



3.6.1 威胁、奖励、反驳和申辩的模型举例
1.威胁模型举例
在Agent α与Agent β的辩论谈判的合作伙伴选择过程中,作为买方的Agent α向作为卖方的Agent β所下订单中的购买条款可能与Agent β的预期相差较远,因此,Agent α如果要求Agent β接受订单(Acpt Ord),将会遭到Agent β的拒绝。此时,Agent α可能会提出诸如选择另外卖方(Chos Ano Sel)的威胁而迫使Agent β修改其自身有关此辩论谈判的知识,以尽快接受Agent α的购买条款,因为根据Agent α有关此辩论谈判的知识和经验判断,这么做将会对Agent β造成重大损失,而这对Agent β来说是不愿意接受的。这种威胁属于威胁的第一种形式。Agent α提出的威胁具有如下三个主要元素:
①K=〈¬Acpt Ord→Chos Ano Sel〉,K∈Kα;
②I=〈Acpt Ord〉,I∈Iα;
③I′=〈¬Chos Ano Sel〉,I′∈Iα。
因而,对威胁方Agent α来说,Agent α向Agent β提出的威胁可形式化为:Threat(α⇒β)=〈α,β,{¬Acpt Ord→Chos Ano Sel}, Acpt Ord,¬Chos Ano Sel〉
在前述有关Agent α与Agent β在辩论谈判的合作伙伴选择过程的僵局中,如果买方Agent α选择另外卖方(Chos Ano Sel),将对原来卖方Agent β不利,鉴于购买条款与Agent β预期相差较远,此时,Agent β将会提出诸如联合其余卖方不供应相关产品给Agent α(¬Get Prod)等的威胁,从而迫使Agent α转而修改其自身有关此辩论谈判的知识,因为根据Agent β有关此辩论谈判的知识和经验判断,这么做将会对Agent α造成重大损失,而这对Agent α来说是不愿意接受的。这种威胁属于威胁的第二种形式。Agent β提出的威胁具有如下三个主要元素:
①K=〈Chos Ano Sel→¬Get Prod〉,K∈Kβ;
②I=〈¬Chos Ano Sel〉,I∈Iβ;
③I′=〈Get Prod〉,I′∈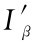 。
。
因而,对威胁方Agent β来说,Agent β向Agent α提出的威胁可形式化为:
Threat(β⇒α)=〈β,α,{Chos Ano Sel→¬Get Prod}, ¬Chos Ano Sel,Get Prod〉
2.奖励模型举例
在前述有关Agent α与Agent β在辩论谈判的合作伙伴选择过程的僵局中,为了保证双方的利益及谈判的顺利进行,Agent α可能会提出从Agent β处购买一定的另外的相关产品(Buy Oth Pro)的奖励,从而促使Agent β修改其自身有关此辩论谈判的知识,以接受Agent α的购买条款。因为根据Agent α有关此辩论谈判的知识和经验判断,这么做将会对Agent β有利,而这对Agent β来说是愿意接受的。这种奖励属于奖励的第一种形式。Agent α提出的奖励具有如下三个主要元素:
①K=〈Accept Ord→Buy Oth Pro〉,K∈Kα;
②I=〈Accept Ord〉,I∈Iα;
③I′=〈Buy Oth Pro〉,I′∈Iα。
因而,对奖励方Agent α来说,Agent α向Agent β提出的奖励可形式化为:
Reward(α⇒β)=〈α,β,{Accept Ord→Buy Oth Pro}, Accept Ord,Buy Oth Pro〉
在前述有关Agent α与Agent β的辩论谈判的合作伙伴选择中,Agent α为保证其自身利益最大化,可能会提出中止交易(Abort Deal),从而使谈判陷入僵局。此时,为了保证双方的利益及谈判的顺利进行,Agent β可能会提出赠送一定的相关产品(Free Oth Pro)给Agent α的奖励,从而促使Agent α转而修改其自身有关此辩论谈判的知识,以达成一致。因为根据Agent β有关此辩论谈判的知识和经验判断,这么做将会对Agent α有利,而这对Agent α来说是愿意接受的。这种奖励属于奖励的第二种形式。Agent β提出的奖励具有如下三个主要元素:
