



一、频数表的编制
频数即观察值的个数,频数表(frequency table)是指由组段和频数构成的表格。当观察值个数较多时,为了了解一组同质观察值的分布规律和便于计算统计指标,一般先编制频数分布表,简称频数表。了解频数分布是分析资料的第一步。现举例说明频数表的编制方法。
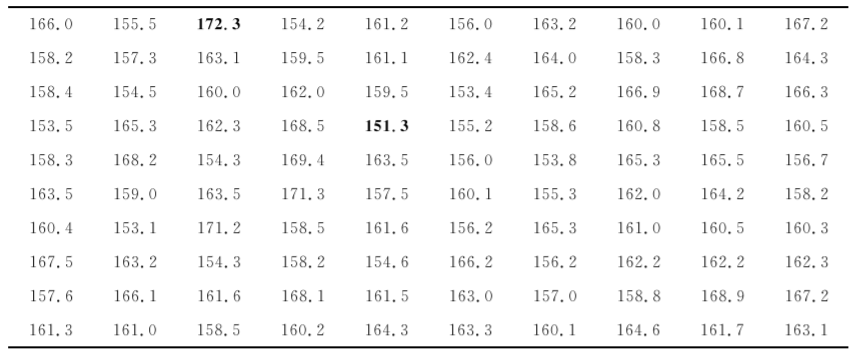
[例7.1]从某地2015年大学生体检资料中随机抽取100名健康女大学生身高(cm)的测量值,资料见表7-1,试编制频数分布表。
表7-1某地2015年100名健康女大学生身高资料
(一) 频数表的编制步骤
1. 求全距(range) 全距又叫极差,是最大值与最小值的差值,用R表示,R=最大值-最小值,本例R=172.3-151.3=21.0(cm)。
2. 确定组距 组距即相邻两组段之间的距离,用i表示。组距的大小根据全距和组数来确定。组数一般设8~15个,以便能显示数据的分布特征。i=R/10,为了方便整理资料和计算,组距一般取整数或合适的小数。本例i=21.0/10=2.1≈2。
3. 划分组段 划分组段是将变量值依次划分若干个段落,这些段落称为组段。各组段的界限应清晰分明,第一组段应包括最小值,最后一组段应包括最大值。各组段的起点和终点分别称为下限和上限,实际组段在每组中只包含下限,不包含上限,因此组段常用各组段的下限及“~”表示,但最后一组段应同时写出下限和上限。
4. 列表划计归组 按确定的组段设计划计表,如表72所示的形式。将原始数据按不同组段归纳、采用划记法如画“正”字计数,清点各组段内的变量值个数即得各组段频数,将各组段频数填入第(3)栏。
表7-2 某地2015年100名健康女大学生身高(cm)的频数分布

现在,频数表的编制一般由计算机完成。计算机编制频数表快速、准确,还可以根据需要随时变换组距和组段。不过前提是必须保证原始数据输入的正确和分组的合理。所以操作者需要熟悉频数表的编制原理和步骤。
(二) 频数分布的特征
频数表资料可进一步编制成图形即直方图。由图71可看出频数分布的两个重要特征:集中趋势(central tendency)和离散趋势(tendency of dispersion)。数据有大有小,但多数集中在中间组段,此为集中趋势;由中间向两边较大或较小的频数分布逐渐减少,此为离散趋势。计量资料的规律性可从集中趋势和离散趋势两个方面进行分析。
(三) 频数分布的类型
常见的频数分布类型有正态分布和偏态分布两种类型。
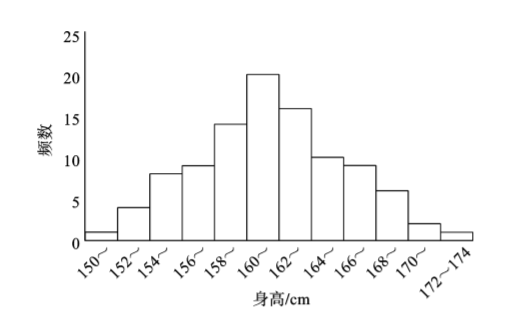
图7-1某地2015年100名健康女大学生身高(cm)的频数分布
1. 正态分布 集中位置(高峰)在中间,左右两侧频数分布大体对称,以集中位置为中心,左右两侧频数分布逐渐减少并完全对称的分布,它是统计学中非常重要的频数分布。
2. 偏态分布集中位置不在中间而偏向一侧,频数分布不对称。根据集中位置所偏的方向,又可将偏态分布分为正偏态(左偏态)分布和负偏态(右偏态)分布,如图7-2所示。
图7-2几种常见的频数分布类型

