论如何产生)后,需要知道有关此模型的决策函数(即被辩论的谈判方如何对此辩论进行评价),从而在完成谈判的同时作出正确决策,最终解决冲突并实现有意义的合作,模型中辩论和反辩论的本质一样,因此,以公式(5-15)为例对其决策函数及评价进行研究。
从Agent α向Agent β提出的辩论的模型可以看出,Agent β在辩论谈判过程中有关此辩论模型的决策函数主要应该包括对模型中所涉及的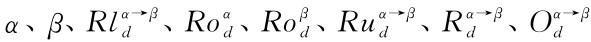 这八个元素的综合评价。这里主要考虑谈判双方所具有的社会性,因此,对元素α、β的评价等价于对其各自所处的社会关系及在其中承担的角色的综合评价,计算如公式(5-23)和(5 24);对其所应遵守的规则的评价等价于为完成行为d而需要承担的一定的权利和义务的综合评价,可以看出,Agent α完成行为d享有一定的权利,即完成此行为可能会给其带来的一定的利益,以函数Benefit(d)表示,而所应当履行的义务则是不完成此行为可能会给其带来的一定的惩罚,以函数Penalty(d)表示,由于是惩罚,这里取其负值相加。具体计算如公式(5-25):(https://www.xing528.com)
这八个元素的综合评价。这里主要考虑谈判双方所具有的社会性,因此,对元素α、β的评价等价于对其各自所处的社会关系及在其中承担的角色的综合评价,计算如公式(5-23)和(5 24);对其所应遵守的规则的评价等价于为完成行为d而需要承担的一定的权利和义务的综合评价,可以看出,Agent α完成行为d享有一定的权利,即完成此行为可能会给其带来的一定的利益,以函数Benefit(d)表示,而所应当履行的义务则是不完成此行为可能会给其带来的一定的惩罚,以函数Penalty(d)表示,由于是惩罚,这里取其负值相加。具体计算如公式(5-25):(https://www.xing528.com)
其中,λ1、λ2、λ3及μ、ν分别表示就Agent β自身有关谈判的知识来看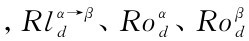 所占权重及
所占权重及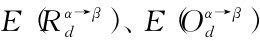 所占权重。
所占权重。
综上,可将此决策函数D(d)视为以行为d为变量的函数,其值可通过公式(5-26)计算得到:
5.3.3 算例及分析
为便于计算和说明,以下假设数据中权重的取值范围均为0—1之间的一位小数,值的取值范围均为1—10之间的一位整数,谈判中只考虑辩论,且以谈判只进行一轮辩论为例进行举例和模拟。
考虑图5-2所示的例子,假设Agent β和Agentγ分别要求Agent α同时完成工作w和作业h,由于时间或其他方面的原因而造成冲突的Agent α都不能接受,表示拒绝,Agent β和Agentγ为说服Agent α同时向其提出相关的辩论,可分别表示为公式(5-27)和(5 28):
在这个时候,Agent α需要对以上两个辩论做出评价,以做出决策。假设Agent α只具有工作和学校关系这两个社会关系,首先需要通过以上决策函数计算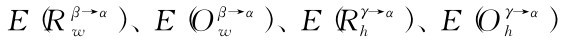 的值。
的值。
为简化计算,分别将其对有关Agent β的权利的评价(即相应的利益函数)只分解为对可能得到的奖金和升职这两个指标的综合评价,将其对有关Agent β的义务的评价(即相应的惩罚函数)只分解为对可能扣除的工资和降职这两个指标的综合评价,给出假设的权重和值并计算得出相应的值,具体见表5-4。
表5-4 E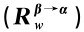 和E
和E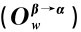 值
值
其次,将其对有关Agentγ的权利的评价(即相应的利益函数)只分解为对可能得到的老师奖励和家长奖励这两个指标的综合评价,将其对有关Agentγ的义务的评价(即相应的惩罚函数)只分解为对可能受到的老师批评和家长批评这两个指标的综合评价,给出假设的权重和值并计算得出相应的值,具体见表5-5。
表5-5 E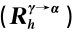 和E
和E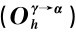 值
值
在以上基础上,分别给出Agent α有关Agent β和Agentγ的相应的假设的λ1、λ2、λ3及μ、ν值,具体见表5-6。
表5-6 Agent β和Agentγ的λ1、λ2、λ3及μ、ν值
将表5-4、表5-5中的评价值以及表5-6中给出的假设数据应用于公式(5-27)中,可计算出相应的D(w)、D(h)值:
D(w)=0.4+(1+0.4)×(0.4+0.7)+2×(0.5×5.4-0.5×4.3)=3.04
D(h)=0.6+(1+0.6)×(0.6+0.6)+2×(0.4×5.7-0.6×4.8)=1.32
(5-29)
根据公式(5-29)的计算结果,Agent α会选择接受Agent β提出的辩论,即完成工作w,而拒绝Agentγ提出的辩论,即拒绝完成作业h。
[1] S.Russell and P.Norvig,Artificial intelligence:a modern approach,Prentice Hall,1995,pp.10-78.
[2] A.S.Rao and M.P.Georgeff,Social plans:preliminary report,In E.Werner and Y.Demazeau,editors,Decentralized AI 3—Proceedings of the Third European Workshop on Modelling Autonomous Agents and Multi-Agent Worlds(MAAMAW-91),Elsevier/North Holland,1992,pp.57-76.
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。