①K=〈¬Abort Deal→Free Oth Pro〉,K∈Kβ;
②I=〈¬Abort Deal〉,I∈Iβ;
③I′=〈Free Oth Pro〉,I′∈Iβ。
因而,对奖励方Agent β来说,Agent β向Agent α提出的奖励可形式化为:
Reward(β⇒α)=〈β,α,{¬Abort Deal→Free Oth Pro}, ¬Abort Deal,Free Oth Pro〉
3.反驳模型举例
在前述有关Agent α与Agent β在辩论谈判的合作伙伴选择过程的僵局中,Agent α要求Agent β修改此条款(Modify Order),而Agent β为保证其自身利益最大化,则会表示拒绝,同时,Agent α又不愿意花费更多的成本去寻找其余的卖方。此时,为了保证双方的利益及谈判的顺利进行,Agent α可能会提出诸如其出售条款比同一时段内市场上同类产品的一般出售条款要差(Worse In Market)等同类性质的事实或观点作为正面反驳,从而促使Agent β修改其自身有关此辩论谈判的知识,即修改其出售条款,以完成交易(Deal)。因为根据Agent α有关此辩论谈判的知识和经验判断,这么做将能说服Agent β。这种反驳属于反驳的第一种形式。Agent α提出的反驳具有如下两个主要元素:
①K=〈Worse In Market→Modify Order〉,K∈Kα;
②I=〈Modify Order〉,I∈Iα;
③I′=〈Deal〉,I′∈Iα;
因而,对反驳方Agent α来说,Agent α向Agent β提出的反驳可形式化为:
Rebut(α⇒β)=〈α,β,{Worse In Market→Modify Order}, Modify Order,Deal〉
在前述有关Agent α与Agent β在辩论谈判的合作伙伴选择过程的僵局中,为了保证双方的利益及谈判的顺利进行,Agent α也可能会提出诸如此产品自身存在某些缺陷(Defect In Product)等的事实或观点作为侧面反驳,从而促使Agent β修改其自身有关此辩论谈判的知识,即修改其出售条款,以完成交易(Deal)。因为根据Agent α有关此辩论谈判的知识和经验判断,这么做将能说服Agent β。这种反驳属于反驳的第二种形式。Agent α提出的反驳具有如下两个主要元素:
①K=〈Defect In Product→Modify Order〉,K∈Kα;
②I=〈Modify Order〉,I′∈Iα;
③I′=〈Deal〉,I′∈Iα;
因而,对反驳方Agent α来说,Agent α向Agent β提出的反驳可形式化为:
Rebut(α⇒β)=〈α,β,{Defect In Product→Modify Order}, Modify Order,Deal〉
4.申辩模型举例
在前述有关Agent α与Agent β在辩论谈判的合作伙伴选择过程的僵局中,为了保证双方的利益及谈判顺利进行,Agent α可能会提出其自身(或第三方)以往的曾经跟Agent β在同样条款下完成交易(The Same Deal)的事实的申辩,从而说服Agent β修改其自身有关此辩论谈判的知识,并进而完成交易(Deal)。因为根据Agent α有关此辩论谈判的知识和经验判断,这么做将能说服Agent β。这种申辩属于申辩的第一种形式。在这里,Agent α提出的申辩具有如下两个主要元素:
①K=〈The Same Deal→Accept Order〉,K∈Kα;
②I=〈Accept Order〉,I∈Iα;
③I′=〈Deal〉,I′∈Iα。
因而,对申辩方Agent α来说,Agent α向Agent β提出的申辩可形式化为:(https://www.xing528.com)
Appeal(α⇒β)=〈α,β,{The Same Deal→Accept Order}, Accept Order,Deal〉