(四) 频数表的用途
利用频数表可以绘制频数分布图,可以揭示资料的分布特征和分布类型(参见图7-1),便于发现某些特大或特小的可疑值,也便于对数据进行统计分析。
二、描述集中趋势的指标
描述一组同质变量值的集中趋势或平均水平的指标常用平均数(average)。平均数是一组指标,常用的有算术平均数、几何平均数和中位数。
(一) 算术平均数
算术平均数(arithmetic mean)简称均数(mean),是将各观察值相加后除以观察值个数所得的商。总体均数用希腊字母μ表示;样本均数用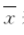 表示。
表示。
1. 适用资料 均数适用于变量值呈正态分布或对称分布的计量资料。如:正常人的某些生理、生化指标;实验室内对同一样品多次重复测量值;从正态或近似正态总体中随机抽取的多个样本均数等。
2. 计算方法
(1) 直接法:将所有观察值相加,再除以观察值的个数n。当n较小(n<50)或运用统计软件计算时用直接法。公式为
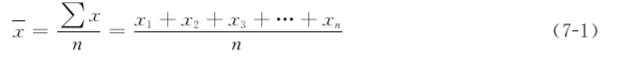
式中:x为样本均数;x1,x2,x3,…,xn为各变量值;∑为求和符号,读作[sigma];n为样本含量。
[例7.2]测定某地6名健康女大学生身高(cm)资料,分别是154.2、162.0、169.4、165.3、154.5、156.2,求均数。
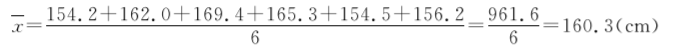
(2) 加权法(weighting method):当资料中出现多个相同观察值时,可将相同观察值的个数(频数f)与该观察值的乘积代替相同观察值逐个相加;当n较大(n≥50)时可先编制频数表,再用加权法计算均数,公式为
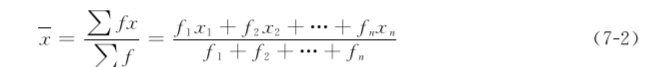
式中:f1、f2、…、fn,分别为第一组段至第n组段的频数;x1、x2、…、xn,分别为第一组段至第n组段的组中值;∑fx为各组段内组中值与频数乘积的总和;∑f=n为总频数。
从表7-3中可以看出,身高在“150~”组段内有1人,在“152~”组段内有4人。同一组段内每个人的身高是不相等的,可取组中值(x)代表该组段每个人的身高,以各组段的组中值乘以相应的频数(f)即fx来代替组段各变量值之和,将各组段的fx相加得到所有变量值之总和,再除以总频数即为均数。组中值=(下限值+上限值)/2,例如第一组段的组中值=(150+152)/2=151,第二组段的组中值=(152+154)/2=153。组中值见表73中的第(2)列。
表7-3某地2015年100名健康女大学生身高(cm)均数的加权法计算
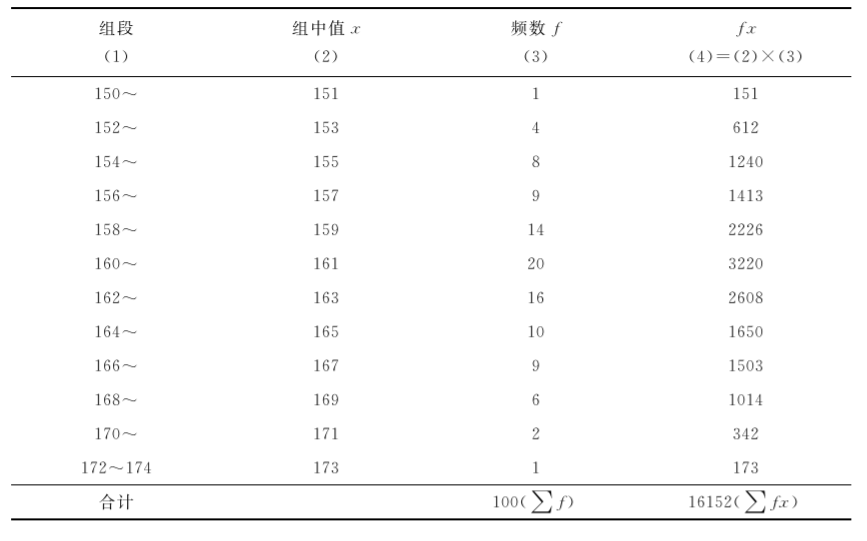
表7-3中各组段内第(2)列组中值x与第(3)列频数f的乘积为第(4)列fx,将第(4)列各组段的fx相加得∑fx。再将此值除以总频数∑f即得100名健康女大学生的平均身高。本例∑fx=16152,∑f=100,将其代入公式(72),得平均数为:

因为各组段频数起到了“权数”的作用,它“权衡”了各组中值由于频数不同对均数的贡献,所以这种计算均数的方法称为加权法。
(二) 几何平均数
几何平均数(geometric mean)又称几何均数。将n个变量值x的乘积开n次方所得的根即为几何均数。用符号G表示。
1. 适用资料 ①变量值呈等比数列的资料,如抗体的滴度、药物的效价、卫生事业发展速度等;②变量值呈倍数关系的资料,如细菌计数、人口的几何级增长等;③变量值的对数值呈正态分布或近似正态分布资料,如正常人体内某些微量元素的含量。
2. 计算方法
(1) 直接法当n较小(n<50)时,直接将n个变量值x1、x2、…、xn的乘积开n次方,公式为

为了方便计算,可将上式变换为
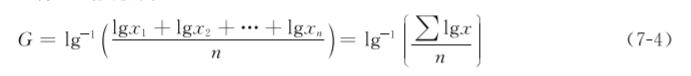
式中:lg-1为求反对数的符号;∑lgx为各变量值的对数值之和,n为样本含量。
[例7.3]2015年某市5名儿童接种某种疫苗后,测定抗体滴度分别为1∶4、1∶8、1∶16、1∶32、1∶64,求抗体平均滴度。
本例为方便计算先求平均滴度的倒数,代入公式(74)中,得到
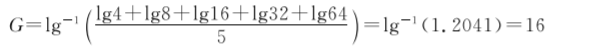
则抗体平均滴度为1∶16。
(2) 加权法:当资料中相同观察值较多或变量值为频数表资料时,宜用加权法,其计算公式为

式中:∑flgx为各变量值的对数与相应频数乘积之总和;∑f为频数的总和。
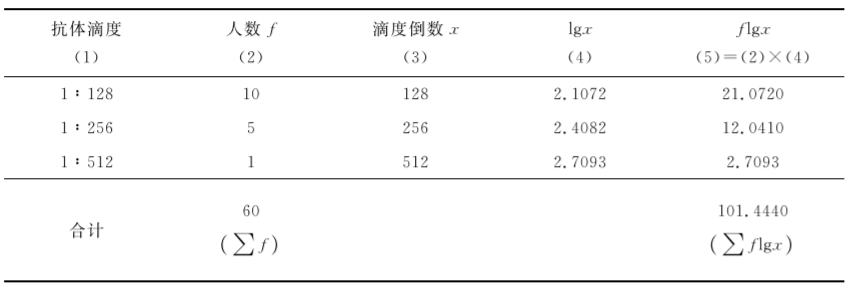
[例7.4]60名儿童接种某种疫苗后一个月,测定其血中抗体滴度,资料见表74,求该疫苗的平均抗体滴度。
将表7-4相应数值代入公式(75)中,得到
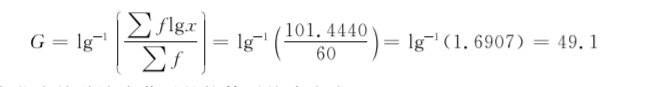
则60名儿童接种该疫苗后的抗体平均滴度为1∶49.1。
表7-4 60例抗体平均滴度的加权法计算

(三) 中位数
中位数(median)是将一组观察值从小到大排列,位次居中的那个值。用符号M表示。
1. 适用资料 用中位数表示平均水平,不受资料分布的影响,应用广泛。具体常用于:①偏态分布资料;②频数分布类型不清楚的资料;③存在特大值或特小值等极端值的资料;④频数表资料一端或两端无界(无确切值)时(开口资料)。
2. 计算方法
(1) 直接法当n较小时,先将观察值按大小顺序排序,如n为奇数,中位数就是位居中央的数(公式76);如n为偶数,中位数就是位于中央的2个数相加再除以2(公式7-7)。
当n为奇数时计算公式为

当n为偶数时计算公式为


[例7.5]某地9例某传染病患者,其潜伏期(天)分别为5,4,2,6,15,8,9,11,3,求平均潜伏期。
先将变量值按从小到大的顺序排列:2,3,4,5,6,8,9,11,15。
本例,n=9,为奇数,按式(76)计算中位数,即
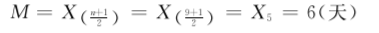
在有序数列中,第5位上的变量值为6,故其平均潜伏期为6天。
[例7.6]如上例资料在第20天又发生1例该传染病患者,其平均潜伏期又为多少?
先将变量值按从小到大的顺序排列:2,3,4,5,6,8,9,11,15,20。
本例,n=10,为偶数,按式(77)计算中位数,即