在前述有关Agent α与Agent β在辩论谈判的合作伙伴选择过程的僵局中,为了保证双方的利益及谈判的顺利进行,Agent α可能会向Agent β提出Agent β以往曾经许下的承诺(Past Promise)的申辩,从而说服Agent β修改自身有关此辩论谈判的知识,以接受Agent α的购买条款。因为根据Agent α有关此辩论谈判的知识和经验判断,这么做将能说服Agent β。这种申辩属于申辩的第二种形式。在这里,Agent α提出的申辩具有如下两个主要元素:
①K=〈Past Promise→Accept Order〉,K∈Kα;
②I=〈Accept Order〉,I∈Iα;
③I′=〈Deal〉,I′∈Iα。
因而,对申辩方Agent α来说,Agent α向Agent β提出的申辩可形式化为:
Appeal(α⇒β)=〈α,β,{Past Promise→Accept Order}, Accept Order,Deal〉
在前述有关Agent α与Agent β在辩论谈判的合作伙伴选择过程的僵局中,为了保证双方的利益及谈判的顺利进行,Agent α可能会向Agent β提出Agent β自身并不知道的利益(Self Value)的申辩,从而说服Agent β修改自身有关此辩论谈判的知识,并进而完成交易(Deal)。因为根据Agent α有关此辩论谈判的知识和经验判断,这么做将能说服Agent β。这种申辩属于申辩的第三种形式。在这里,Agent α提出的申辩具有如下两个主要元素:
①K=〈Self Value→Accept Order〉,K∈Kα;
②I=〈Accept Order〉,I′∈Iα;
③I′=〈Deal〉,I′∈Iα。
因而,对申辩方Agent α来说,Agent α向Agent β提出的申辩可形式化为:
Appeal(α⇒β)=〈α,β,{Self Value→Accept Order}, Accept Order,Deal〉
3.6.2 威胁、奖励、反驳和申辩辩论力度强弱评价模型的算例及分析
从威胁、奖励、反驳和申辩辩论力度强弱的评价模型可以看出,基于Agent的辩论谈判的合作伙伴选择过程中,同一个Agent有可能同时遭受到相同种类的辩论谈判策略,如Agentγ同时遭受到Agent α和Agent β各自都向它提出的威胁的辩论,也有可能同时遭受到不同种类的辩论谈判策略,如Agentγ同时遭受到Agent α和Agent β各自向它提出的辩论,但Agent α提出的是威胁,而Agent β提出的是奖励。在这两种情况下,Agentγ既要能对同种类的辩论谈判策略做出评价和选择,也要能对不同种类的辩论谈判策略做出评价和选择,以选择最佳合作伙伴。因此,为了证明所提出的评价模型的有效性和普适性,需要分别举出相关算例对其进行说明和分析。具体如下:
1.同类辩论谈判策略的评价模型算例及分析
由于威胁、奖励、反驳和申辩辩论力度强弱的评价模型本质上一样,因此,这里主要以奖励为例举出算例并进行分析,即假设在基于Agent的辩论谈判的合作伙伴选择过程中,Agentγ同时遭受到Agent α和Agent β各自向它提出的以奖励作为辩论谈判策略的辩论。此外,鉴于两种奖励类型本质上一样,以下只就前面所提出的有关第一种奖励类型的例子拟定数据并进行分析。
为方便研究,将其中的E(Φα)和E(Φβ)只分解为提出奖励的主体的信用度、以往成功交易的次数和以往交易的满意度这三个主要指标,并给出相应数据和权重,然后计算出E(Φα)和E(Φβ)的值,具体见表3-1。
表3-1 Agentγ通过评价模型计算得到的E(Φα)和E(Φβ)值
然后,将其中的E(Iα)和E(Iβ)分别分解为订单中所交易产品的价格、数量和交货期这三个主要指标;将E(I′α )和E(I′β )分别分解为为达成一致而交易的订单以外的产品的价格、数量和交货期这三个主要指标,并给出相应数据及权重,计算得到E(Iα)、E(Iβ)、E(I′α)、E(I′β)的值,具体见表3-2和表3-3。
表3-2 Agentγ通过评价模型计算得到的E(Iα)和E(Iβ)值
表3-3 Agentγ通过评价模型计算得到的E(I′α)和E(I′β)值
综合以上结果,并给出Agentγ中有关E(Φ)、E(I)、E(I′)的权重值ωΦ、ωI、ωI′,具体见表3-4。
表3-4 Agentγ通过评价模型计算得到的E(Φ)、E(I)、E(I′)值及相关的ωΦ、ωI、ωI′值