在有序数列中,第5位和第6位所对应的变量值6和8的均数为7,故其平均潜伏期为7天。
(2) 频数表法(frequency table method)当n较大时(n≥50)或变量值为频数表资料时,可用此法。计算公式为
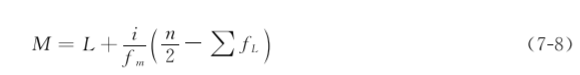
式中:L为中位数所在组段的下限,i为组距,fm为中位数所在组段的频数,n为总频数,∑fL为小于L各组段的累计频数。
[例7.7]测得某地120名健康成年男子尿汞值,其频数表见表75,求平均数。
表7-5 120名健康成年男子尿汞值(μg/L)频数表及其中位数
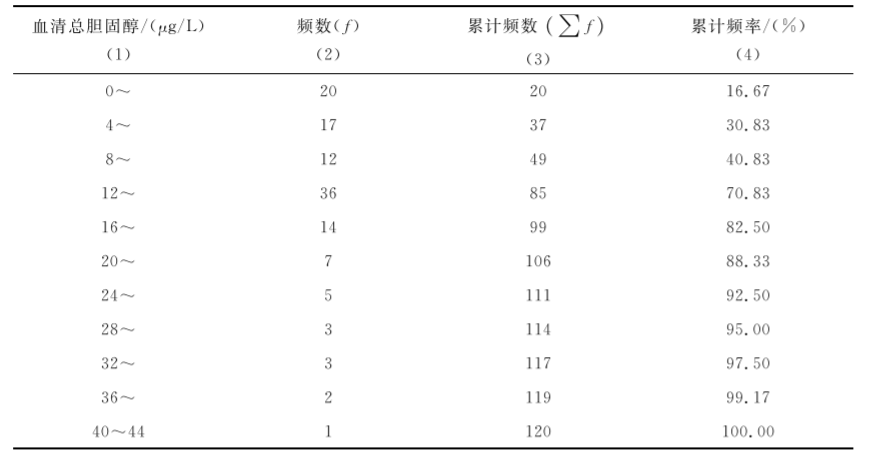
中位数计算表是在频数表基础上加第(3)列累计频数和第(4)列累计频率。累计频数的计算为上一组段的累计频数加上本组段的频数,如本例:0~组段累计频数为20;4~组段累计频数为20+17=37;8~组段累计频数为37+12=49。累计频率为累计频数除以总频数乘以100%。中位数计算表的组距通常是等组距,也可以是不等组距,因为中位数计算公式只涉及中位数所在组段的组距,而与其余各组段无关。本例首先从累计频率列找到包含50.0%的组段,可知在70.83%处,因此可以判断中位数落在12~组段,故L=12,i=4,fm=36,n=120,∑fL=49。代入公式(78),得到
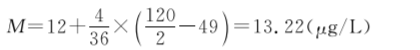
即该地120名正常人尿汞值的中位数为13.22 μg/L。
中位数虽然适用范围广泛,稳定性好,但精确度较低,缺少进一步统计处理的方法。实际工作中能用均数或几何均数描述其集中趋势的,可优先考虑。
附:百分位数
1. 百分位数的概念 中位数描述的是一组观察值的中心位置,当需要了解数据分布的其他位置时,需要用百分位数。百分位数是一种位置指标,是指将n个观察值从小到大排序,再把它分成100等份,对应于x/100位的数值即为第x百分位数。常用Px表示。中位数实际上是第50百分位数,M=P50。
2. 百分位数的用途
(1) 用于描述一组偏态分布资料在某百分位置上的水平。
(2) 制定偏态分布资料的医学参考值范围。
3. 计算方法(https://www.xing528.com)
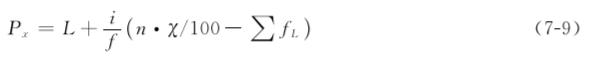
式中:Px为第x百分位数;L为Px所在组的下限;i为Px所在组的组距;f为Px所在组的频数;n为总频数;∑fL为小于L各组段的累计频数。
下面以[例7.7]中的P25、P75为例进行讲解,还可以计算P5、P95、P90等任意百分位数。
计算P25,先要判断P25所在的组段,在表75中,P25落在“4~”组段,则L=4,i=4,f=17,∑fL=20,将这些数据代入公式(7-9)中得到

同样,P75落在“16~”组段,则L=16,i=4,f=14,∑fL=85,代入公式(7-9)得:
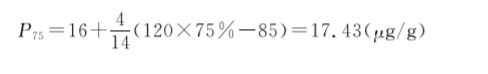
三、描述离散趋势的指标
描述一组数据的分布特征,只有集中趋势指标是不够的,还需要描述其离散趋势的指标。
[例7.8]假设有三组4岁男童的体重(kg)数据如下,试描述其数据特征。
甲组:2830323436
乙组:2729323537
丙组:2831323336
这三组数据的集中趋势相同,均数和中位数都为32 kg。但这三组数据的分布特征却不尽相同,也就是它们之间参差不齐的程度(变异程度)不同,或者说三组的离散程度不同。
离散趋势是指一组同质变量值之间参差不齐的程度,其描述指标又称变异指标,主要有全距、四分位数间距、方差、标准差及变异系数等。
(一) 全距
全距(range)又称极差,用符号R表示,是一组变量值中最大值与最小值的差值。反映一组变量值的变异范围。极差大,说明离散程度大;反之,说明离散程度小。
R甲=36-28=8(kg)R乙=37-27=10(kg)R丙=36-28=8(kg)
在例7.8中,乙组的极差比甲组和丙组的极差大,说明乙组的数据较为分散,离散程度较大,甲组和丙组的数据较为集中,离散程度较小。用极差来表示数据的离散程度,好处是计算方便,简单明了,容易理解,对变量值的各种分布资料都适用,因此应用广泛。但它只考虑了资料两端的数值,不能反映组内其他数据的变异程度,因而资料内部所蕴藏的信息不能被充分利用;易受个别特大或特小数值的影响,结果不稳定。比如甲组和丙组的极差虽一样,但它们的变异程度却不尽相同,因此用极差表示变异程度并不理想。
(二) 四分位数间距
四分位数间距(quartile interval)是上四分位数QU(即P75)与下四位数QL(即P25)之差,其间包括全部观察值的一半,用Q表示。它和极差类似,数值越大,说明变异越大;反之,说明变异越小。四分位数间距比极差稳定,但仍未考虑到每个观察值的变异程度。它适用于偏态分布资料,特别是分布末端无确定数据不能计算全距、方差和标准差的资料。
(三) 方差
为了全面考虑到每一个变量值对变异程度的影响,有人设计用每一个变量值与均数之差的总和,即∑(x-x),简称离均差总和来表示变异程度,但对于对称分布的资料尤其是正态分布的资料,正负数相抵消,离均差总和等于0,这与客观实际情况不符,因此,离均差总和不能表示变异程度的大小。为了避免正负数相抵消的问题,把每个(x-x)平方后再相加,即∑(x-x)2,简称离均差平方和。但是离均差平方和的大小除了与变异程度大小有关外,还与变量值的个数有关。变量值的个数越多,则∑(x-x)2就越大,这同样与客观实际情况不符,所以取其平均数,得到一个指标叫方差(variance),用s2(样本方差)或σ2(总体方差)表示,即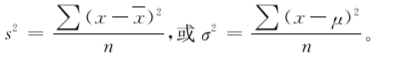
数理统计学研究结果,用样本资料算得的方差往往比总体方差偏小,即∑(x-x)2n<∑(x-μ)2n。为了得到总体方差的估计值,可将样本方差分母中变量值个数n减去1,即