根据表3-4中的数据分别进行计算,可以得到Agentγ有关Agent α和Agent β向其所提出的这两个奖励的辩论力度的评价值,具体如下:
Vl Str Rw(α⇒γ)=6.8×0.5+9.5×0.3+6.8×0.2=7.61
Vl Str Rw(β⇒γ)=5.5×0.5+10.1×0.3+6.6×0.2=7.10
所以,在Agentγ看来,Agent α对Agentγ提出的奖励的辩论力度比Agent β对Agentγ提出的奖励的辩论力度要强。记为:
Vl Str Rw(α⇒γ)≻Vl Str Rw(β⇒γ)
因此,通过比较,Agentγ将会优先考虑跟Agent α交易,以保证双方利益最大化,并尽快达成一致,完成交易。
2.不同种类辩论谈判策略的评价模型算例及分析
由于对威胁、奖励、反驳和申辩的分类本质上一样,因此,相关的辩论力度强弱的评价模型都可以只取它们的第一种分类为例举出算例并进行分析。所以,假设在基于Agent的辩论谈判的合作伙伴选择过程中,Agentγ同时遭受到Agent α、Agent β、Agentφ、Agentφ各自向它提出的有关合作伙伴的辩论谈判策略,分别为威胁、奖励、反驳和申辩,即可以假设Agent α向Agentγ提出的是威胁,Agent β向Agentγ提出的是奖励,即Agentφ向Agentγ提出的是反驳,Agentφ向Agentγ提出的是申辩。
同样地,为方便研究,将其中的E(Φα)、E(Φβ)、E(Φφ)、E(Φφ)只分解为提出辩论方的信用度、以往成功交易的次数和以往交易的满意度这三个主要指标,并给出相应数据和权重,然后计算出E(Φα)、E(Φβ)、E(Φφ)、E(Φφ)的值,具体见表3-5。
表3-5 Agentγ通过评价模型计算得到的E(Φα)、E(Φβ)、E(Φφ)、E(Φφ)值
并且,将其中的E(Iα)、E(Iβ)、E(Iφ)、E(Iφ)分别分解为订单中所交易产品的价格、数量和交货期这三个主要指标,具体见表3-6。
表3-6 Agentγ通过评价模型计算得到的E(Iα)、E(Iβ)、E(Iφ)、E(Iφ)值
然后,将E(I′α )、E(I′β )、E(I′φ )、E(I′φ )分别分解为为达成一致而交易的订单以外的产品的价格、数量和交货期这三个主要指标,并给出相应的数据及权重,计算得到E(I′α)、E(I′β)、E(I′φ)、E(I′φ)的值,具体见表3-7。
表3-7 Agentγ通过评价模型计算得到的E(I′α)、E(I′β)、E(I′φ)、E(I′φ)值
最后,综合以上结果并给出相关权重,然后在此基础上计算,分别得出各辩论力度值,具体见表3-8。
表3-8 Agentγ通过评价模型计算得到的各辩论力度值
从表3-8得出的Agentγ通过评价模型计算出的各辩论力度值可以得到以下关系:
Vl Str Ap(φ⇒γ)≻Vl Str Th(α⇒γ)≻Vl Str Rw(β⇒γ)≻Vl Str Re(φ⇒γ)
因此,经过比较,Agentγ将会优先考虑Agentφ向其提出的申辩,其次考虑Agent α向其提出的威胁,再次考虑Agent β向其提出的奖励,最后考虑Agentφ向其提出的反驳,从而根据这样的先后顺序来选择最佳的合作伙伴进行交易。从以上分析可以看出,作为卖方的Agentγ可以根据这些知识和经验,对作为买方的Agent α、Agent β、Agentφ、Agentφ同时在合作伙伴阶段向其提出的各种辩论谈判策略进行量化,通过计算后得出相关值,并进行比较分析,进而选择最佳合作伙伴及最佳买方进行交易,从而最终实现合作。
需要说明的是,上述评价模型及算例分析主要都是针对被辩论方来说的,但同样也可以将其运用于辩论方,由其根据自身有关辩论谈判中合作伙伴选择的这些知识,即针对一定的辩论谈判对手,选择在这个阶段来说服其自身认为是最优的辩论谈判策略,即其自身认为是辩论力度最强的威胁、奖励、反驳或申辩,并进而向对方提出,也可以同时向多个辩论谈判对手提出相同或不同的辩论谈判策略,从而在有限的辩论谈判时间内选择出最佳的合作伙伴进行交易,例如,作为买方的Agent α可以在同一时间内选择针对不同卖方的辩论谈判策略,然后向它们提出,这与上一章的基于Agent的辩论谈判协议是一致的。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。