式(710)中,n-1称为自由度(degree of freedom)。计算甲、乙、丙三组数据的方差分别为s2甲=10,s2乙=17,s2丙=8.5,由此可见,甲组和丙组数据虽然极差相同,但方差却不同,甲组较丙组大,这说明方差克服了极差只考虑两端数据的缺点。方差愈小,说明变量值的变异程度愈小;方差愈大,说明变异程度愈大。
什么是自由度
(四) 标准差
方差虽然全面考虑了一组变量值中的每一个数据,但它将变量值的单位也进行了平方,如体重原来的单位是kg,而方差的单位是kg2,这给该指标的应用带来极大不便。在统计分析中为了方便,通常将方差取平方根,还原成原来的单位,这就得到一个新的指标——标准差(standard deviation),标准差是最常用的描述对称分布资料尤其是正态分布资料变异程度的指标。以符号s(样本)或σ(总体)表示。样本标准差的计算公式是
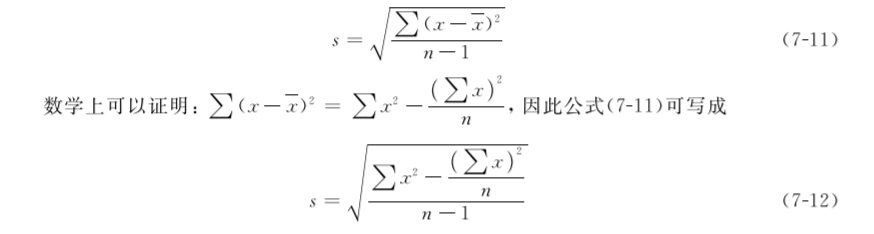
这个公式使离均差平方和的计算不必先求均数,可直接应用原始数据,运算更为方便。
1. 标准差的计算方法
(1) 直接法对于小样本资料,可直接代入公式(712)中求标准差。
[例7.9]求数据1、2、3、4、5、6的标准差。
将n=6,∑x=1+2+3+4+5+6=21,∑x2=12+22+32+42+52+62=91,代入公式(71-2)中得到
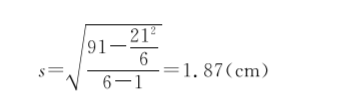
(2) 加权法与加权法计算均数一样,对于大样本资料可先将资料进行分组制成频数表,再用加权法计算标准差。加权法计算标准差的公式为
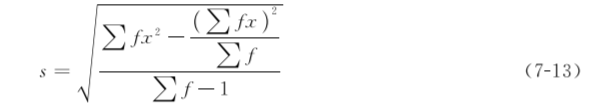
式(713)中符号的意义与加权法求均数的公式(72)相同。
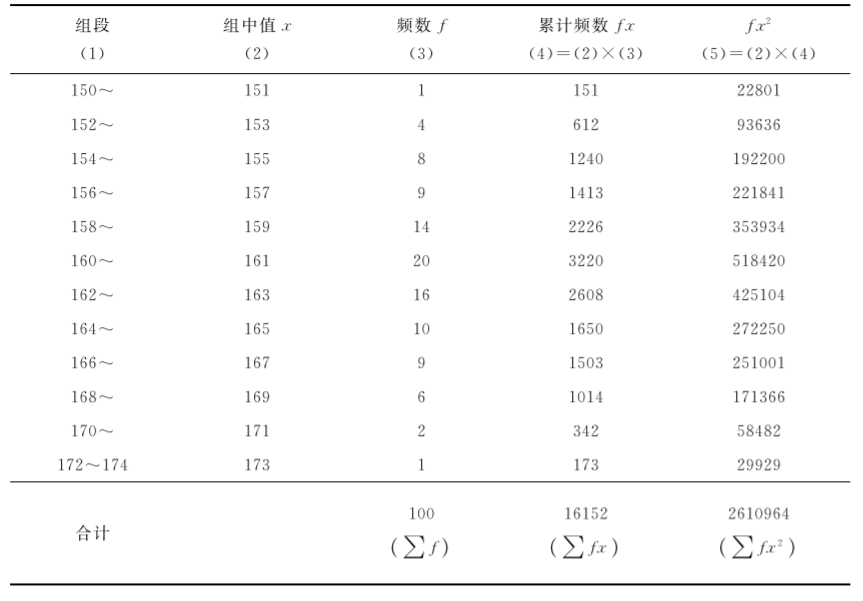
[例7.10]求[例7.1]资料的标准差。
将表76中的∑f=100,∑fx=16152,∑fx2=2610964,代入公式(713)中得到

表7-6某地2015年100名健康女大学生身高(cm)标准差的加权法计算
2. 标准差的用途 标准差用途广泛,常用于:①表示一组变量值的变异程度。两组或多组变量值比较,标准差较大的那一组,说明变量值的变异程度较大,均数的代表性较差;而标准差较小的那一组,表示变量值的变异程度较小,均数的代表性较好。前提条件是:单位相同、均数相等或相近。②用于计算变异系数。③用于计算标准误。④结合均数,估计频数分布情况。⑤结合均数,制定医学参考值范围。
(五) 变异系数
标准差反映两组或多组数据的变异程度要求单位相同、均数相等或相近,当两组或多组变量值的单位不同,或均数相差较大时,不能直接用标准差比较其变异程度的大小,而应该用变异系数(coefficient of variability,CV)。变异系数又称离散系数,是标准差与均数的比值,常用百分数表示。因其没有单位,更便于单位不同的资料间的比较。
计算公式为:

式中:CV为变异系数;s为标准差;x为均数。变异系数愈小,说明一组变量值的变异程度愈小;变异系数愈大,说明变异程度愈大。
[例7.11]2015年某地9岁男孩身高的均数为135.40 cm,标准差为5.08 cm;体重均数为32.46 kg,标准差为2.61 kg。试比较身高与体重的变异程度。
因身高和体重的单位不同,故不能直接用标准差比较,而应计算其变异系数。

即该地9岁男孩体重间的变异程度比身高间的变异程度大。
四、正态分布及其应用
(一) 正态分布的概念
正态分布(normal distribution)又称Gauss分布,是计量资料最常见的分布类型。医学和生物学中许多资料如健康人群的红细胞数、血红蛋白含量、血清总胆固醇值,同年龄同性别儿童的身高、体重、胸围等都符合正态分布。
什么是正态分布?我们先将表72的频数表资料,绘制成图71的直方图,可以得到一个中间高(靠近均数处频数多),两边低(远离均数处频数少),且左右对称的图形。可以设想,如果将观察人数逐渐增多,组段不断分细,图中直条将逐渐变窄,其顶端将逐渐接近于一条光滑的曲线。如图73所示,(a)、(b)、(c)为样本例数不断增大时的样本的频率分布。(c)为光滑连续曲线,表示样本所属总体的理论概率分布,该曲线两头低中间高,略呈钟形,左右对称,在数学上称为正态分布曲线。若指标x的频率曲线对应于数学上的正态分布曲线,则认为该指标服从正态分布。
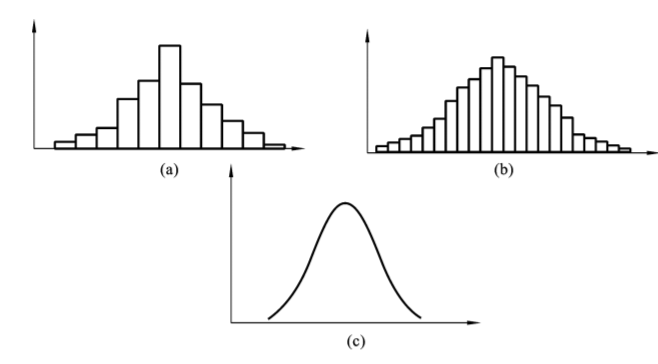
图7-3 正态曲线示意图
正态分布的函数式为
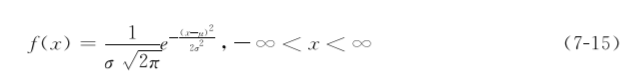
若指标x的频率曲线对应于数学上的正态分布曲线,则称x服从正态分布,x为正态变量,μ为随机变量x的总体均数,σ为总体标准差,μ和σ是正态分布的两个参数;π为圆周率,即3.14159;e为自然对数的底,即2.71828。π和e均为常量,仅x为变量。若x服从均数为μ,方差为σ2的正态分布,则简记为X~N(μ,σ2)。
已知μ和σ,就能按公式(715)绘出正态曲线的图形。
(二) 标准正态分布和u变换
1. 标准正态分布 对于由两个参数确定的正态分布,不同的变量有不同的分布曲线。实际工作中为了应用方便,将均数为0,方差为1的正态分布称为标准正态分布(standard normal distribution),简记为u~N(0,1)。可将一般正态分布的曲线作标准化变换(u变换)变为标准正态分布。
2. u变换 对任何服从正态分布N(μ,σ2)的随机变量x作如下u变换,都可变换成均数为0,方差为1的标准正态分布。

标准正态分布的密度函数为φ(u):

这一变换并不影响正态分布的性质,却为实际应用带来很大方便。如图74所示,研究者可先了解标准正态分布的规律,再推论到一般正态分布就很容易了。如在计算正态曲线下的面积分布时,往往通过u变换借助标准正态分布而求得。
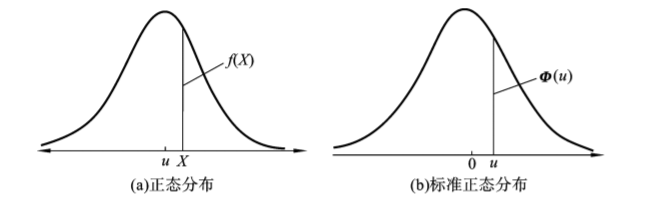
图7-4 一般正态分布变换成标准正态分布示意图
(三) 正态分布(曲线)的特征
1. 一个高峰 正态曲线的高峰位于中间均数处,以均数为中心。
2. 左右对称 正态曲线以均数为中心,左右对称,曲线两端逐渐下降与横轴无限接近但永不相交。
3. 两个参数 正态分布有两个重要参数,即均数μ和标准差σ,可记作N(μ,σ2)。均数μ决定正态曲线的中心位置;标准差σ决定正态曲线的形状(陡峭或扁平程度)。σ越小,曲线越陡峭;σ越大,曲线越扁平。
4. 正态分布曲线下面积的分布 有一定规律由于频率的总和等于100%或1,故横轴上曲线下的总面积等于100%或1。以均数为中心,左右相同范围内的面积相等。为了应用方便,统计学家编制了标准正态分布曲线下从-∞到u的面积表(附录C)。这里列出几个常用的特殊的面积分布区间(表7-7和图7-5)。
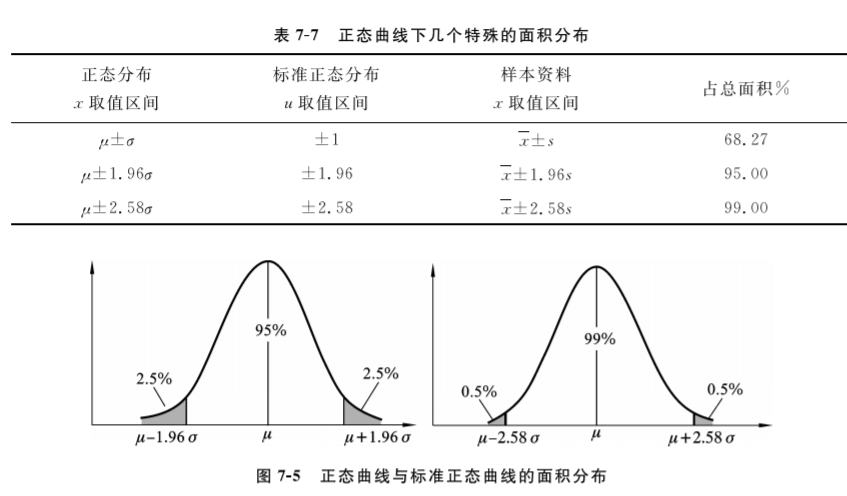
对频数分布呈正态或近似正态分布的资料,只要求得平均数和标准差,即可就频数分布做出概括和估计。
查附录C应注意:①曲线下横轴上的总面积为100%或1。②表中曲线下面积为-∞到u的左侧累计面积;③当已知μ、σ和x时,先按式(716)求得u值,再查附录C就可得到不同区间曲线下的面积;④当μ、σ未知且样本含量n足够大时,可用样本均数x和标准差s分别代替μ和σ,按u=x-xs式求得u值,再查附录C;⑤曲线下对称于0的区间面积相等,如区间(-∞,-1.96)与区间(1.96,∞)的面积相等,因而附录C只列出-∞到u的面积值。
(四) 正态分布的应用
人体的许多生理、生化指标均符合正态分布,所以正态分布在医学领域中应用广泛。对一些呈偏态分布的资料,经过适当的变量变换(如对数、平方根、倒数变换等)后服从正态分布,也可按正态分布理论处理。
1. 估计正态分布资料的频数分布
[例7.12]求例7.1中100名健康女大学生身高在154 cm以下的人数,并分别求x±1s、x±1.96s、x±2.58s范围内人数占总人数的实际百分数,并与理论百分数比较。
本例,μ、σ未知但样本含量n较大,可用样本均数x和标准差s分别代替μ和σ来求u值。由于s=4.60 cm,x=161.5 cm,u=154-161.54.60=-1.63。查标准正态曲线下的面积(附录C),在表的左侧找到-1.6,表的上方找到0.03,两者相交处为0.0516,即身高在154 cm以下的人数占总人数的5.16%,也就是5人(5.16%×100=5.16≈5),而清点的实际人数为5人。其他计算结果见表78。从中可以看出实际分布与理论分布非常接近。
表7-8 100名健康女大学生身高的实际频数与理论频数分布比较

2. 制定医学参考值范围 医学参考值范围(reference ranges)是指绝大多数正常人的某项指标范围,即正常人的解剖、生理、生化指标及组织代谢产物含量等数据中大多数个体的取值所在的范围。习惯用该健康人群95%个体某项医学指标的取值范围作为该指标的医学参考值范围。制定医学参考值范围的方法有两种。
(1) 正态分布法 此法适用于正态或近似正态分布的资料,包括资料经过转换(如取对数)后呈正态分布或近似正态分布的资料。95%医学参考值范围可按下式制定。
双侧界值:x±1.96s (7-18)
单侧上界值:x+1.645s (7-19)
单侧下界值:x-1.645s (7-20)
[例7.13]求[例7.1]资料中健康女大学生身高的95%医学参考值范围。
由于x=161.52 cm,s=4.60 cm,n=100,身高指标过大过小均为异常,所以制定双侧范围。代入公式(718)得到
x±1.96s=161.52±1.96×4.60=161.52±9.02={152.5,170.5}(cm)。
即该地健康女大学生身高的95%医学参考值范围为152.5~170.5 cm。
(2) 百分位数法常用于偏态分布资料,详见前面所讲百分位数法的计算。
以95%医学参考值范围为例,双侧界值(即值过高过低都异常):(p2.5,p97.5);单侧上限界值(过高异常,如血铅含量):p95;单侧下限界值(过低异常,如肺活量):p5。
3. 正态分布是许多统计方法应用的理论基础 后面将要学到的t检验、u检验等都是在正态分布的基础上推导出来的,都要求资料服从正态分布。此外,对于非正态分布资料,也可以做变量变换使转换后的资料近似符合正态分布,也可以按正态分布原理进行统计处理。
4. 质量控制 为了控制实验研究中检测误差,保证研究质量,常以x±2s作为上、下警戒值,以x±3s作为上、下控制值。式中2s和3s是1.96s和2.58s的近似值。提醒研究者对比较极端的检测结果要引起注意、慎重处理。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。